
A aprendizagem por transferência (transfer learning) é o reuso de um modelo pré-treinado em um novo problema. Portanto, sua utilização torna-se um avanço enorme para a previsão de diferentes tipos de variáveis, principalmente para aquelas ordenadas no tempo. Mostramos nesta postagem o uso do Transfer Learning com o Python para o caso de Séries Temporais.
O que é Transfer Learning?
A aprendizagem por transferência (transfer learning) é o reuso de um modelo pré-treinado em um novo problema. É muito útil no campo da ciência de dados, já que a maioria dos problemas do mundo real geralmente não possui milhões de pontos de dados rotulados para treinar tais modelos complexos.
Aprenda a coletar, processar e analisar dados na formação de Do Zero à Análise de Dados com Python.
Importante mencionar que a aprendizagem por transferência não é realmente uma técnica de aprendizado de máquina, mas pode ser vista como um “design methodology”. Também não é uma parte exclusiva ou área de estudo do aprendizado de máquina. No entanto, tornou-se bastante popular em combinação com redes neurais que requerem grandes quantidades de dados e poder computacional.
Como funciona?
No aprendizado por transferência, o conhecimento de um modelo de aprendizado de máquina já treinado é aplicado a um problema diferente, mas relacionado a ele. Por exemplo, se você treinou um classificador para prever se uma imagem contém uma mochila, você poderia usar o conhecimento que o modelo adquiriu durante seu treinamento para reconhecer outros objetos, como óculos de sol.
Com aprendizado por transferência, basicamente tentamos aproveitar o que foi aprendido em uma tarefa para melhorar a generalização em outra. Transferimos o que o modelo aprendeu na “tarefa A” para uma nova “tarefa B”.
A ideia geral é usar o conhecimento que um modelo aprendeu de uma tarefa com muitos dados de treinamento rotulados disponíveis em uma nova tarefa que não possui muitos dados. Em vez de começar o processo de aprendizado do zero, começamos com padrões aprendidos ao resolver uma tarefa relacionada.
Para o que é utilizado?
Como mencionado, o aprendizado por trasferência é muito utilizado na área de apredizagem de máquina, mas é implementado em nichos mais especificos, como NLP (Natural Language Process) e Computer Vision.
Para o caso de aprendizado de máquina, podemos empregar o aprendizado por transferência em dados de séries temporais, que é a forma que se encontra a maioria dos dados econômicos e financeiros.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
O interessante é que há a possibilidade de utilizar a metodologia facilmente por meio da bibilioteca mlforecast do Python, como demonstramos abaixo.
# Instala bibliotecas
!pip install mlforecast
!pip install utilsforecast
!pip install datasetsforecast
# Realiza importação dos módulos
import lightgbm as lgb
import numpy as np
import pandas as pd
from sklearn.metrics import mean_absolute_error
from utilsforecast.plotting import plot_series
from datasetsforecast.m3 import M3
from mlforecast import MLForecast
from mlforecast.target_transforms import DifferencesPasso 1: Treinamento do Modelo
Primeiro é necessário pré-treinar o modelo em um amplo conjunto de dados, com diversas variáveis de séries temporais. Com o resultado do modelo pré-treinado nessa ampla variedade de dados, poderemos extrapolar os resultados ao treinar o modelo para a variável de interesse.
O modelo pré-treinado consistirá das variáveis em periodicidade mensal da competição M3. O conjunto de dados é facilmente importado do modulo M3 da biblioteca datasetsforecast.
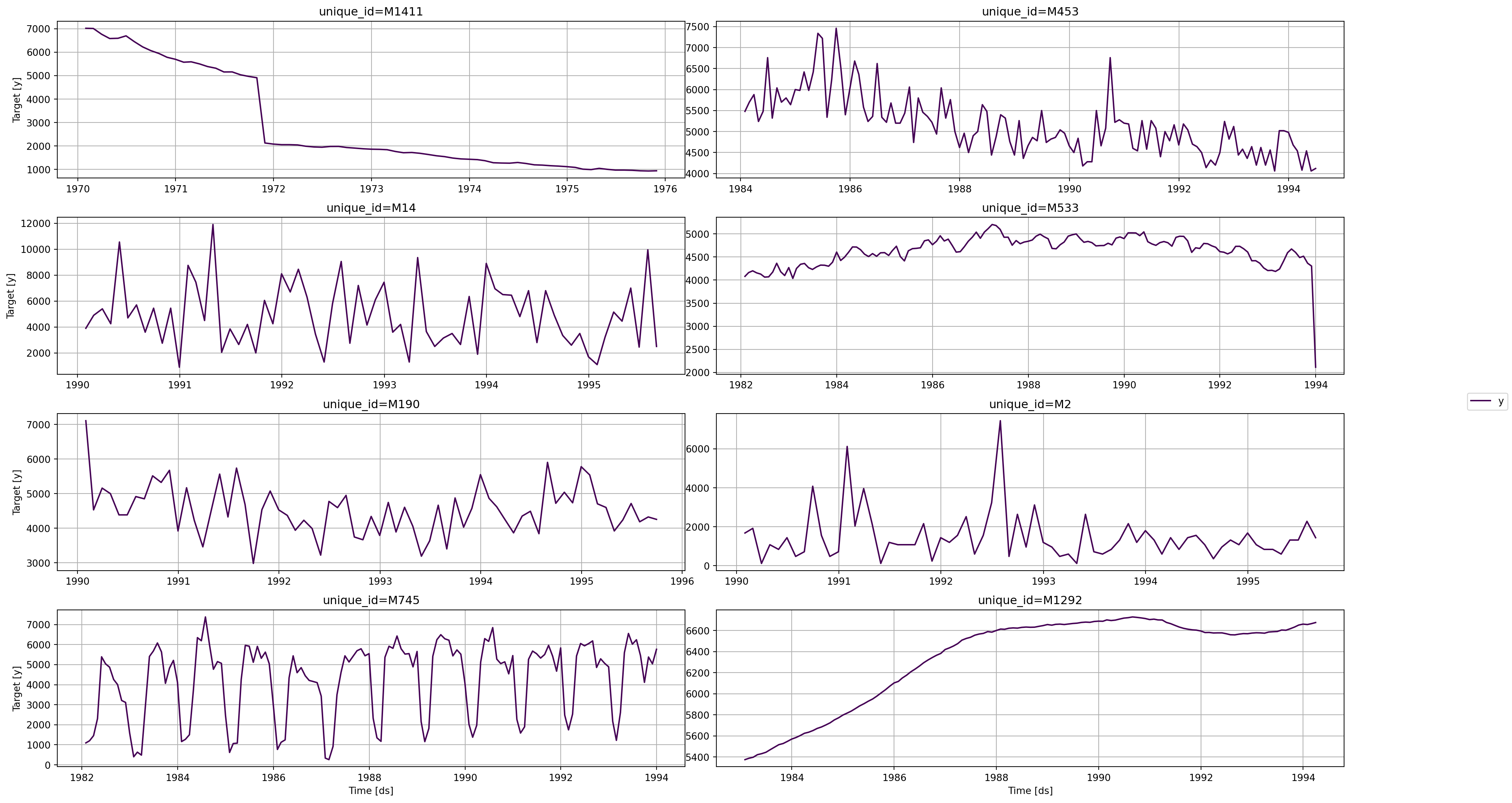
Y_df_M3, _, _ = M3.load(directory='./', group='Monthly')Abaixo, algumas das variáveis contidas no dataset da M3. Podemos perceber uma diferença significativa no processo gerador de dados das séries temporais.
plot_series(Y_df_M3)
models = [lgb.LGBMRegressor(verbosity=-1)]
fcst = MLForecast(
models=models,
lags = range(1, 13),
freq = 'MS',
target_transforms = [Differences([1, 12])]
)
fcst.fit(Y_df_M3);Passo 2: Transferência do treinamento para a variável de interesse
Uma vez treinado o modelo em um amplo conjunto de dados, podemos “transferir” o resultado para prever os valores da variável de interesse.
Para certificar a acurácia dos valores previstos realizamos a separação dos valores de treino e teste do dataset AirPassengers.
Y_df = pd.read_csv('https://datasets-nixtla.s3.amazonaws.com/air-passengers.csv', parse_dates=['ds'])
Y_train_df = Y_df[Y_df.ds<='1959-12-31']
Y_test_df = Y_df[Y_df.ds>'1959-12-31'] Y_hat_df = fcst.predict(h=12, new_df=Y_train_df)
Y_hat_df.head()| unique_id | ds | LGBMRegressor | |
|---|---|---|---|
| 0 | AirPassengers | 1960-01-01 | 422.740112 |
| 1 | AirPassengers | 1960-02-01 | 399.480225 |
| 2 | AirPassengers | 1960-03-01 | 458.220337 |
| 3 | AirPassengers | 1960-04-01 | 442.960419 |
| 4 | AirPassengers | 1960-05-01 | 461.700500 |
Passo 3: Avaliação dos Resultados
Finalizamos realizando a comparação dos dados de treino e teste.
Y_hat_df = Y_test_df.merge(Y_hat_df, how='left', on=['unique_id', 'ds']) plot_series(Y_train_df, Y_hat_df)

y_true = Y_test_df.y.values
y_hat = Y_hat_df['LGBMRegressor'].values
print(f'LGBMRegressor MAE: {mean_absolute_error(y_hat, y_true):.3f}')LGBMRegressor MAE: 13.560Considerações
O Transfer Learning é uma metodologia de design muito utilizada no campo de Ciência de dados atualmente, sendo muito importante para as áreas de NLP e computer vision, principalmente quando não há uma quantidade ideal de dados rotulados.
O interessante é a possibilidade de uso da ferramenta para diferentes tipos de dados, como é o caso de séries temporais. O problema claramente reside na obtenção do modelo pré-treinado, que necessita de uma ampla quantidade de variáveis para o treinamento, além da necessidade de que a transferência de modelos requer que haja os mesmos inputs.
Referências
Nixtla. How-to-guides: Transfer Learning. Acesso em: https://nixtlaverse.nixtla.io/mlforecast/docs/how-to-guides/transfer_learning.html
Donges, Niklas. What is Transfer Learning? Exploring the Popular Deep Learning Approach. Acesso em: https://builtin.com/data-science/transfer-learning
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

