Como o Python se tornou a melhor linguagem de aplicação do statistical learning, e consequentemente de Machine Learning? Uma das bibliotecas que mais auxiliaram na fama da linguagem para a aplicação desse tema é o Scikit-learn, que vamos compreender neste post, utilizando-a com um exemplo de aplicação no Mercado Financeiro.
Como funciona o uso de statistical learning e machine learning para resolver problemas?
Statistical learning (ou aprendizado estatístico) é uma abordagem para a análise de dados que busca identificar relações estatísticas entre as variáveis do conjunto de dados. O objetivo é usar essas relações para desenvolver modelos preditivos ou descritivos que possam ser usados para entender e prever o comportamento dos dados.
O aprendizado estatístico envolve o uso de métodos estatísticos e matemáticos para analisar dados, identificar padrões e relações, e desenvolver modelos preditivos e descritivos. Os modelos estatísticos podem ser usados para prever valores futuros ou identificar relações entre as variáveis. Por exemplo, é possível usar modelos estatísticos para prever as vendas futuras de um produto com base no histórico de vendas anteriores, ou para identificar a relação entre o salário e a educação de uma pessoa.
Já Machine learning, ou aprendizado de máquina, é uma subárea da inteligência artificial que se concentra no desenvolvimento de algoritmos e modelos que permitem aos computadores aprender a partir de dados e realizar tarefas sem serem explicitamente programados para elas.
O machine learning é baseado em técnicas de statistical learning, que permitem que os modelos de aprendizado de máquina identifiquem relações entre as variáveis dos dados e usem essas relações para fazer previsões ou tomar decisões. Por exemplo, um modelo de aprendizado de máquina pode aprender a reconhecer imagens de gatos a partir de um conjunto de dados de imagens rotuladas, identificando padrões nas características dos gatos que distinguem as imagens de gatos de outras imagens.
Como aplicar essas duas áreas no Python?
Python é uma das linguagens de programação mais populares para machine learning e statistical learning, devido à grande variedade de bibliotecas e frameworks disponíveis,
Uma dessas bibliotecas se encontra no Scikit-learn que oferece diversas ferramentas para machine learning. Ela é construída em cima de outras bibliotecas populares, como NumPy, Pandas e Matplotlib, e é projetada para trabalhar em conjunto com essas ferramentas para tornar o processo de desenvolvimento de modelos de machine learning mais eficiente e fácil.
Com o scikit-learn é possível utilizar diversos algoritmos de machine learning e aplicar cada um para a resolução de problemas. Entre os problemas de aprendizado de máquina, eles podem se encaixar em algumas categorias:
- Supervised learning: O aprendizado supervisionado é uma abordagem do aprendizado de máquina em que um modelo é treinado para aprender a mapear entradas para saídas com base em exemplos de entrada-saída rotulados fornecidos durante o treinamento.
- Classificação: A classificação é um tipo de problema no aprendizado supervisionado em que o objetivo é prever a classe de um conjunto de dados com base em uma série de variáveis de entrada. Em outras palavras, a tarefa é construir um modelo que possa aprender a classificar novos dados em uma das várias classes previamente definidas.
- Regressão: A regressão é uma técnica de aprendizado supervisionado que é usada para prever valores numéricos contínuos, ou seja, valores em uma escala contínua. É usada quando a variável de saída que queremos prever é contínua, como prever o preço de uma casa ou a quantidade de chuva em um determinado dia.
- Unsupervised Learning: O aprendizado não supervisionado é uma abordagem do aprendizado de máquina em que um modelo é treinado em um conjunto de dados não rotulados, ou seja, dados em que a saída desejada não é fornecida. O objetivo do aprendizado não supervisionado é encontrar estruturas e padrões ocultos nos dados, agrupando-os em categorias ou segmentos.
Training set e testing set
Dados de treino e teste são conjuntos de dados usados em algoritmos de aprendizado de máquina para treinar e avaliar modelos. O conjunto de dados de treino é usado para ajustar os parâmetros do modelo, enquanto o conjunto de dados de teste é usado para avaliar o desempenho do modelo em dados nunca antes vistos.
O conjunto de dados de treino é composto por exemplos rotulados que são usados para ensinar o modelo a aprender a relação entre as variáveis de entrada e de saída. O objetivo é ajustar os parâmetros do modelo de forma que ele possa generalizar bem para novos dados. O conjunto de dados de treino geralmente é maior do que o conjunto de dados de teste, pois é necessário uma quantidade suficiente de dados para que o modelo possa aprender com precisão a relação entre as variáveis.
O conjunto de dados de teste é usado para avaliar o desempenho do modelo em dados nunca antes vistos. O objetivo é medir a capacidade do modelo de generalizar para novos dados. O conjunto de dados de teste é selecionado aleatoriamente a partir do conjunto de dados completo e deve ser representativo o suficiente para garantir que o modelo possa ser avaliado de forma justa. É importante lembrar que o conjunto de dados de teste deve ser usado apenas para avaliar o desempenho do modelo e não para ajustar seus parâmetros.
A separação dos dados em conjuntos de treino e teste é essencial para avaliar a eficácia do modelo de aprendizado de máquina. Sem essa separação, o modelo pode se ajustar demais aos dados de treino e falhar em generalizar para novos dados, resultando em uma baixa acurácia. Portanto, é importante ter um conjunto de dados de teste independente para avaliar o desempenho do modelo e ajustar seus parâmetros para melhorar a precisão.
Exemplos
Para obter o código da coleta, tratamento, visualização e dos testes estatísticos abaixo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais de R e Python.
Previsão de preços de casas
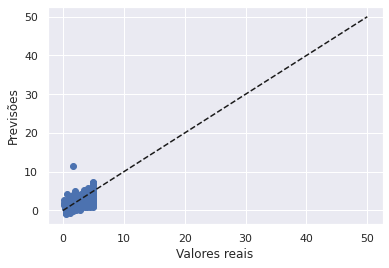
É possível realizar a aplicação do aprendizado de máquina com o scikit-learn em diversas áreas de estudos, como por exemplo, previsão do preço de casas em um bairro. Por meio da regressão linear, é possível prever uma variável com dados contínuos, como no caso o preço de uma casa. Usando o dataset California Housing disponível na biblioteca scikit-learn, é possível aplicar a regressão para prever os preços das casas contidas na amostra.
Vejamos abaixo no gráfico o resultado da aplicação da regressão linear na previsão dos preços das casas da California, no gráfico, é exibido a relação dos valores previstos com os valores reais, demonstrado o quão bem o modelo conseguiu prever os valores dos preços das casas.
Mercado Financeiro
É possível realizar a aplicação do aprendizado de máquina com o scikit-learn em diversas áreas de estudos, como por exemplo, o mercado financeiro. Por meio do uso da regressão logística, que é um problema de classificação, é possível prever a direção do retorno financeiro de uma ação listada na bolsa de valores. A partir dessa previsão, é possível construir estratégias de investimentos. Isto é, se sabe-se como prever se o retorno será positivo ou negativo em um passo no futuro, é possível tomar decisões prévias sobre investir ou não na ação, conseguindo obter lucros.
Vejamos abaixo no gráfico o resultado da aplicação de uma estratégia utilizando a regressão logística, em que exibe o retorno total proveniente da estratégia utilizada criada pelo algoritmo usando o scikit-learn.
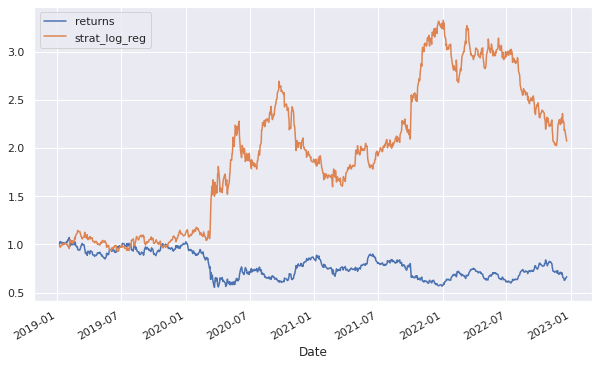 A linha azul, rotulada como returns, demonstra os retornos acumulados da ação ITUB4 do período de 2019 até o fim de 2022 para o caso de manter somente comprado. Em laranja, rotulado como strat_log_reg, representa o retorno acumulado da estratégia de previsão da direção dos retornos da ação da ITUB4 no mesmo período.
A linha azul, rotulada como returns, demonstra os retornos acumulados da ação ITUB4 do período de 2019 até o fim de 2022 para o caso de manter somente comprado. Em laranja, rotulado como strat_log_reg, representa o retorno acumulado da estratégia de previsão da direção dos retornos da ação da ITUB4 no mesmo período.
_________________________________
Quer se aprofundar no assunto?
Alunos da trilha de Especialista em Ciência de Dados para Economia e Finanças podem aprender a como construir projetos que envolvem dados reais usando o R e o Python como ferramentas.

