Como Construir um Monitor de Política Monetária Automatizado com Python?
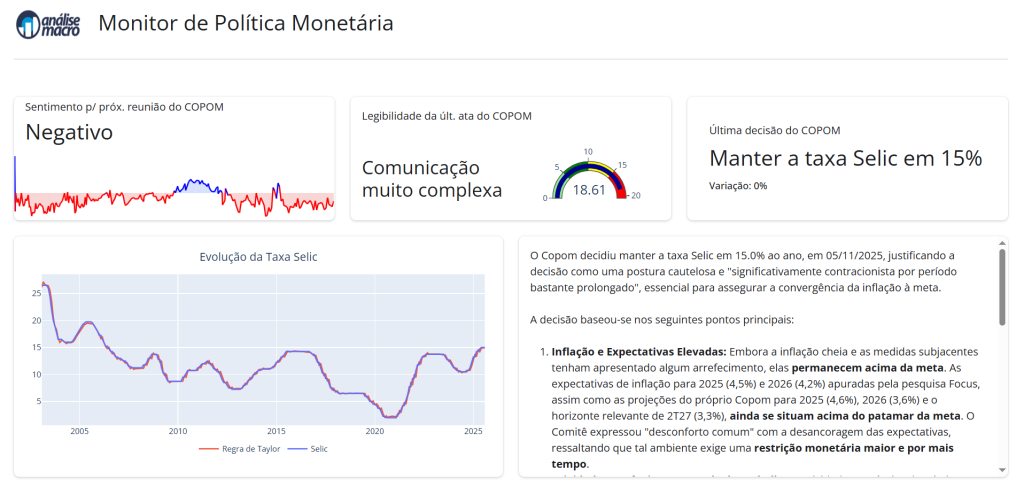
Descubra como transformar dados do Banco Central em inteligência de mercado com um Monitor de Política Monetária Automatizado. Neste artigo, exploramos o desenvolvimento de uma solução híbrida (Python + R) que integra análise de sentimento das atas do COPOM, cálculo da Regra de Taylor e monitoramento da taxa Selic. Aprenda a estruturar pipelines ETL eficientes e a visualizar insights econômicos em tempo real através de um dashboard interativo criado com Shiny, elevando o nível das suas decisões de investimento.
Estamos em pleno emprego no mercado de trabalho?
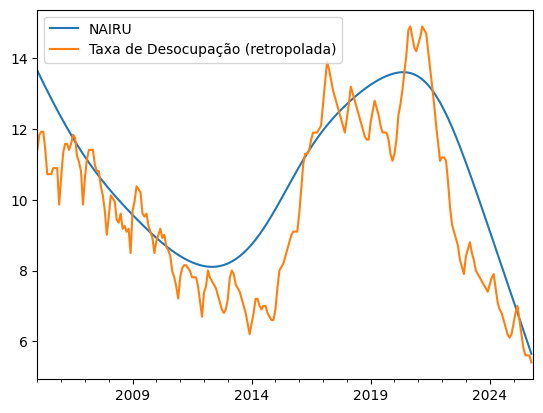
Este artigo investiga se o mercado de trabalho brasileiro atingiu o nível de pleno emprego, utilizando uma estimativa da NAIRU (Non-Accelerating Inflation Rate of Unemployment) baseada na metodologia de Ball e Mankiw (1997). Através de uma modelagem em Python que unifica dados históricos da PME e PNAD Contínua com as expectativas do Boletim Focus, comparamos a taxa de desocupação corrente com a taxa neutra estrutural. A análise visual e quantitativa sugere o fechamento do hiato de desemprego, sinalizando potenciais pressões inflacionárias. O texto detalha o tratamento de dados, a aplicação do Filtro Hodrick-Prescott e discute as vantagens e limitações da metodologia econométrica adotada.
Como se comportou a inflação de serviços no Brasil nos últimos anos?

Uma análise econométrica da inflação de serviços no Brasil comparando os cenários de 2014 e 2025. Utilizando uma Curva de Phillips própria e estimativas da NAIRU via filtro HP, investigamos se o atual desemprego nas mínimas históricas repete os riscos do passado. Entenda como as expectativas de inflação e o hiato do desemprego explicam o comportamento mais benigno dos preços atuais em relação à década anterior.
Qual o hiato do produto no Brasil?

Entender o hiato do produto é fundamental para avaliar o ritmo da economia e as pressões inflacionárias no Brasil. Neste artigo, mostramos como estimar essa variável não observável a partir dos dados do PIB, explorando diferentes metodologias — de regressões simples a modelos estruturais — e discutindo as limitações e incertezas que cercam cada abordagem.
Como medir a comunicação do Banco Central?
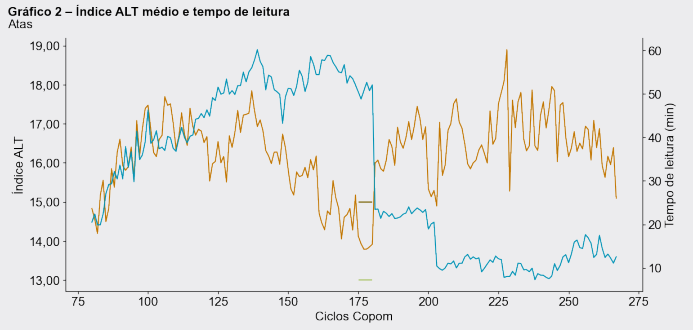
Descubra como o índice ALT transforma a linguagem do Banco Central em dados analisáveis, permitindo investigar como o tom das atas do COPOM varia conforme o cenário macroeconômico e as decisões de política monetária.
