No mês de dezembro, iremos lançar uma nova versão do Clube do Código, que se chamará Clube AM. O projeto de compartilhamento de códigos da Análise Macro vai avançar para uma versão 2.0, que incluirá a existência de um grupo fechado no Whatsapp, de modo a reunir os membros do Novo Clube, compartilhando com eles todos os códigos dos nossos posts feitos aqui no Blog, exercícios de análise de dados de maior fôlego, bem como tirar dúvidas sobre todos os nossos projetos, exercícios e nossos Cursos e Formações.
Para ilustrar o que vamos compartilhar lá nesse novo ambiente, estou publicando nesse espaço alguns dos nossos exercícios de análise de dados. Esses exercícios fazem parte do repositório atual do Clube do Código, que deixará de existir. Além de todos os exercícios existentes no Clube do Código, vamos adicionar novos exercícios e códigos toda semana, mantendo os membros atualizados sobre o que há de mais avançado em análise de dados, econometria, machine learning, forecasting e R.
Hoje, nós verificamos se as expectativas de inflação relatadas pelo boletim Focus sofrem de viés sistemático, contrariando assim a hipótese de expectativas racionais. Os resultados encontrados sugerem que as expectativas de inflação do boletim Focus subestimam a inflação efetivamente observada.
Para isso, nós basicamente estimamos a equação abaixo, com base em Kohlscheen (2012):
(1) ![\begin{align*} \pi_{t} - E_{t-1}[\pi_{t}] = \alpha_0 + \eta_t \end{align*}](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-e8fab5ce051ab7a32324970674317c18_l3.png "Rendered by QuickLaTeX.com")
onde  é a inflação mensal em
é a inflação mensal em  e
e ![E_{t-1}[\pi_{t}]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-0c00f8ca0754f80da2894ed7389f382c_l3.png "Rendered by QuickLaTeX.com") é a expectativa para a inflação em . A estimação dessa equação visa verificar a ausência de viés sistemático nas projeções contidas no boletim Focus.
é a expectativa para a inflação em . A estimação dessa equação visa verificar a ausência de viés sistemático nas projeções contidas no boletim Focus.
Abaixo, carregamos os pacotes necessários para o exercício.
library(rbcb) library(tidyverse) library(lubridate) library(scales) library(latex2exp) library(scales) library(lmtest) library(sandwich)
Na sequência, nós usamos o pacote rbcb para coletar os dados de expectativas de inflação contidas no boletim Focus e os dados da inflação efetiva.
## Coletar as expectativas de inflação diárias e mensalizar os dados
expectativa = get_monthly_market_expectations('IPCA') %>%
mutate(reference_month = ymd(parse_date_time(reference_month,
orders = '%Y-%m')),
diff_months = round(time_length(reference_month - date,
unit='month'),2)) %>%
filter(base == 0 & diff_months > 0 & diff_months < 1) %>%
group_by(mes=floor_date(date, "month")) %>%
summarize(media=mean(mean))
expectativa$mes = expectativa$mes %m+% months(1)
## Coletar os dados de inflação mensal
inflacao = get_series(433, start_date = '2000-04-01') %>%
rename(mes = date, value=`433`)
## Juntar os dados
names = c('date', 'expectativa', 'inflacao')
data = inner_join(expectativa, inflacao, by='mes') %>%
`colnames<-`(names) %>%
mutate(erro = inflacao - expectativa)
Abaixo, um gráfico que contém o erro nas previsões contidas no boletim Focus em relação à inflação mensal efetiva.
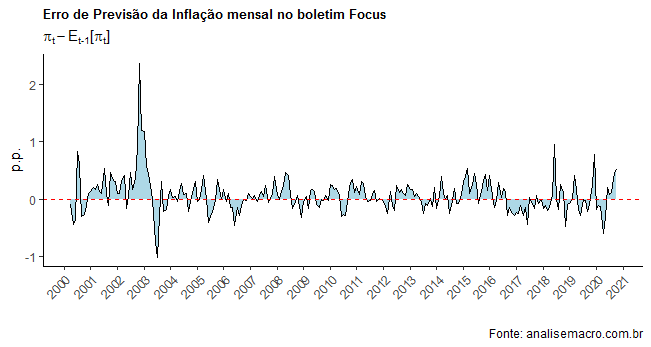
Na sequência, nós verificamos se o erro de previsão contém viés, conforme a equação acima.
| Dependent variable: | |
| erro | |
| Constant | 0.067*** |
| (0.020) | |
| Observations | 247 |
| R2 | 0.000 |
| Adjusted R2 | 0.000 |
| Residual Std. Error | 0.310 (df = 246) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 |
Isto é, as expectativas do boletim Focus subestimam a inflação mensal em 7 pontos-base, mostrando assim presença de viés nas mesmas. Os resultados encontrados, diga-se, estão em linha com Kohlscheen (2012).
_________________
Kohlscheen, E. 2012. “Uma Nota Sobre Erros de Previsão Da Inflação de Curto Prazo.” Revista Brasileira de Economia 66 (3): 289–97.
(*) Cadastre-se aqui na nossa Lista VIP para receber um super desconto na abertura das Turmas 2021.


