Imersão:
Econometria vs. Inteligência Artificial na Previsão Macroeconômica
Início em 22 de outubro, 20h
Imersão:
Econometria vs. Inteligência Artificial na Previsão Macroeconômica
Início em 22 de outubro, 20h
Quem está vencendo: econometria ou inteligência artificial
Em uma Imersão inédita no Brasil e totalmente mão na massa, você vai aprender na prática a comparar modelos estatísticos e econométricos clássicos com os principais algoritmos de IA para a tarefa de previsão de séries temporais.
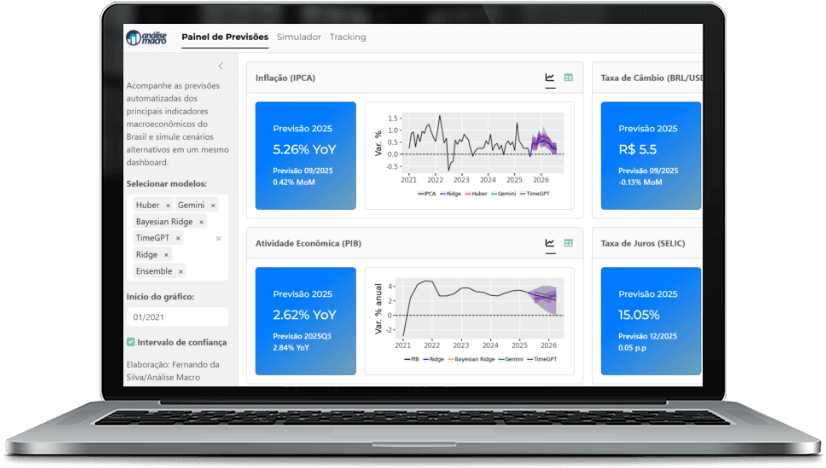
Descubra na prática quem está vencendo essa batalha construindo do zero um painel de previsões macroeconômicas em Python.
Quem está vencendo: econometria ou inteligência artificial
Em apenas 2 meses, você vai aprender — de forma prática e direta ao ponto — a colocar frente a frente modelos econométricos tradicionais e algoritmos modernos de IA. O resultado? Você mesmo vai comparar quem entrega as melhores previsões para PIB, inflação, juros e câmbio.
Você irá ganhar todos os instrumentos necessários para não apenas saber quem está vencendo essa verdadeira guerra, como vai poder acompanhar com uma visão privilegiada as próximas batalhas.
Datas e Estrutura da Imersão
Serão 9 encontros ao vivo, entre outubro e dezembro de 2025, para você ir do ZERO ao Deploy. Uma arena privilegiada para você conversar com outros players do mercado sobre o assunto mais quente do momento: como aplicar IA na sua operação. Todas as dúvidas que você tem sobre coleta, tratamento, análise, seleção de variáveis, treinamento e avaliação de modelos, construção de cenários, previsão fora da amostra e deploy em produção.
E se perder um dia, fique tranquilo: todos os encontros ficam gravados para você ver e rever quando quiser pelos próximos 12 meses.
Abaixo, o Programa completo da Imersão:
Dia 1 - 22/10
(de 20h às 22h)
No primeiro dia do evento, além de dar boas-vindas a todos, faremos um resumo detalhado da Imersão, de forma a construir o seu ambiente e tudo o que será necessário para rodar os códigos em python.
Além disso, começaremos a montar nossa base de dados com mais de 100 variáveis públicas e privadas, de modo a construir e rodar modelos estatísticos, econométricos e de IA para previsão macroeconômica.
Dia 2 - 29/10
(de 20h às 22h)
No segundo dia do evento, seguiremos tratando da coleta de dados. Veremos diversos desafios de coleta automática de dados de APIs das principais fontes de dados públicos do país, como IBGE, IPEAData e Banco Central do Brasil.
Serão descritas ainda informações gerais sobre os metadados de mais de 100 variáveis exploradas.
É o dia para discutir problemas e desafios comuns na coleta de dados como conexão de internet instável, fontes de dados instáveis, mudanças inesperadas na fonte de dados, uso de versões de funções ou bibliotecas com comportamentos inesperados.
Vamos mostrar como enfrentar e resolver esses desafios práticos ao longo da aula.
Ao final, o aluno terá aprendido a construir um script que coleta todos os dados discutidos com funções específicas em Python.
Dia 3 - 05/11
(de 20h às 22h)
Com a base de dados pronta, o objetivo será o tratamento. Por meio de análises sobre as características, padrões, comportamentos e relações entre as variáveis.
Diversos aspectos práticos surgem nessa etapa, como o tratamento de números índices, a existência de dados faltantes, como tratar problemas de sazonalidade, etc.
Além disso, será que precisamos de todas as variáveis coletadas? Muitas delas, afinal, são correlacionadas entre si, então pode ser necessário fazer uma seleção de quais variáveis realmente são importantes para o objetivo de previsão.
Mostraremos métodos simples para construir esse tipo de filtro.
Ao final, o aluno terá construído um script completo em Python que analisa os dados e selecionar variáveis relevantes para a implementação de um fluxo de modelagem preditiva.
Dia 4 - 12/11
(de 20h às 22h)
Na sequência da imersão, chega o momento de lidar com os modelos preditivos que irão fornecer os resultados que tanto queremos.
Para desenvolver modelos preditivos são necessários conhecimentos da área de aplicação, habilidades técnicas de programação, conhecimento de estatística, experiência em ciência de dados, dentre outros.
Portanto, a operacionalização de um modelo não é nada trivial, pois são diversos os procedimentos que um profissional da área precisa sempre ter no radar.
Mas se generalizarmos esses procedimentos em um fluxo de trabalho, a distância entre a idealização do modelo e sua implementação pode ser mais curta e menos árdua.
Tendo como objetivo prever a taxa de inflação medida pelo IPCA, implementaremos um fluxo prático e passo a passo, envolvendo a operação de mais de 18 tipos de modelos, como passeio aleatório, SARIMA, Ridge Regression, LASSO, Bayesiano Ridge, Huber Regression, SVM, AdaBoosting, Gemini AI, etc.
Serão explorados temas importantes envolvendo erro de previsão, horizontes de previsão, estratégia de modelagem envolvendo hiperparâmetros definidos via grid search e, então, implementação de validação cruzada com restauração e janela de treino crescente, com amostra inicial de 50% das observações.
Ao final, o aluno terá construído um script que implementa diversos modelos de previsão para diversos cenários/amostras de dados diferentes, visando encontrar aquele que se generaliza melhor para a previsão da inflação.
Dia 5 - 19/11
(de 20h às 22h)
Todos os modelos erram e este é o momento de diagnosticar dentre modelos preditivos aqueles que erram menos.
Questões relevantes como erro de previsão, métricas de acurácia, comportamento de resíduos e horizontes de previsão serão exploradas nesta etapa. Abordagens de diagnóstico numérico e visual dos modelos serão abordadas, ponderando desafios inerentes à escolha de modelos.
Ao final, o aluno terá construído um script que analisa os erros de previsão dos modelos de inflação, com o objetivo de escolher o que se adequa melhor em termos de acurácia.
Dia 6 - 26/11
(de 20h às 22h)
Para fechar a construção de modelos preditivos, chega o momento de sair da simulação com os dados históricos e, então, gerar previsão para o futuro.
Desafios relevantes como cenários em modelos multivariados, estratégias de cenarização diferentes para cada variável, intervalos de confiança e previsão pontual serão abordadas.
Ao final, o aluno terá construído um script que gera cenários para as variáveis previsoras, produz previsões para a inflação e visualiza os resultados em um gráfico.
Dia 7 - 03/12
(de 20h às 22h)
Com todos os scripts prontos para coleta, tratamento e modelagem, chega o momento do deploy, isto é, colocar o modelo em produção para que usuários externos possam ver a solução encontrada.
Começaremos a desmistificar diversas questões envolvendo a construção de dashboards interativos, bem como o uso de ferramentas que facilitam o desenvolvimento de aplicações robustas na web.
Serão apresentados todos os passos para instalações locais, bem como o uso de ferramentas como o shiny para construção de um dashboard interativo.
Dia 8 - 10/12
(de 20h às 22h)
Uma vez que tenhamos construído nosso painel macroeconômico, vamos automatizar tudo com Github Actions.
Afinal, do que adianta construir pipelines em python se todo mês você precisa atualizar novamente as variáveis explicativas para então gerar cenários para a variável de interesse?
Questões importantes sobre atualização e automatização serão tratadas nesse dia.
Dia 9 - 17/12
(de 20h às 22h)
Fecharemos a Imersão com uma Oficina prática em que os alunos poderão expor seus próprios trabalhos de automatização de pipelines em python, obtendo feedbacks da turma e dos instrutores.
Momento importante para construção de networking com colegas de profissão e analistas mais experientes em dados.
O que você vai aprender na prática
Coletar séries macroeconômicas de diferentes fontes públicas e privadas.
Aplicar técnicas de limpeza e tratamento de dados em Python.
Construir e comparar modelos econométricos (ARIMA, VAR, etc.) com modelos de machine learning e Inteligência Artificial.
Desenvolver cenários alternativos para variáveis-chave (PIB, inflação, juros, câmbio).
Colocar no ar um painel web que atualiza automaticamente os modelos e previsões.
Essa imersão é para mim?
Economistas
que querem ir além da econometria clássica e explorar o poder da Inteligência Artificial, se colocando à frente em um mercado cada vez mais competitivo.
Cientistas de dados
que desejam se aprofundar em modelagem macroeconômica aplicada.
Profissionais
de mercado financeiro e consultorias que precisam gerar cenários confiáveis em tempo recorde.
Estudantes
que querem construir um portfólio provocativo e inovador, unindo econometria e inteligência artificial.
Pré-requisitos
- Conhecimentos prévios em Python, principalmente com coleta e tratamento de dados
- Conhecimentos de econometria e séries temporais são importantes para o bom entendimento dos códigos, mas não são impeditivos
O futuro está acontecendo, vai ficar de fora?
Essa não é uma aula teórica. É um duelo prático: você vai ver, com seus próprios olhos e códigos, quem vence na previsão macro — a econometria ou a IA.
Uma imersão mão na massa, com programadores experientes, que vão te conduzir, linha a linha em python, como construir do ZERO modelos clássicos e modelos de IA para construir previsões acuradas de variáveis macroeconômicas.
Uma experiência inédita no país.


Bônus exclusivos
- Todos os códigos em Python prontos para adaptação
- Material complementar com papers e referências de econometria e inteligência artificial
- Livro Digital Inteligência Artificial para Economistas
- Curso Previsão Macroeconômica usando Python e IA
Por que agora?
O mercado está dividido: de um lado, profissionais defendendo a tradição da econometria. Do outro, equipes apostando na força bruta da inteligência artificial. Quem não domina as duas abordagens e não sabe compará-las na prática, está ficando para trás. É a sua chance de ver programadores seniores colocando a mão na massa com o que há de mais inovador na fronteira entre as duas abordagens.
Investimento
R$ 997,00 à vista
ou em 10x de R$ 99,70 no cartão de crédito
(lote de lançamento)
- Início ao vivo em 22/10
- 100% prático, com replay e código disponível.
- gravação e material ficam disponíveis para você rever quando quiser.
- Garantia: 30 dias incondicionais
Quem vai te conduzir na Imersão

Vítor Wilher - Mestre em Economia e Cientista-Chefe da Análise Macro
Especialista em ciência de dados. Dá aulas e presta consultoria há 7 anos na área de dados, já tendo ajudado milhares de alunos no Brasil a darem o primeiro passo em análise de dados envolvendo R e Python.

Fernando da Silva - Bacharel em Economia e Cientista de Dados
Especializado em economia e finanças. Trabalha com modelagem e previsão de séries temporais, análise e visualização de dados e automatização de relatórios e dashboards.
Perguntas frequentes
Preciso conhecer IA avançada?
Não. Você aprenderá os blocos necessários durante a imersão.
Vou sair com painel (dashboard) funcionando?
Sim. Você terá um Colab reproduzível com tudo o que é necessário.
Funciona para qualquer variável?
A arquitetura é geral. Mostramos como adaptar para IPCA, Selic, câmbio e atividade.
Posso usar sem GPU?
Sim. O foco é em ferramentas leves e LLMs acessíveis; o pipeline roda no Colab padrão.
Posso aplicar na minha empresa?
Sim. O template facilita a adaptação para dados internos e automações recorrentes.
comercial@analisemacro.com.br – Rua Visconde de Pirajá, 414, Sala 718
Ipanema, Rio de Janeiro – RJ – CEP: 22410-002
