Introdução
Nos dias atuais, pessoas que trabalham com dados estão constantemente confrontados com um dilema: criar uma tabela não tão genial no Excel ou manter em um formato ainda pior, como um dataframe, mas mantendo a flexibilidade de obtenção dos dados. Podemos resolver esse grande problema, unindo a flexibilidade e beleza ao usar a biblioteca great_tables do Python.
Aprenda a coletar, processar e analisar dados na formação de Do Zero à Análise de Dados com Python.
O Excel nas últimas três décadas forneceu uma melhora significativa na construção de tabelas em planilhas eletrônicas, entretanto, elas nunca poderiam se comparar ao que era mostrado em manuais avançados de construção de tabelas (por mais que você se tornasse um especialista em Excel). Além disso, a análise de dados começou a se tornar algo realizado fora do Excel. Um exemplo disso é o Python e seu uso dentro dos notebooks Jupyter. Diante disso, temos um conjunto de cenários problemáticos:
- Tudo em Python: analisar dados e gerar tabelas tudo em Python (tabelas ruins).
- Tudo em Excel: analisar dados e fazer tabelas no Excel (análise menos flexível).
- Dividido: analisar dados em Python, copiar para o Excel para fazer tabelas (não reproduzível).
Todas essas são soluções subótimas. É possível alcançar algo que é muito melhor fazer tudo em Python: a ingestão de dados, a análise de dados e a visualização de dados. A etapa de visualização é o que é feito para gráficos e outros tipos de gráficos compostos a partir de dados, não deveria ser diferente quando se trata de gerar tabelas de resumo.
Composição da tabela
Com o Great Tables, qualquer pessoa pode criar belas tabelas em Python. O framework expressa uma tabela como uma combinação de seis componentes independentes. Com este framework, você pode estruturar a tabela, formatar os valores e estilizar a tabela. Acredita-se firmemente que os métodos oferecidos no pacote permitem que as pessoas construam uma ampla variedade de tabelas úteis que funcionam em muitas disciplinas.
Você constrói com Great Tables iterativamente, começando com o corpo da sua tabela a partir do código, adicionando estilos, formatação e outros componentes. Aqui está um esquema que delineia a terminologia e representa como os diferentes componentes da tabela estão relacionados entre si:
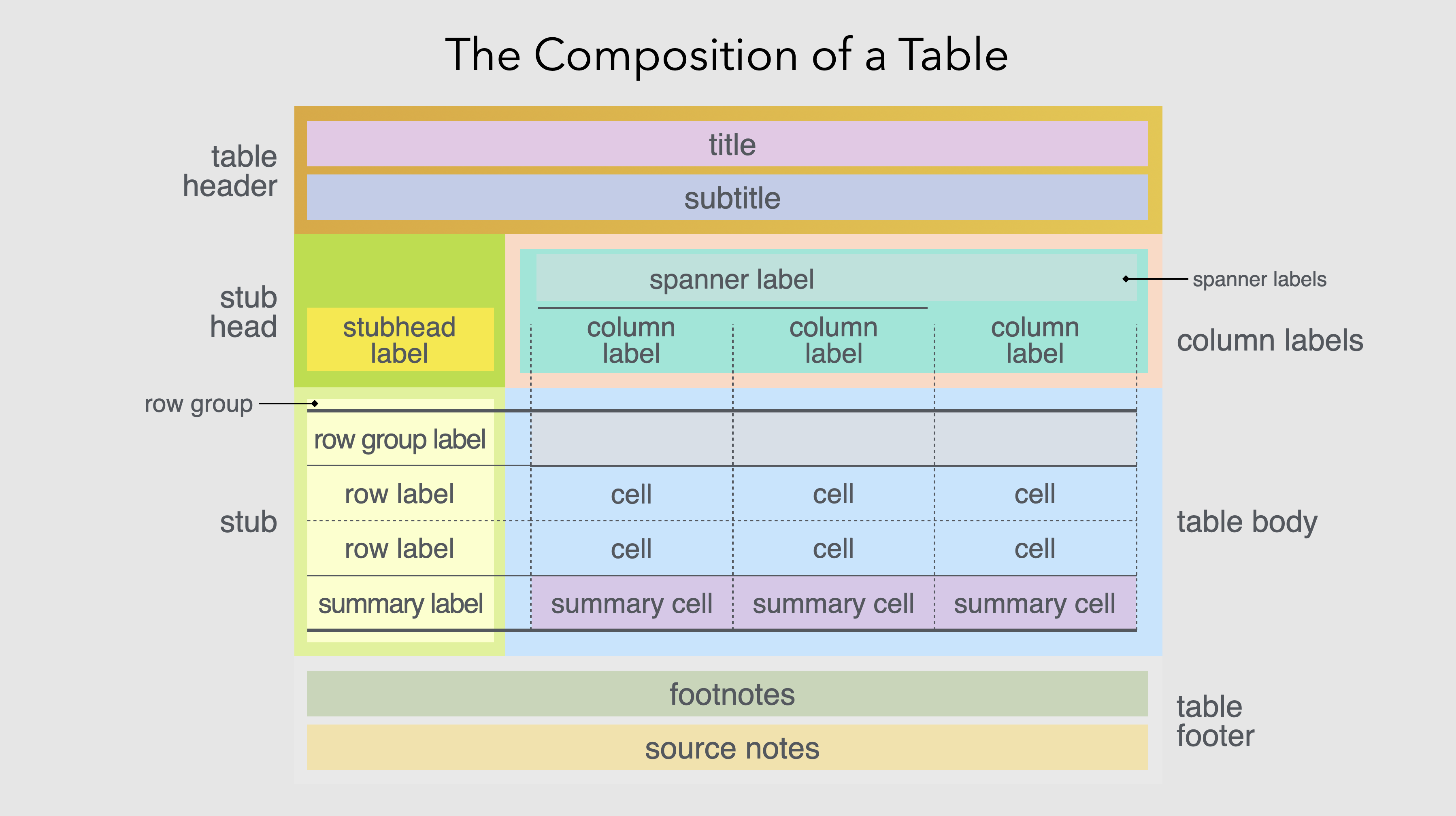
- Table Header: um lugar para o título, subtítulo e onde você pode descrever sucintamente o conteúdo da sua tabela.
- Column Labels: os rótulos das colunas definem o conteúdo de cada coluna, e os spanners são cabeçalhos sobre os grupos de colunas.
- Stub Head: a localização na esquerda superior, onde cada rótulo pode ser usado em uma variedade de formas.
- Row Stub: para informação da linha, incluindo rótulos de linhas agrupados.
- Table Body: contém células e onde os dados vivem.
- Table Footer: um lugar para informação adicional pertencendo ao conteúdo da tabela.
Exemplo IPCA-15
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Como exemplo da construção de tabelas, vamos usar dois conjuntos de dados: as tabelas 3065 e 7062 do IPCA-15 disponíveis no SIDRA/IBGE, que representam as variações do índice do indicador, e de seus grupos.
O código em Python realiza a importação dos dados, realiza a manipulação de dados e constrói as tabelas. Abaixo o resultado das tabelas construídas (dados referentes a Abril de 2024):
Tabela 3065
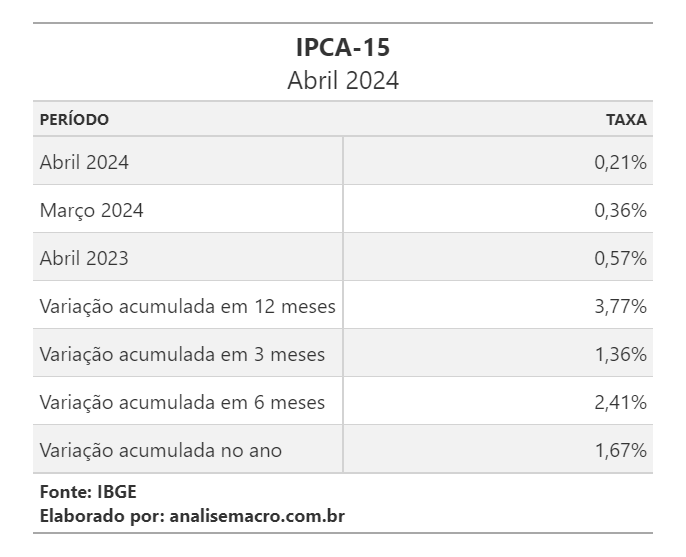
Tabela 7062

Referências
Posit. Introducing Great Tables for Python. Acesso em: https://posit.co/blog/introducing-great-tables-for-python-v0-1-0/
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

