Analisando a ancoragem das expectativas de inflação no Python
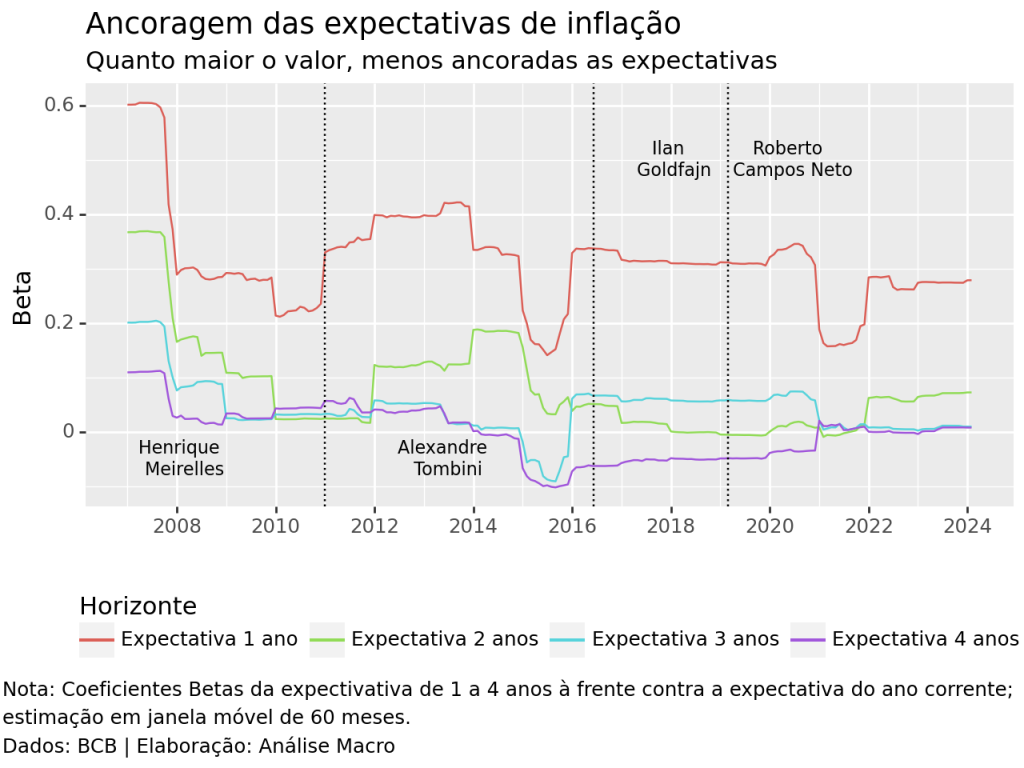
Se expectativas de inflação ancoradas com a meta são importantes para a economia, analisar o grau de ancoragem é imperativo para economistas e analistas de mercado. Neste exercício mostramos uma forma de aplicar esta análise com uma metodologia desenvolvida pelo FMI. Desde a coleta dos dados, passando pelo modelo e pela visualização de dados, mostramos como analisar a política monetária usando o Python.
DBnomics: 1 bilhão de dados econômicos no Python
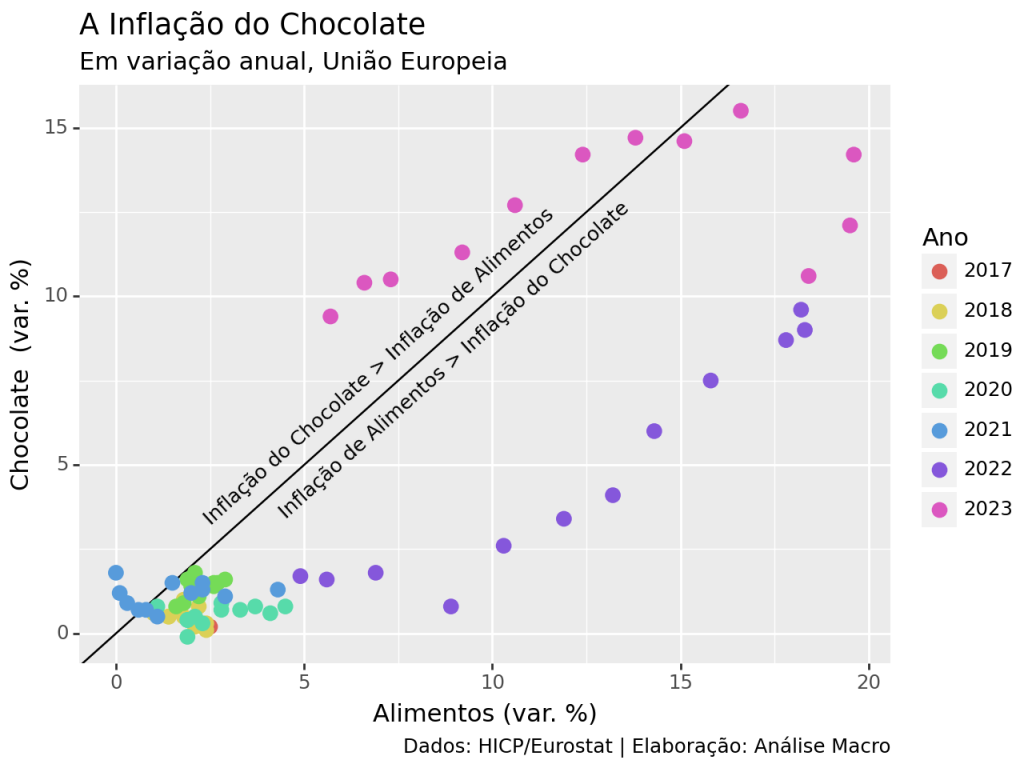
Neste exercício mostramos como usar a API de dados da DBnomics, que disponibiliza dados econômicos do Brasil e do mundo de ~100 fontes diferentes. Além de ser gratuita, a API é acessível diretamente do Python e é atualizada em tempo quase real.
Migrando dashboards do Excel para o Python
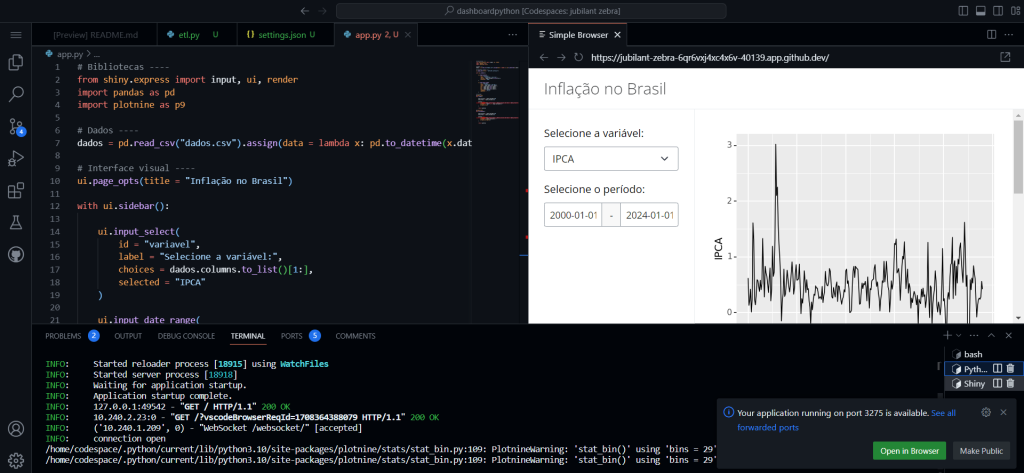
Neste exercício mostramos do zero como criar dashboards de análise de dados econômicos usando Python + Shiny. A vantagem destas ferramentas gratuitas é a facilidade de automatização e os ricos recursos disponíveis.
Migrando relatórios automáticos do Excel para o Python
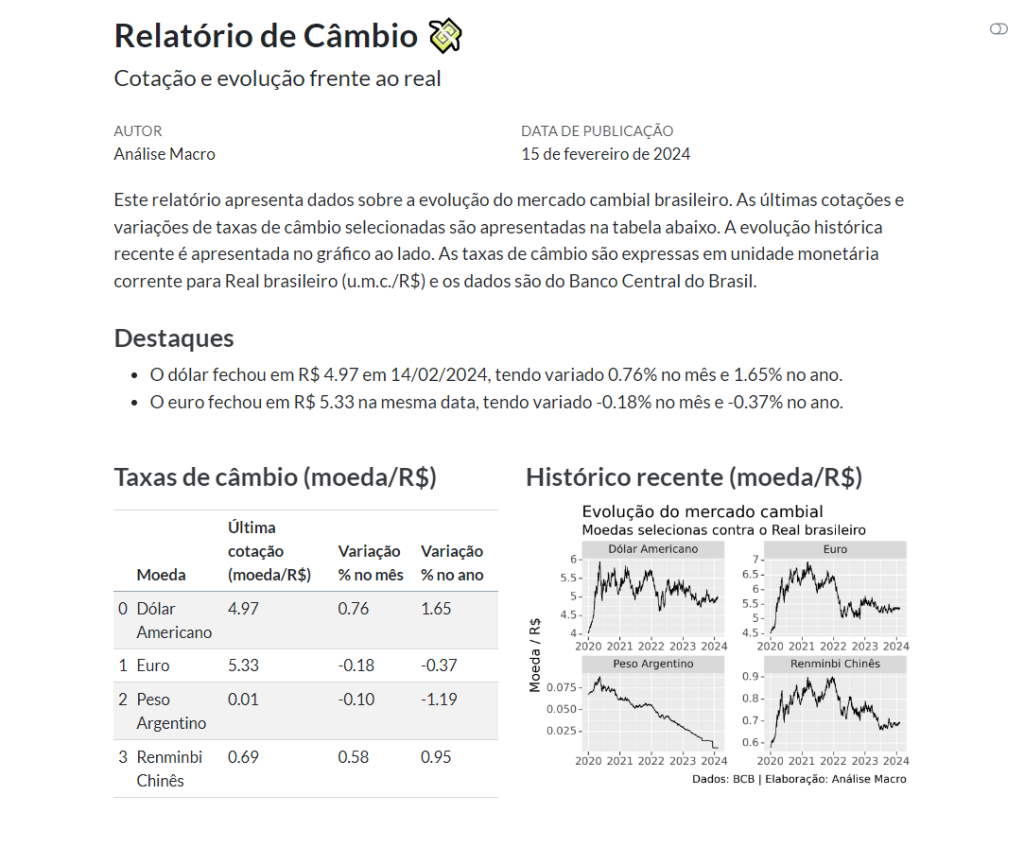
Neste texto mostramos que dá pra enterrar aquele seu relatório manual no Excel e automatizar toda a rotina de análise de dados usando o Python + Quarto. Mostramos um exemplo de relatório de câmbio com dados do Banco Central.
Como consolidar dezenas de planilhas em segundos com Python?
Neste texto mostramos que o retorno de investimento em aprender Python se paga rapidamente: imagine consolidar dados de mais de 70 arquivos diferentes e sem padrão usando apenas Excel? É nestas horas que o Python se destaca em maior produtividade e menos trabalho manual.
