Neste artigo investigamos se a previsão desagregada da inflação é capaz de gerar previsões mais acuradas do que a previsão agregada. Utilizamos o Índice Nacional de Preços ao Consumidor Amplo (IPCA) como medida de interesse, aplicando um modelo simples e um modelo de passeio aleatório para comparação. Todo o processo pode ser feito de maneira automatizada utilizando a linguagem de programação R.
Pacotes
Os pacotes utilizados no exercío são carregados conforme o código abaixo:
# Carregar pacotes library(sidrar) library(dplyr) library(tsibble) library(tidyr) library(purrr) library(fabletools) library(fable) library(ggplot2)
Dados
Os dados utilizados no exercício são provenientes do IBGE, através da API SIDRA. Utilizamos uma amostra de 2012 até os dados mais atuais, da última divulgação. O código abaixo coleta os dados e realiza os processamentos necessários:
Para ter acesso aos códigos deste exercício e outros de análise de dados, com vídeos, scripts, material complementar e suporte completo, conheça o Clube AM.
# A tibble: 1,278 × 4
data grupo variacao peso
<mth> <chr> <dbl> <dbl>
1 2012 Jan 1.Alimentação e bebidas 0.0086 0.231
2 2012 Feb 1.Alimentação e bebidas 0.0019 0.232
3 2012 Mar 1.Alimentação e bebidas 0.0025 0.231
4 2012 Apr 1.Alimentação e bebidas 0.0051 0.231
5 2012 May 1.Alimentação e bebidas 0.0073 0.231
6 2012 Jun 1.Alimentação e bebidas 0.0068 0.232
7 2012 Jul 1.Alimentação e bebidas 0.0091 0.233
8 2012 Aug 1.Alimentação e bebidas 0.0088 0.234
9 2012 Sep 1.Alimentação e bebidas 0.0126 0.236
10 2012 Oct 1.Alimentação e bebidas 0.0136 0.237
# ℹ 1,268 more rowsModelos
O objetivo deste exercício é produzir e comparar as previsões de um modelo simples para a inflação, medida pelo IPCA em variação percentual mensal, através dos dados desagregados (grupos) e agregados (índice cheio). As previsões desagregadas são reagregadas utilizando o peso do grupo em questão para formar a variação percentual mensal do índice cheio, tal como em Carlo & Marçal (2016). O modelo escolhido para teste foi um SARIMA automatizado, além de um passeio aleatório para comparação.
O código abaixo estima os modelos para os grupos do IPCA, restringindo os últimos dois anos da amostra para finalidade de teste e cálculo de erro.
Para ter acesso aos códigos deste exercício e outros de análise de dados, com vídeos, scripts, material complementar e suporte completo, conheça o Clube AM.
$`1.Alimentação e bebidas`
# A mable: 1 x 2
# Key: grupo [1]
grupo sarima
<chr> <model>
1 1.Alimentação e bebidas <ARIMA(1,0,0)(1,0,0)[12] w/ mean>
$`2.Habitação`
# A mable: 1 x 2
# Key: grupo [1]
grupo sarima
<chr> <model>
1 2.Habitação <ARIMA(0,0,2) w/ mean>
$`3.Artigos de residência`
# A mable: 1 x 2
# Key: grupo [1]
grupo sarima
<chr> <model>
1 3.Artigos de residência <ARIMA(1,0,1)(1,0,0)[12] w/ mean>
$`4.Vestuário`
# A mable: 1 x 2
# Key: grupo [1]
grupo sarima
<chr> <model>
1 4.Vestuário <ARIMA(1,0,3)(0,1,1)[12]>
$`5.Transportes`
# A mable: 1 x 2
# Key: grupo [1]
grupo sarima
<chr> <model>
1 5.Transportes <ARIMA(1,0,0) w/ mean>
$`6.Saúde e cuidados pessoais`
# A mable: 1 x 2
# Key: grupo [1]
grupo sarima
<chr> <model>
1 6.Saúde e cuidados pessoais <ARIMA(0,1,2)(1,0,2)[12]>
$`7.Despesas pessoais`
# A mable: 1 x 2
# Key: grupo [1]
grupo sarima
<chr> <model>
1 7.Despesas pessoais <ARIMA(1,1,2)(0,0,1)[12]>
$`8.Educação`
# A mable: 1 x 2
# Key: grupo [1]
grupo sarima
<chr> <model>
1 8.Educação <ARIMA(0,0,0)(1,1,0)[12] w/ drift>
$`9.Comunicação`
# A mable: 1 x 2
# Key: grupo [1]
grupo sarima
<chr> <model>
1 9.Comunicação <ARIMA(0,0,0)(1,0,0)[12] w/ mean>Previsão
Para produzir as previsões desagregadas (grupos) utilizamos cada um dos nove modelos correspondentes de cada grupo do IPCA, gerando 24 pontos de previsão a frente. Com estas previsões em mãos, produzimos a previsão agregada do IPCA ao somar os produtos entre a previsão do grupo i no período t e último peso deste mesmo grupo conhecido até o momento da previsão.
O código abaixo produz as previsões agregadas e desagregadas do IPCA:
Para ter acesso aos códigos deste exercício e outros de análise de dados, com vídeos, scripts, material complementar e suporte completo, conheça o Clube AM.
# A tibble: 216 × 5 grupo .model data variacao .mean <chr> <chr> <mth> <dist> <dbl> 1 1.Alimentação e bebidas sarima 2021 Nov N(0.011, 3.9e-05) 0.0111 2 1.Alimentação e bebidas sarima 2021 Dec N(0.009, 4.9e-05) 0.00900 3 1.Alimentação e bebidas sarima 2022 Jan N(0.0074, 5.2e-05) 0.00744 4 1.Alimentação e bebidas sarima 2022 Feb N(0.006, 5.3e-05) 0.00603 5 1.Alimentação e bebidas sarima 2022 Mar N(0.0057, 5.3e-05) 0.00570 6 1.Alimentação e bebidas sarima 2022 Apr N(0.0061, 5.3e-05) 0.00606 7 1.Alimentação e bebidas sarima 2022 May N(0.0061, 5.3e-05) 0.00609 8 1.Alimentação e bebidas sarima 2022 Jun N(0.0061, 5.3e-05) 0.00606 9 1.Alimentação e bebidas sarima 2022 Jul N(0.0063, 5.3e-05) 0.00632 10 1.Alimentação e bebidas sarima 2022 Aug N(0.0076, 5.3e-05) 0.00756 # ℹ 206 more rows
# A tibble: 24 × 2 data previsao <mth> <dbl> 1 2021 Nov 0.00766 2 2021 Dec 0.00658 3 2022 Jan 0.00462 4 2022 Feb 0.00625 5 2022 Mar 0.00434 6 2022 Apr 0.00445 7 2022 May 0.00430 8 2022 Jun 0.00434 9 2022 Jul 0.00392 10 2022 Aug 0.00338 # ℹ 14 more rows
Acurácia
Visando comparar a qualidade da previsão entre as duas metodologias, calculamos a Raiz do Erro Quadrático Médio (RMSE) da previsão reagregada do IPCA a partir dos grupos, de um modelo de previsão agregado (índice cheio) do IPCA e de um modelo passeio aleatório. O código abaixo realiza estes procedimentos:
Para ter acesso aos códigos deste exercício e outros de análise de dados, com vídeos, scripts, material complementar e suporte completo, conheça o Clube AM.
Acurácia do modelo reagregado: # A tibble: 1 × 1
RMSE
<dbl>
1 0.00448
Acurácia do modelo agregado e passeio aleatório: # A tibble: 2 × 3
.model .type RMSE
<chr> <chr> <dbl>
1 rw Test 0.00929
2 sarima Test 0.00472Podemos observar que o modelo de previsão reagregado do IPCA apresenta, na amostra utilizada, um erro marginalmente menor em relação aos demais, o que corrobora com os resultados encontrados em Carlo & Marçal (2016).
Os resultados deste exercício podem ser diferentes para amostras de dados diferentes. Recomendamos testes mais intensivos com o uso de validação cruzada para uma visão mais geral sobre a perfomance das metodologias.
Visualização de dados
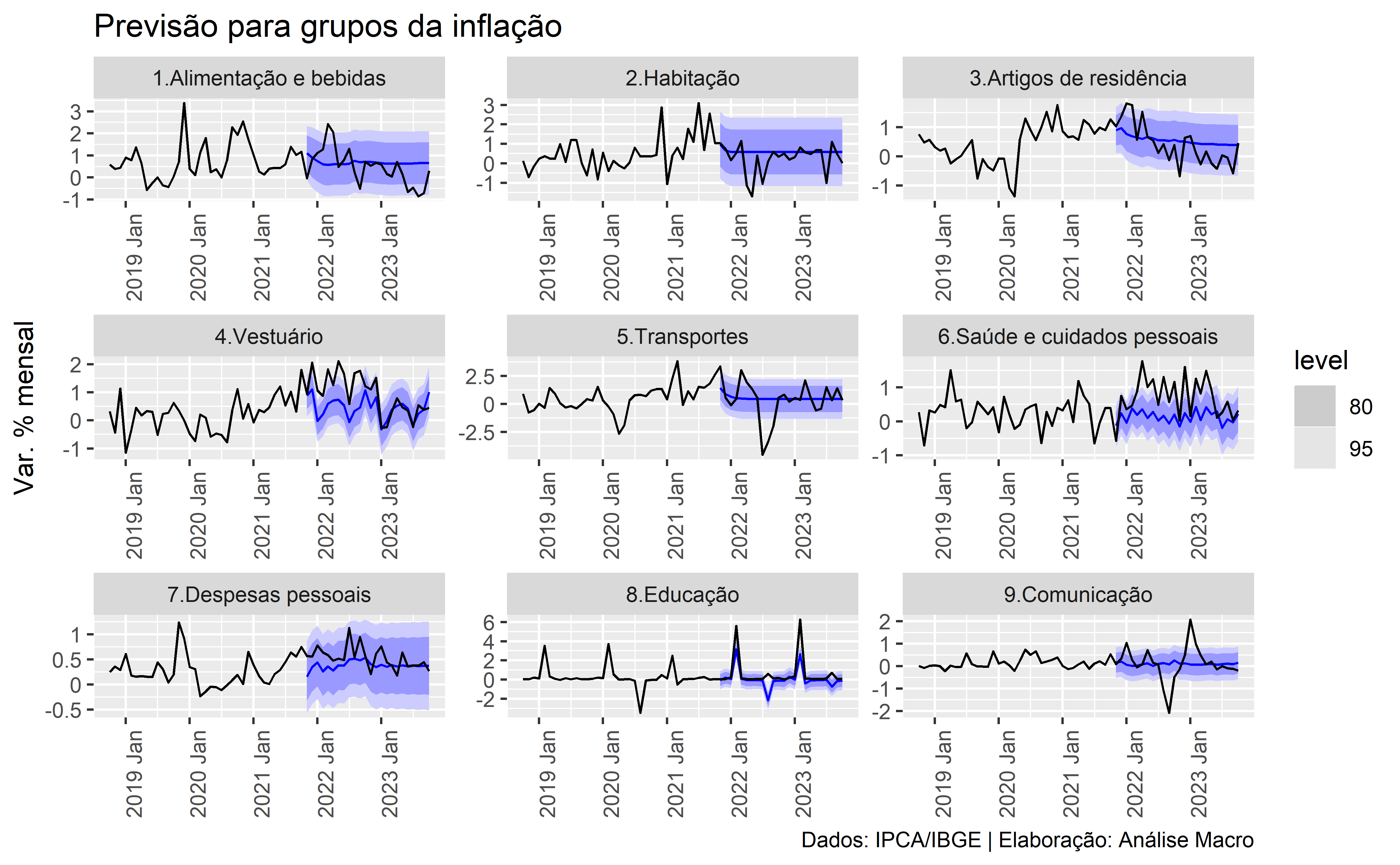
Finalizamos exibindo no gráfico abaixo as previsões geradas para os nove grupos do IPCA comparadas com os dados obervados no período:
Conclusão
Neste artigo investigamos se a previsão desagregada da inflação é capaz de gerar previsões mais acuradas do que a previsão agregada. Utilizamos o Índice Nacional de Preços ao Consumidor Amplo (IPCA) como medida de interesse, aplicando um modelo simples e um modelo de passeio aleatório para comparação. Todo o processo pode ser feito de maneira automatizada utilizando a linguagem de programação R.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.
Referências
Thiago Carlomagno Carlo & Emerson Fernandes Marçal (2016): Forecasting Brazilian inflation by its aggregate and disaggregated data: a test of predictive power by forecast horizon, Applied Economics, DOI: 10.1080/00036846.2016.1167824

