Modelos univariados são bastante utilizados para fins de modelagem e previsão de um amplo conjunto de variáveis. Nesse post, vamos ilustrar a aplicação desses modelos sobre a inflação brasileira medida pelo IPCA utilizando modelos do tipo ARIMA
Criando um Modelo AutoArima no Python
Para criar uma previsão do IPCA usando o Python, devemos proceder através do processo de Análise de Dados, seguindo os seguintes passos:
- Coleta do IPCA: utilizaremos a biblioteca python-bcb para retirar os dados do IPCA mensal direto do SGS, por meio do código 433;
- Tratamento e Data Wrangling: Para fins de criação e utilização da biblioteca statsforecast devemos formatar os dados em uma forma ideal, bem como realizar a separação de dados de treino e teste;
- Análise exploratória: Averiguar por meio de estatísticas descritivas e gráficos o comportamento do IPCA;
- Modelagem e Previsão: criação do modelo e previsão.
Começamos com o processo de coleta dos dados e tratamento dos dados do IPCA, como demonstrado no código abaixo:
# Coleta do IPCA
ipca_raw = sgs.get(('y', 433), start = '2004-01-01')
# Tratamento do IPCA
ipca = (
ipca_raw
.reset_index()
.assign(unique_id = 'ipca')
.rename(columns = {'Date' : 'ds' })
)
O objetivo portanto, a partir da coleta e tratamento dos dados, será o de separar a amostra da série do IPCA mensal em teste e treino, utilizar a biblioteca statsforecast para rodar um AutoArima nos dados de testes.
Para entender todo o processo listado acima, com os códigos e video-aula, faça parte do Clube AM, o repositório de código da Análise Macro, contendo exercícios semanais de R e Python.
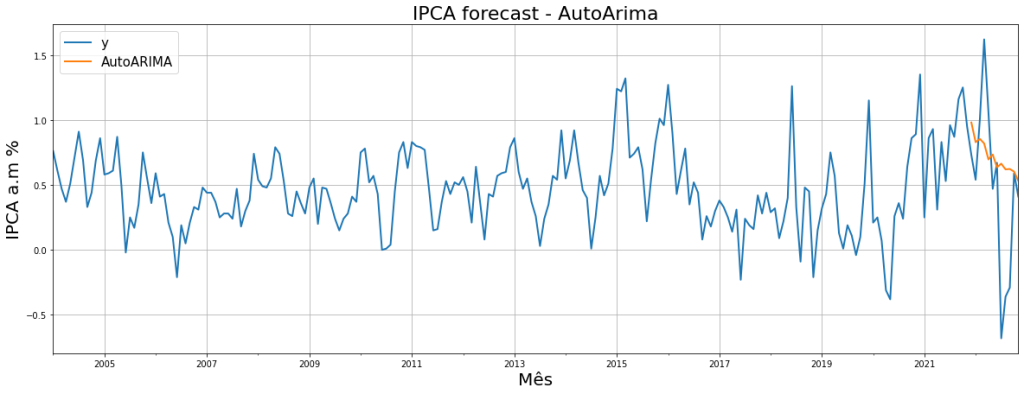
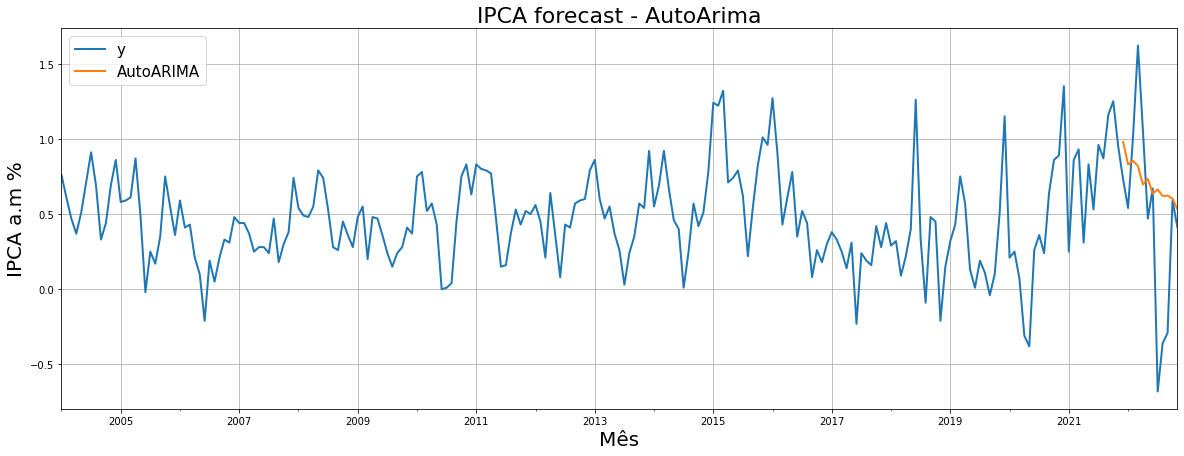
Vemos o resultado da previsão do AutoArima comparado com os dados de teste:
________________________________________________
Quer se aprofundar no assunto?
Alunos da trilha de Ciência de dados para Economia e Finanças podem aprender a como construir projetos que envolvem dados reais usando modelos econométricos e de Machine Learning com o R.
Referências
Hyndman, R.J., & Athanasopoulos, G. (2021) Forecasting: principles and practice, 3rd edition, OTexts: Melbourne, Australia. OTexts.com/fpp3.

