Replicando um Indicador de Incerteza no Python (IIE-Br)
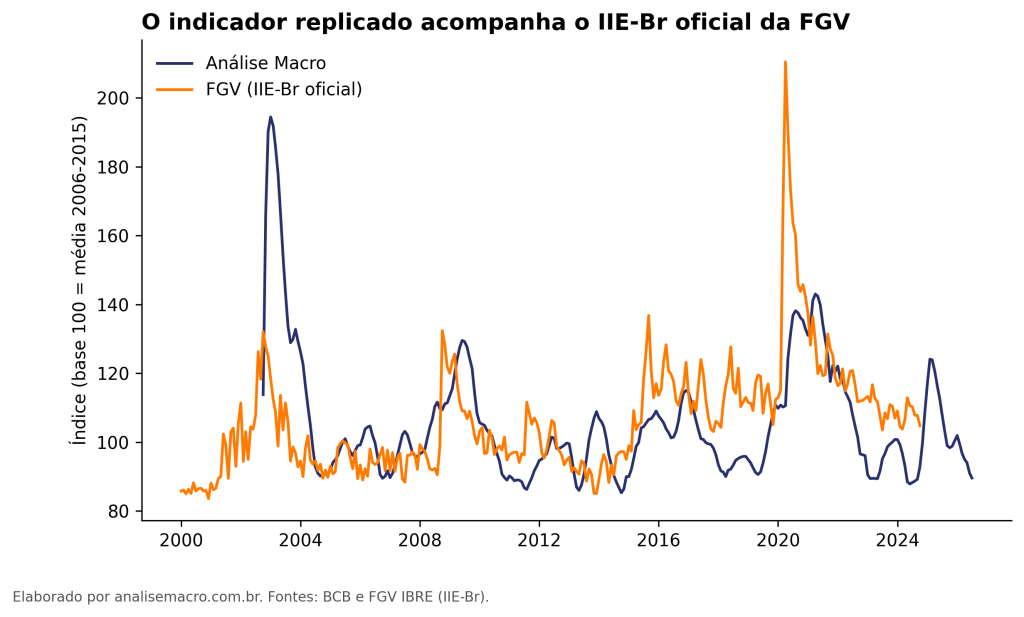
Como construir um indicador de incerteza da economia brasileira no Python, replicando a lógica do IIE-Br da FGV. O exercício usa as atas do COPOM como fonte textual e a dispersão das expectativas de mercado (IPCA, câmbio e Selic) do Banco Central, tudo com dados públicos. O resultado acompanha de perto o índice oficial da FGV nos grandes episódios de crise.
Repasse cambial no R: quanto um choque do câmbio afeta a inflação
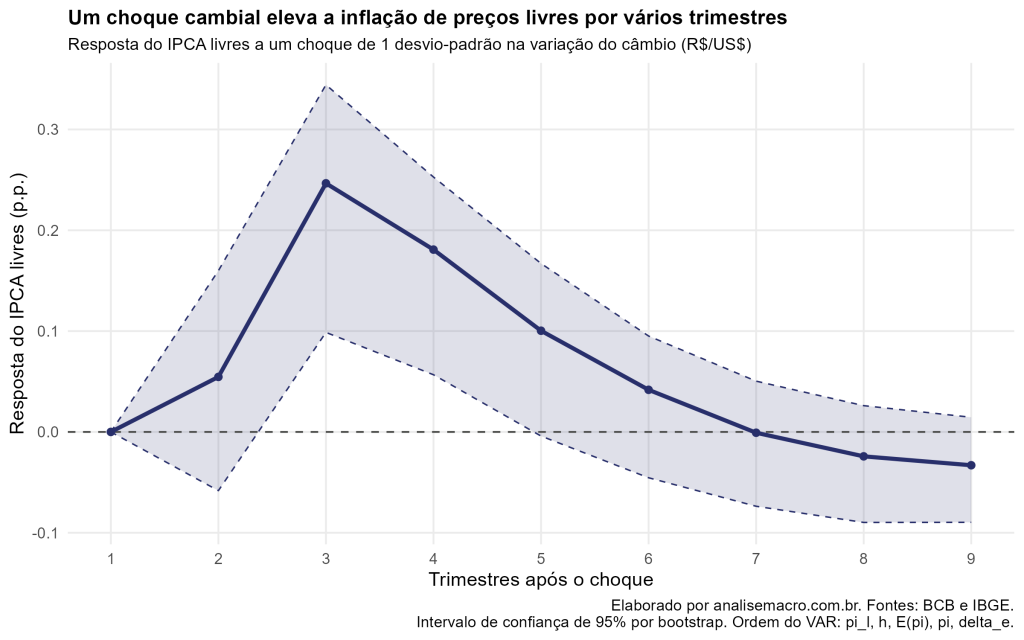
Quanto um choque do dólar move a inflação brasileira? Este tutorial mostra como medir o repasse cambial no R com um modelo VAR e funções impulso-resposta, usando dados públicos do Banco Central e do IBGE. O efeito atinge o pico por volta do terceiro trimestre e se dissipa em cerca de um ano.
Previsões do Boletim Focus em Anos Eleitorais
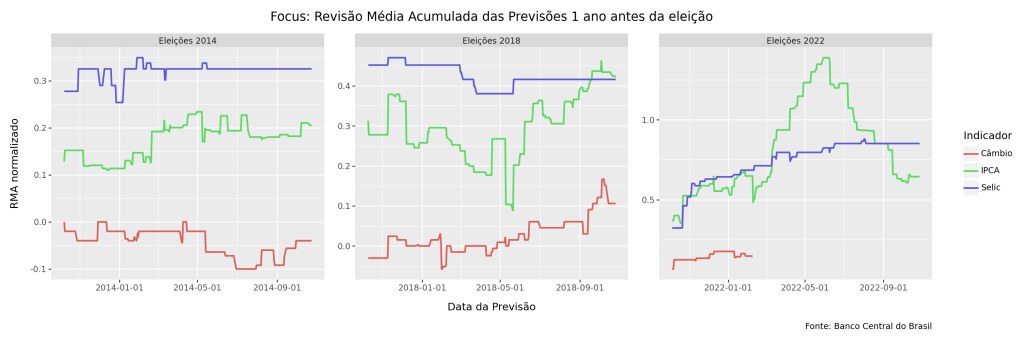
Eleições são momentos de incerteza, mas os dados do Boletim Focus mostram que nem toda incerteza é igual. Ao analisar as previsões de inflação, juros e câmbio nos anos que antecederam as eleições de 2014, 2018 e 2022, este post investiga como o mercado revisa cenários macroeconômicos ao longo do tempo.
Atualização de resultados dos modelos de inflação da AM
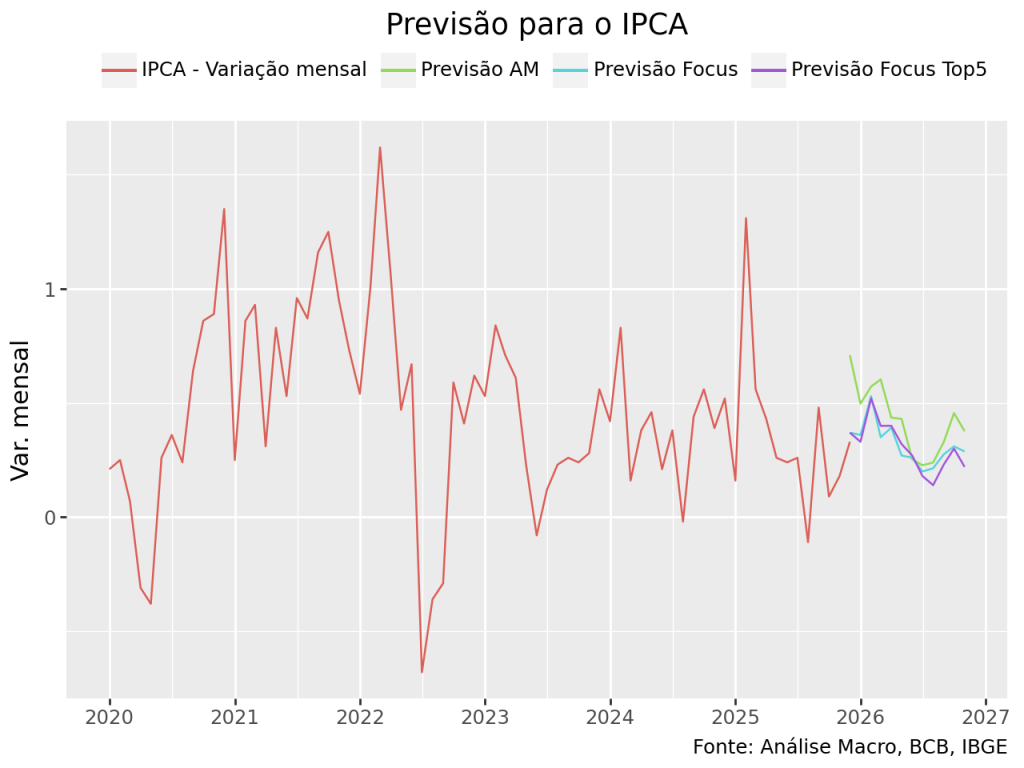
O IPCA fechou 2025 em 4.26%, ficando acima da meta de 3% ao ano, mas dentro do intevalo de tolerância de ±1,5 ponto percentual. O valor veio abaixo da previsão da Análise Macro, de 4.66%, e abaixo do previsto pelo Boletim Focus, de 4.30%.
Análise do Payroll norte-americano com Python
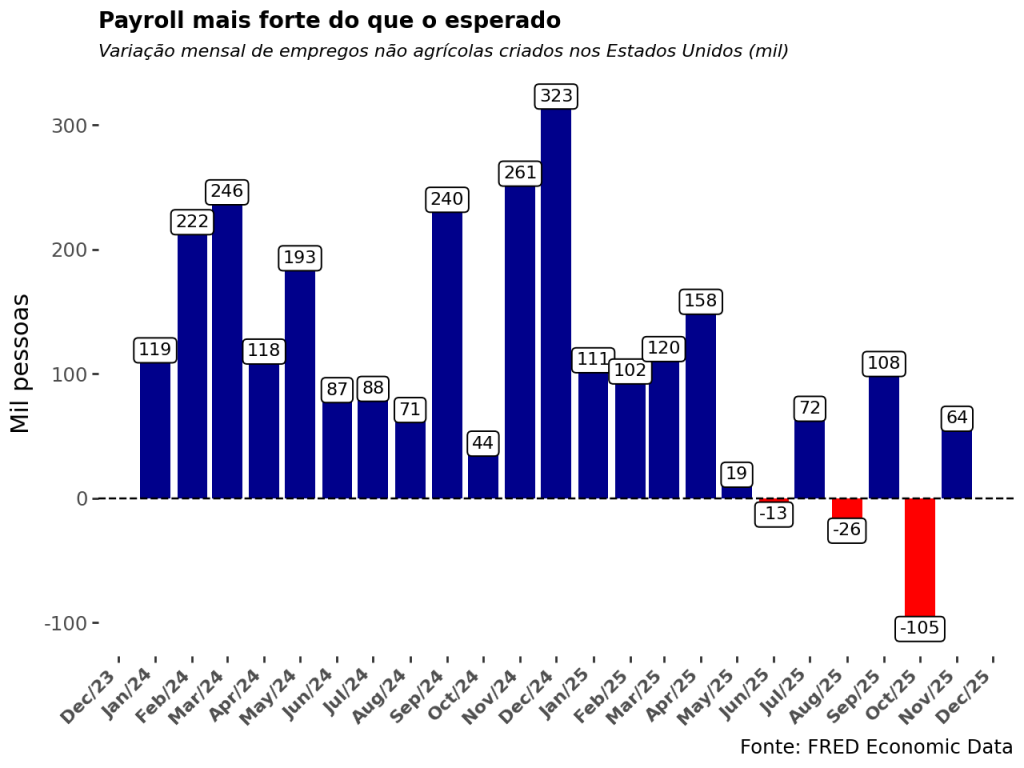
O Payroll norte-americano é o termômetro da economia global. No post de hoje, mostro como analisar esse indicador usando Python e as bibliotecas Pandas e Plotnine. Saia do básico e aprenda a visualizar a geração de empregos nos EUA de forma profissional.
