As diferentes formas de avaliar o erro de um modelo de previsão
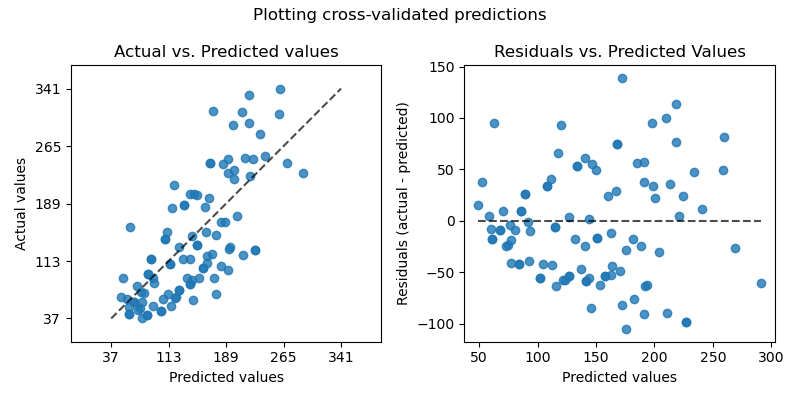
Existem tantas siglas para métricas de desempenho de modelos preditivos que é fácil se perder na sopa de letrinhas. Neste artigo, fornecemos uma visão geral das principais métricas para avaliar e comparar modelos de regressão e classificação, usando exemplos com dados em Python.
Como construir uma base de dados para gerar previsões para a inflação medida pelo IPCA

Neste exercício, apresentamos as principais fontes de dados públicos utilizadas na macroeconomia e desenvolvemos uma rotina para coletar, tratar e disponibilizar (ETL) as variáveis para uso em modelos preditivos.
Como extrair e apresentar dados de Pedidos de Recuperação Judicial com Python
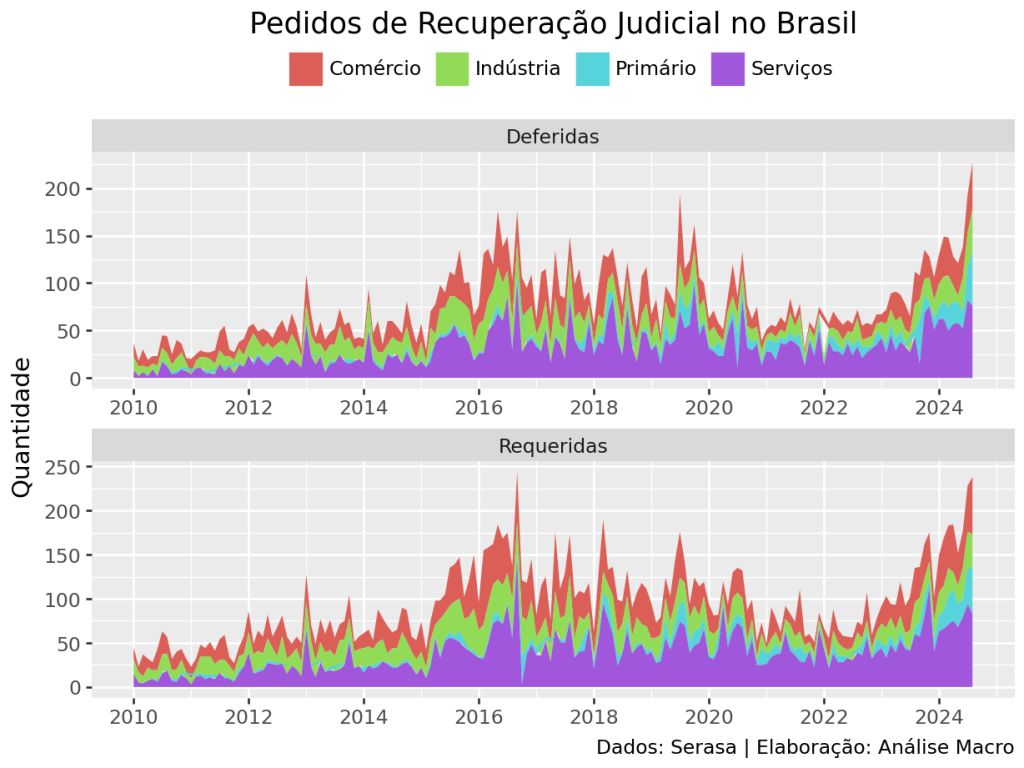
Os pedidos de RJ podem ser um termômetro para a atividade econômica do país. Usando dados do Serasa e a linguagem Python, podemos avaliar, a nível de setor, se há mais empresas no Brasil em apuros ou não.
Como coletar dados de conjuntura do setor externo com Python
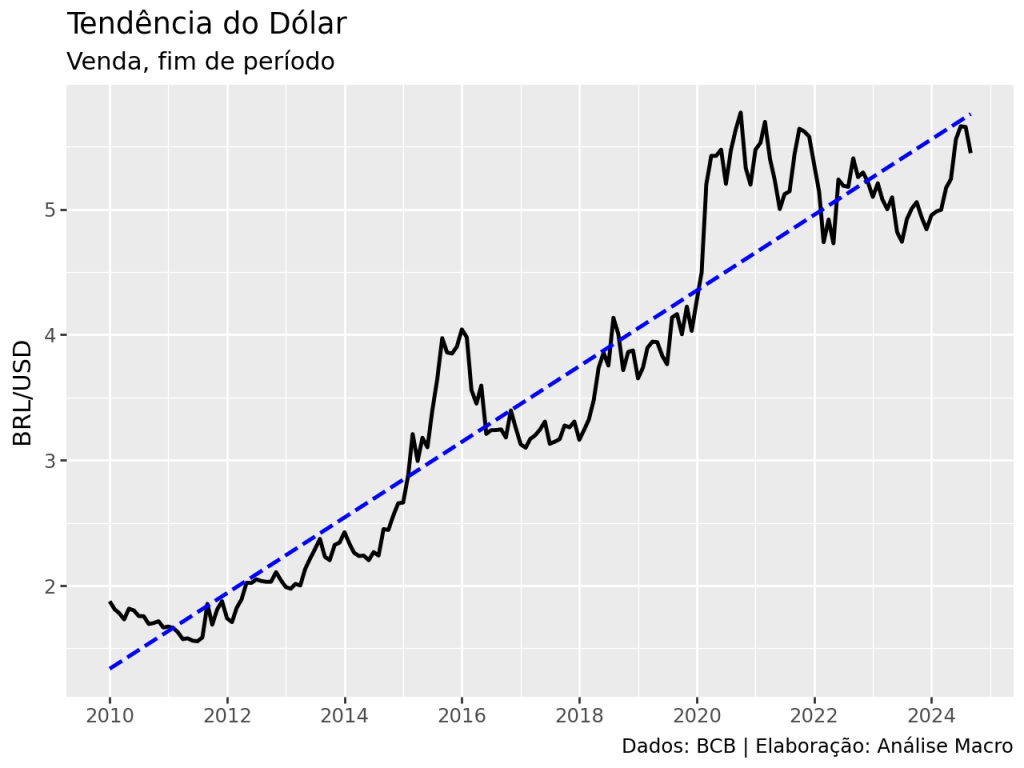
Toda e qualquer economia de mercado deve ter algum contato, menor ou maior, a depender de diversos fatores, com o resto do mundo. Convencionou-se, nesse contexto, a designar como setor externo a área da análise de conjuntura onde são compiladas e analisadas as transações comerciais e financeiras que são feitas entre residentes e não residentes de um determinado país. Neste artigo mostramos rotinas simples para analisar dados de taxa de câmbio e do balanço de pagamentos usando Python.
Como coletar dados de CNPJ da Receita Federal com Python
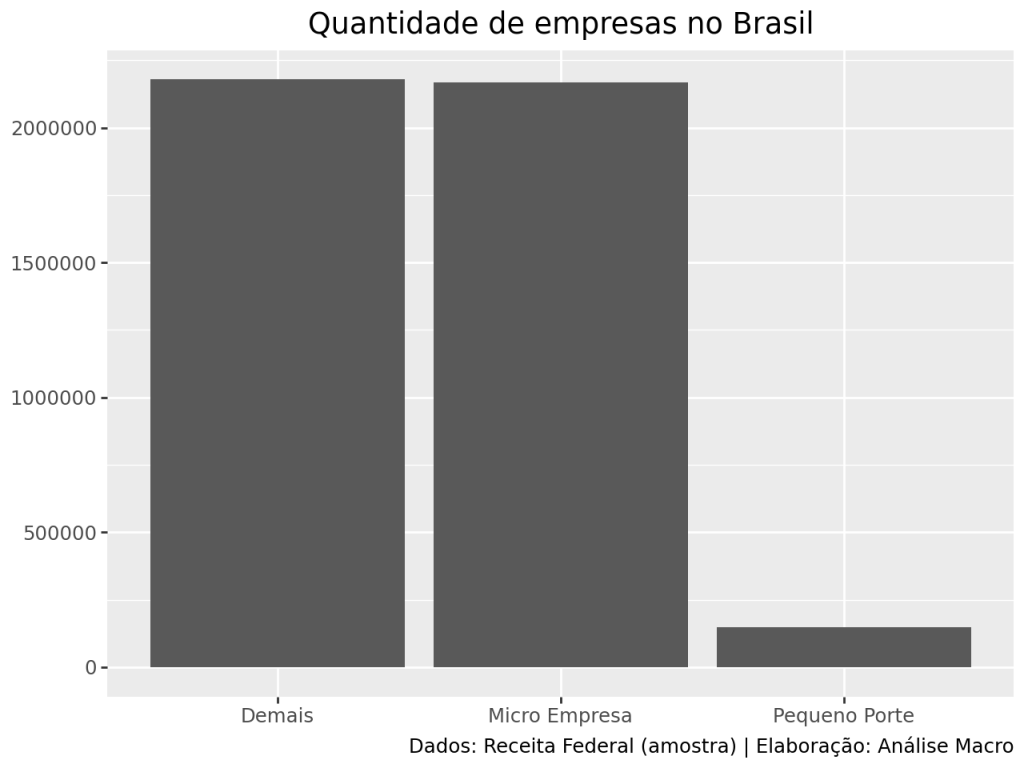
Obter dados de empresas, estabelecimentos, CNAES, sócios e muito mais de forma aumatizada é possível com ferramentas como o Python. Neste exercício, mostramos como explorar estes dados da Receita Federal do Brasil.
