Uma das questões mais delicadas ao longo de 2020 era evitar que (1) a população vulnerável ficasse desamparada na maior crise sanitária dos últimos 100 anos e (2) as micro e pequenas empresas falissem ou solicitassem recuperação judicial. Evitar que (2) ocorresse implicava em irrigar o mercado de crédito com dinheiro subsidiado, mitigando assim o risco de crédito associado a esse tipo de empréstimo.
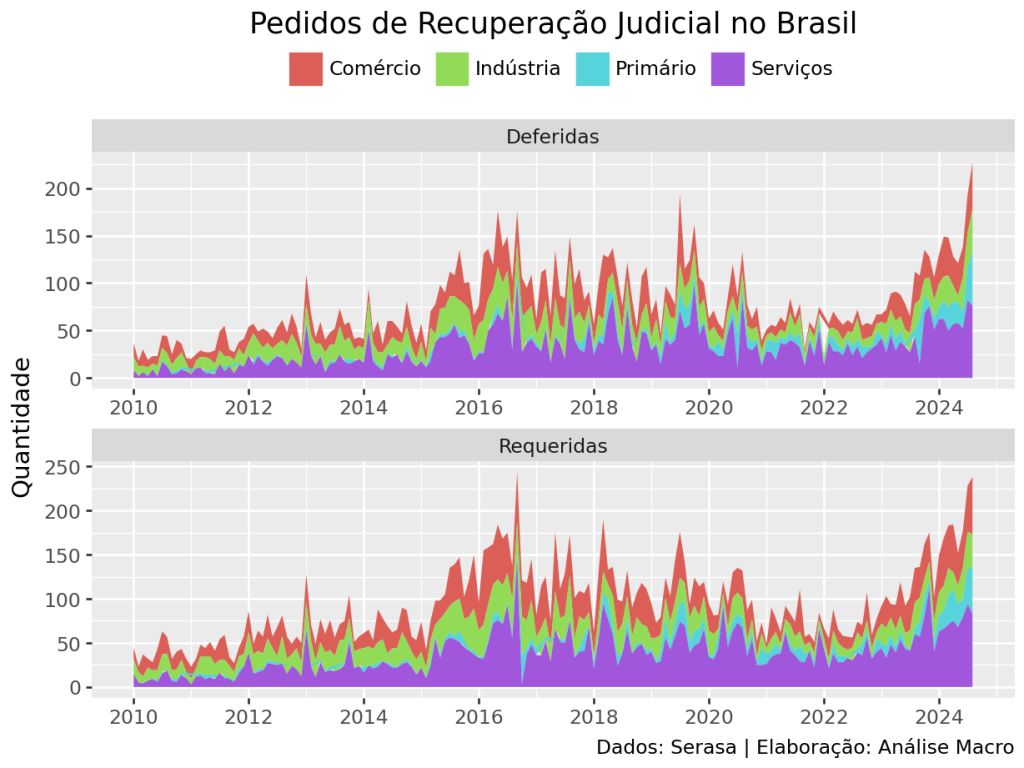
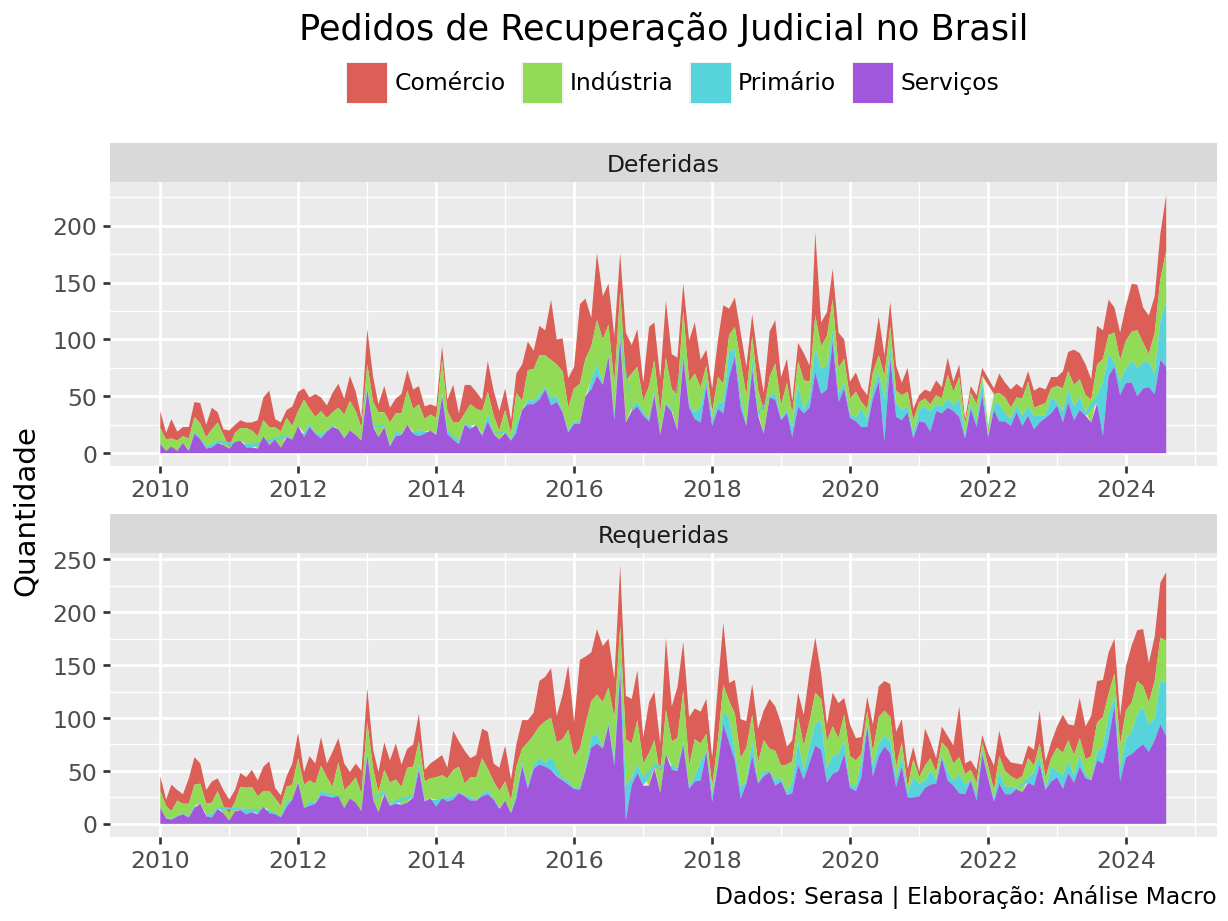
Empresas falidas ou em recuperação judicial têm impacto sobre o PIB Potencial da economia, conforme exercício que fizemos na Análise Macro. Quanto maior o número de empresas nessa condição, menor a capacidade de produção do país, logo menor será o PIB Potencial.
Isso dito, cabe nos perguntar: houve um aumento de falências e recuperações judiciais nos anos recentes?
Para responder essa pergunta, podemos recorrer aos dados de Pedidos de Recuperação Judicial do Serasa. Os arquivos estão disponíveis nos respectivos sites dessas instituições em formato Excel.
Coleta de dados
Primeiro coletamos a planilha Excel diretamente da fonte Serasa, usando Python:
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
data Requeridas - Comércio ... Deferidas - Total Concedidas - Total
0 1991-02-01 0.0 ... 0.0 0.0
1 1991-03-01 0.0 ... 0.0 0.0
2 1991-04-01 0.0 ... 0.0 0.0
3 1991-05-01 0.0 ... 0.0 0.0
4 1991-06-01 0.0 ... 0.0 0.0
.. ... ... ... ... ...
402 2024-08-01 65.0 ... 227.0 46.0
403 2024-09-01 NaN ... NaN NaN
404 2024-10-01 NaN ... NaN NaN
405 2024-11-01 NaN ... NaN NaN
406 2024-12-01 NaN ... NaN NaN
[407 rows x 12 columns]Tratamento de dados
Em seguida, realizamos alguns tratamentos de dados para que a tabela fique pronta para análises. Fazemos isso usando a biblioteca pandas:
data valor tipo setor
227 2010-01-01 14.0 Requeridas Comércio
228 2010-02-01 6.0 Requeridas Comércio
229 2010-03-01 25.0 Requeridas Comércio
230 2010-04-01 10.0 Requeridas Comércio
231 2010-05-01 9.0 Requeridas Comércio
... ... ... ... ...
4472 2024-08-01 46.0 Concedidas Total
4473 2024-09-01 NaN Concedidas Total
4474 2024-10-01 NaN Concedidas Total
4475 2024-11-01 NaN Concedidas Total
4476 2024-12-01 NaN Concedidas Total
[1980 rows x 4 columns]Análise de dados
Por fim, geramos uma análise temporal do número de pedidos de recuperação judicial por setores da economia, usando a biblioteca plotnine:
Conclusão
Os pedidos de RJ podem ser um termômetro para a atividade econômica do país. Usando dados do Serasa e a linguagem Python, podemos avaliar, a nível de setor, se há mais empresas no Brasil em apuros ou não.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

