Agente de IA que coleta dados do BCB e do IBGE sozinho
Construímos um agente de IA que recebe um pedido em português e decide sozinho onde buscar o dado — no Banco Central ou no IBGE. Ele coleta, valida em três camadas e guarda só o que passou. E quando não sabe o que está pegando, pergunta em vez de inventar. Por dentro: LangGraph, o loop agêntico, os guardrails de cada fonte e a memória do agente.
Como construímos um agente de IA que lê as atas do Copom
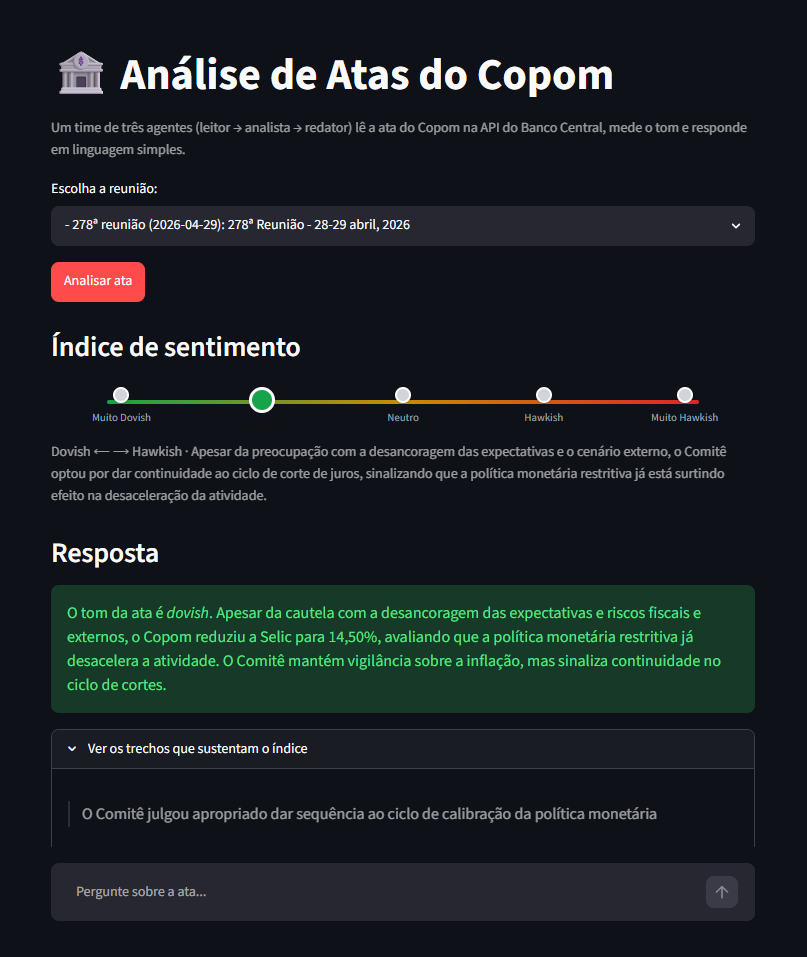
Toda reunião do Copom gera uma ata longa, e ler o documento para achar a Selic e o tom do comitê consome tempo. Mostramos um agente de IA que faz isso sozinho: três agentes (leitor, analista e redator) buscam a ata real na API do Banco Central, leem o documento inteiro e devolvem um resumo com a Selic exata. O post explica como o sistema funciona por dentro — o ciclo do agente, o mural compartilhado e as ferramentas (LangGraph, Python, Streamlit) — com o resultado real.
Pipeline de relatório de IPCA com agentes no Claude Code
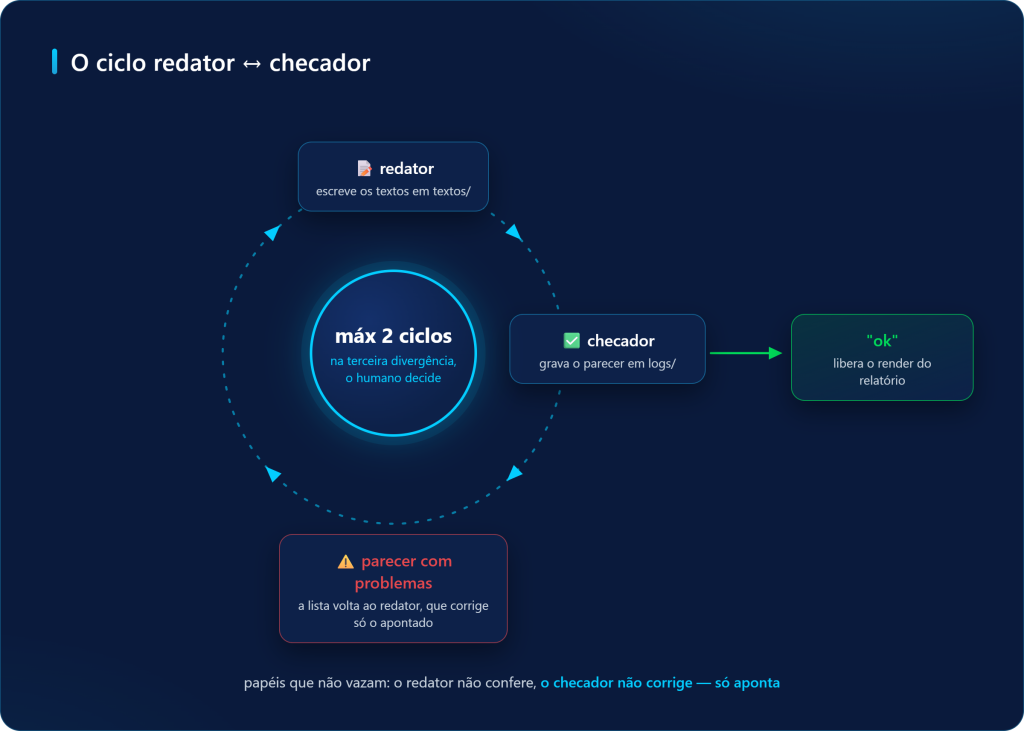
Um relatório mensal do IPCA refeito por um único comando: scripts Python calculam as métricas, sete subagentes do Claude Code investigam por que o número surpreendeu a mediana Focus e escrevem os textos, e o Quarto monta o HTML. O post mostra a arquitetura em três camadas, o critério que decide o que vira script e o que vira agente, o fan-out de coletores em paralelo, o ciclo redator–checador com teto e o resultado real de março de 2026, quando o IPCA veio 0,28 ponto percentual acima do consenso.
Skills no Claude Code: o que são, onde ficam e como acionar
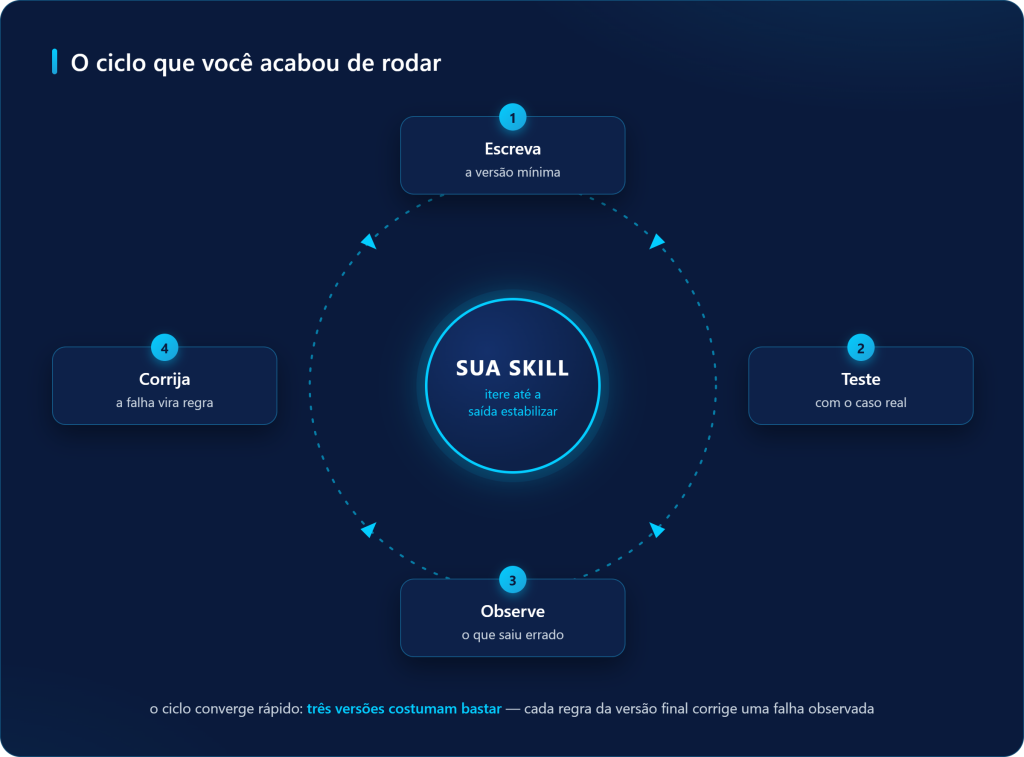
Uma skill do Claude Code empacota o procedimento de uma tarefa repetitiva — regras, fórmulas e formato de saída — num SKILL.md que o agente carrega só quando a tarefa aparece. O post mostra os três escopos (projeto, pessoal e plugin), o acionamento por slash command ou linguagem natural, a diferença para CLAUDE.md, subagente, MCP e hook, e o ciclo de construção por tentativa e erro que levou uma skill de variação do IPCA da versão mínima à versão estável em três iterações. O resultado é um procedimento versionado no git, igual para todo o time.
Context Engineering: o que o modelo lê quando responde

Como o modelo lê o seu pedido, como decide a resposta, e por que às vezes inventa coisa?
A habilidade central de quem trabalha com LLM hoje deixou de ser escrever prompt mais bonito e passou a ser escolher o que entra no contexto do modelo a cada interação, ofício que ganhou o nome de context engineering. Antes de chegar nele, convém destrinchar o que está embaixo: o que é um token, como o modelo é treinado, o que muda quando ele vira agente, e por que o foco migrou do prompt para o contexto.
