O que é Controle Sintético e como podemos utilizar essa ferramenta para auxiliar no estudo da avaliação de impacto? Neste post, oferecemos uma breve introdução a esse importante método da área de inferência causal, acompanhado de um estudo de caso para uma compreensão mais aprofundada de sua aplicação. Os resultados foram obtidos por meio da implementação em Python, como parte integrante do nosso curso sobre Avaliação de Políticas Públicas utilizando esta linguagem de programação.
Luiz Henrique Barbosa Filho
16 de março de 2024
09:00
O que é Controle Sintético e como podemos utilizar essa ferramenta para auxiliar no estudo da avaliação de impacto? Neste post, oferecemos uma breve introdução a esse importante método da área de inferência causal, acompanhado de um estudo de caso para uma compreensão mais aprofundada de sua aplicação. Os resultados foram obtidos por meio da implementação em Python, como parte integrante do nosso curso sobre Avaliação de Políticas Públicas utilizando esta linguagem de programação.
Controle Sintético
Determinadas condições se estabelecem para a base da inferência causal:
O grupo de controle seja similar ao grupo de tratamento
Exista um número relevante de observações em cada grupo
No entanto, é possível fazer inferência causal se tivermos apenas um caso tratado e alguns casos de controle, ou de maneira ainda mais extrema, se não houver casos de controle com covariáveis semelhantes ao caso tratado.
Parece até uma negação do que se conhece de resultados potenciais. Entretanto, esse tipo de situação pode ser frequente, principalmente quando vamos avaliar políticas em níveis muito agregados, como estados ou países. Normalmente, nesses casos, há apenas um indivíduo tratado. Para esse tipo de problema, o controle sintético pode ser uma boa solução.
Para explicarmos o controle sintético, digamos que temos que avaliar uma política qualquer que ocorreu apenas no estado de São Paulo a partir de 2012. Assim, como potencial grupo de controle, nós temos todos as outras 26 unidades federativas. O que o controle sintético faz é criar uma média ponderada da variável de interesse das unidades de controle que melhor se ajusta a curva da unidade tratada.
Criamos esses valores contrafactuais da variável de interesse sinteticamente ponderando os valores das unidades de outros grupos de controles. A possibilidade aqui é que a combinação dos valores desses grupos de controles pode aproximar melhor as características do grupo tratado do que qualquer não unidade não tratada sozinha.
Estudo de Caso: Lei anti fumo na Califórnia
Quer saber como essa análise foi construída? Seja aluno do nosso curso Avaliação de Políticas Públicas usando Python, e tenha acesso às aulas teóricas e práticas, com o código disponibilizado em Python.
Para mostrarmos um exemplo real, vamos estimar o impacto de uma política que visava diminuir o consumo de cigarro pela população da California. Em 1988, os eleitores do estado promulgaram a Proposta 99, aumentando o imposto sobre os cigarros em 25 centavos por maço, a partir de janeiro de 1989. Assim, comparando o consumo per capita de cigarro com outros 38 estados americanos podemos estimar o efeito por meio de controle sintético, semelhante a Abadie, Diamond, e Hainmueller (2010).
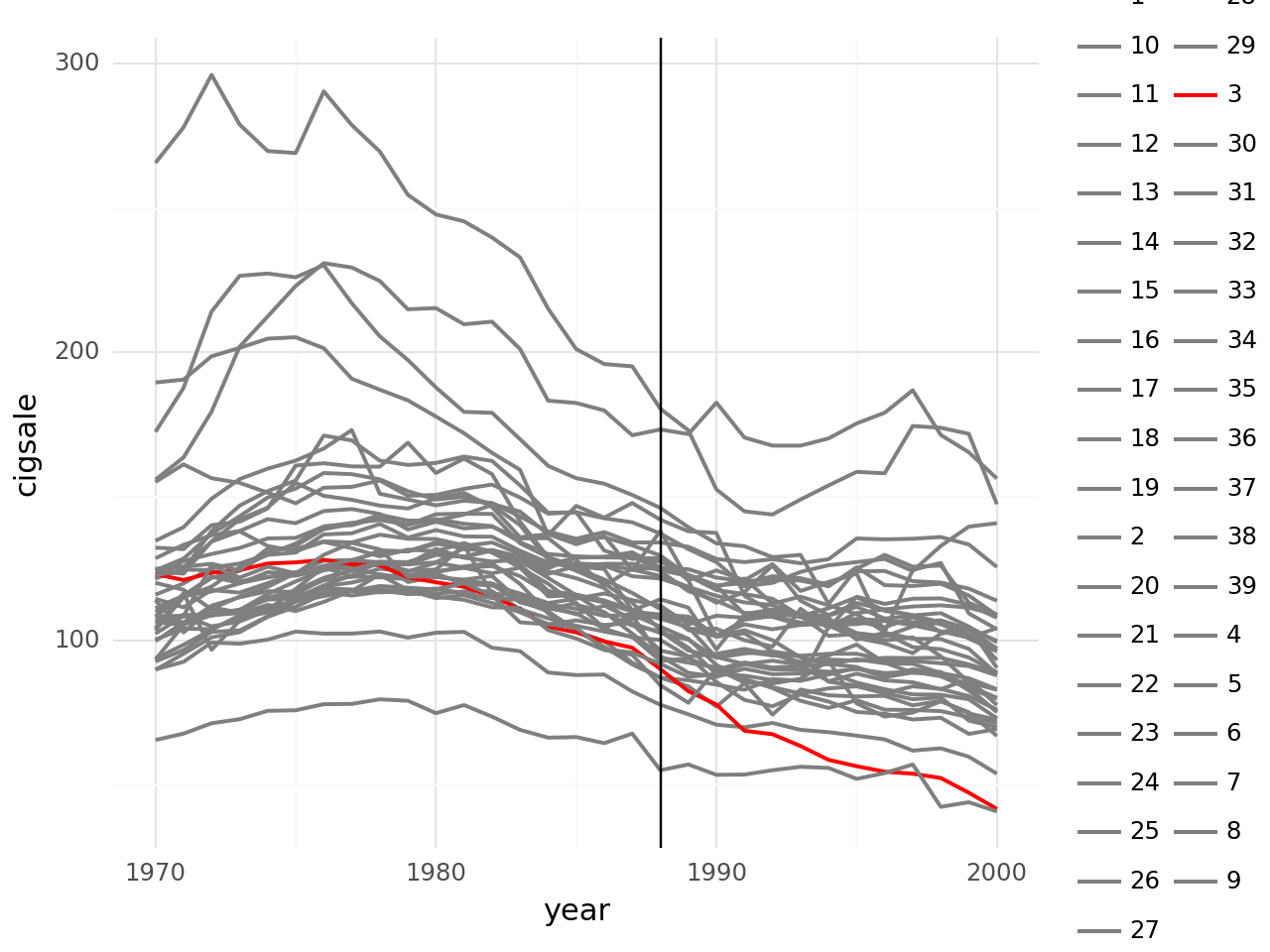
Na figura abaixo temos os dados de venda de pacotes de cigarros em 39 estados. Podemos verificar a série representada pela California em vermelho. De fato, caso quiséssemos avaliar o efeito da política após a sua implementação no estado (marcado pela linha vertical) teríamos dificuldades na comparação, afinal, não saberíamos de fato se a queda foi provocada (ou pelo menos sua magnitude) pela Lei Anti Fumo.
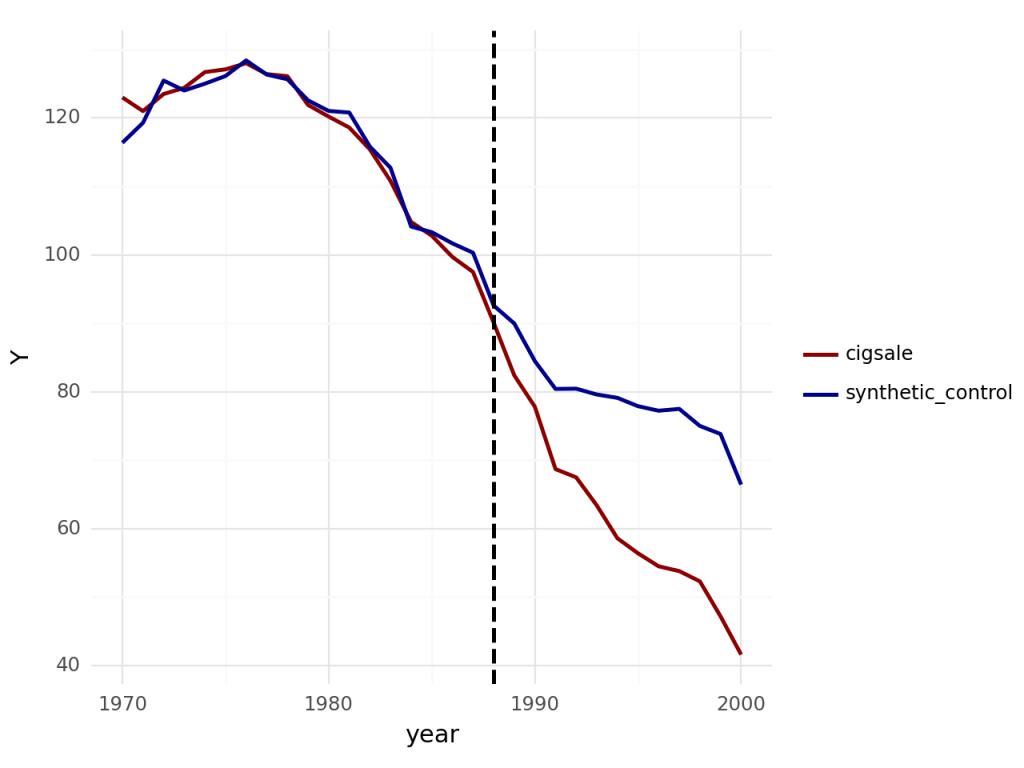
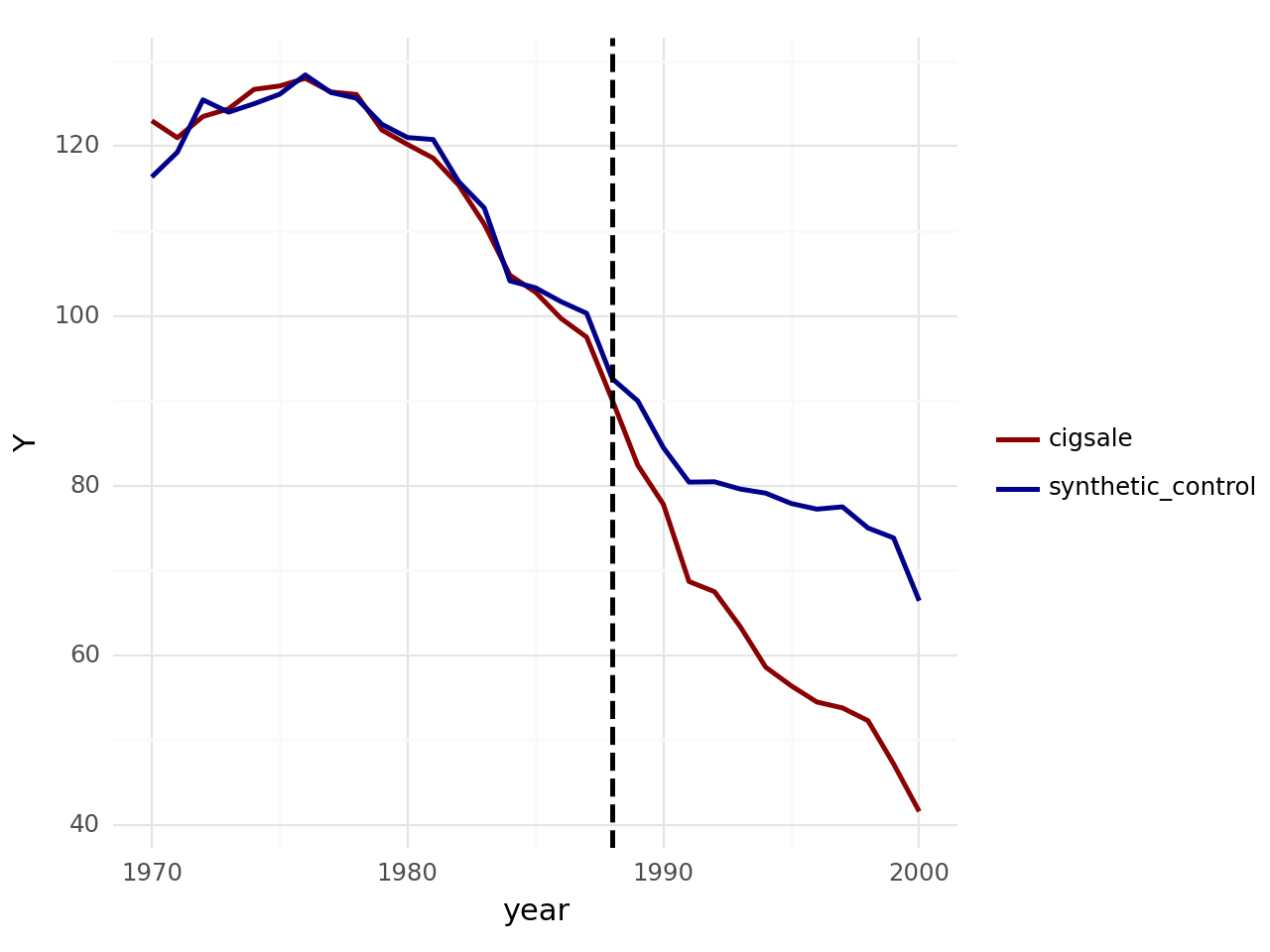
Faz-se necessário portanto o uso do Controle Sintético para criar California Sintético baseando-se nos dados agregados das demais entidades federativas. Abaixo, o resultado Controle Sintético (em azul) comparado com os dados reais. Vemos que de fato as trajetórias são parecidas antes da linha vertical, e a clara mudança após a implementação da política.
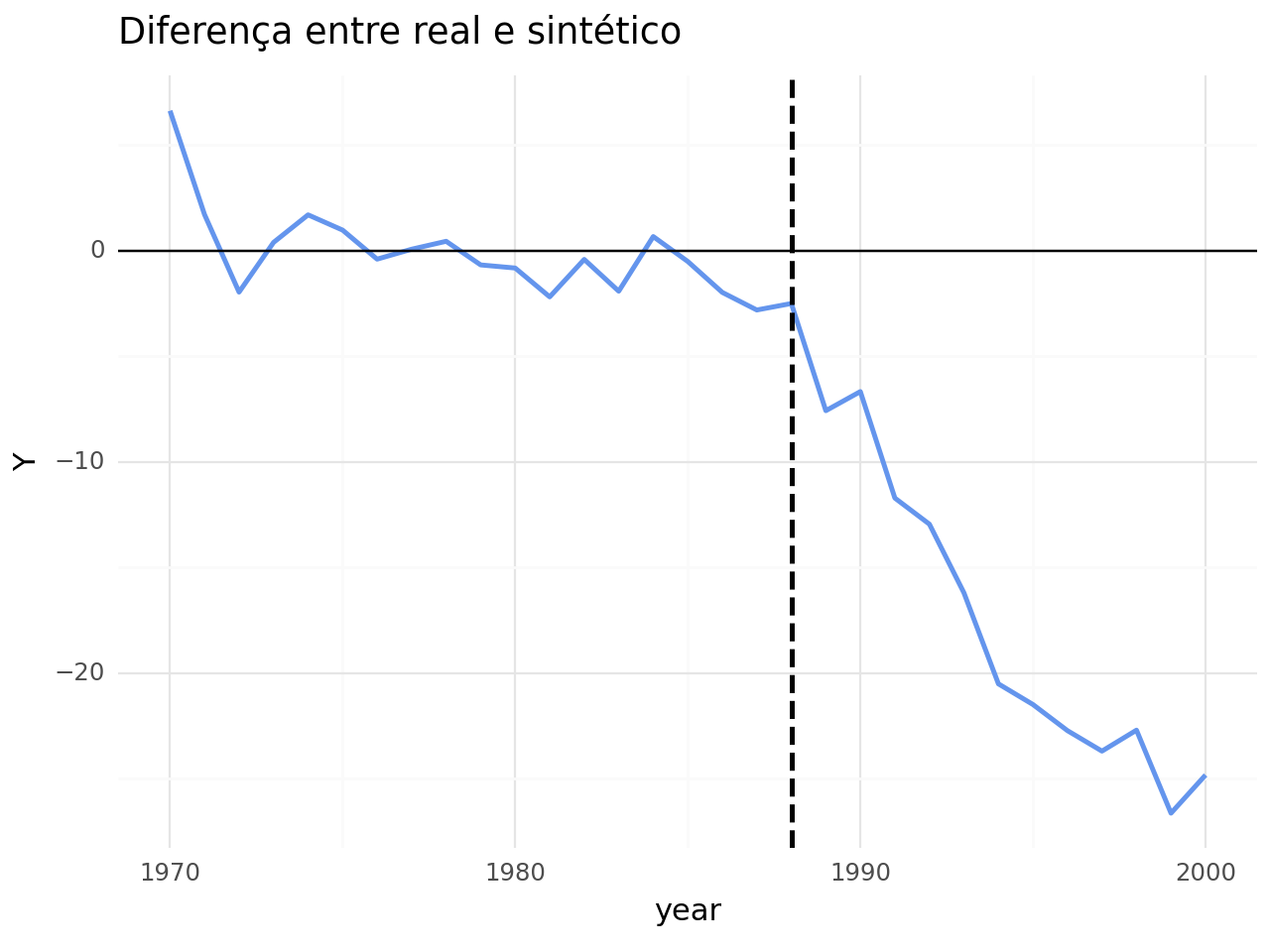
Com o objetivo de compreender qual o efeito na venda de cigarros provocado pela intervenção podemos, através do gráfico abaixo, verificar a diferença de valores de ambas as séries. Os valores negativos significam que houve de fato um efeito negativo da política sobre a venda de cigarros.
Referências
Abadie, Alberto, Alexis Diamond, e Jens Hainmueller. 2010. «Synthetic control methods for comparative case studies: Estimating the effect of California’s tobacco control program». Journal of the American statistical Association 105 (490): 493–505.
Arkhangelsky, Dmitry, Susan Athey, David A Hirshberg, Guido W Imbens, e Stefan Wager. 2019. «Synthetic difference in differences». National Bureau of Economic Research.