Experimento STAR
Em um experimento americano chamado STAR, iniciado em 1985 e com duração de quatro anos, os jovens alunos que iniciaram o jardim de infância e seus professores foram aleatoriamente alocados em três grupos possíveis:
- Grupo 1 - turmas com 22-25 alunos
- Grupo 2 - turmas com 13-17 alunos
- Grupo 3 - turmas com 22-25 alunos, mas com um auxiliar de ensino em tempo integral.
O experimento custou 12 milhões de dólares e envolveu cerca de 6.000 alunos por ano, para um total de 11.600 alunos de 80 escolas. Cada escola era obrigada a ter pelo menos uma turma de cada tipo de tamanho acima, e a distribuição aleatória acontecia no nível da escola. No final de cada série escolar (jardim de infância e séries 1 a 3), os alunos receberam um teste padronizado. Os resultados, sumarizados por (Krueger 1999), indicaram que alunos de salas menores tiveram desempenho melhor e os alunos do grupo 3 não tiveram desempenho diferente dos alunos do grupo 1.
Replicando o experimento STAR para o Piauí
- ID da criança
- Variável binária de gênero, 1 se for menina e 0, se for menino
- Variável binária de raça, 1 se for branco, 0 se não for
- ID da escola
- Experiência do professor
- Nome do município
- PIB do município
- As variáveis de tratamento
- A variável de nota na prova
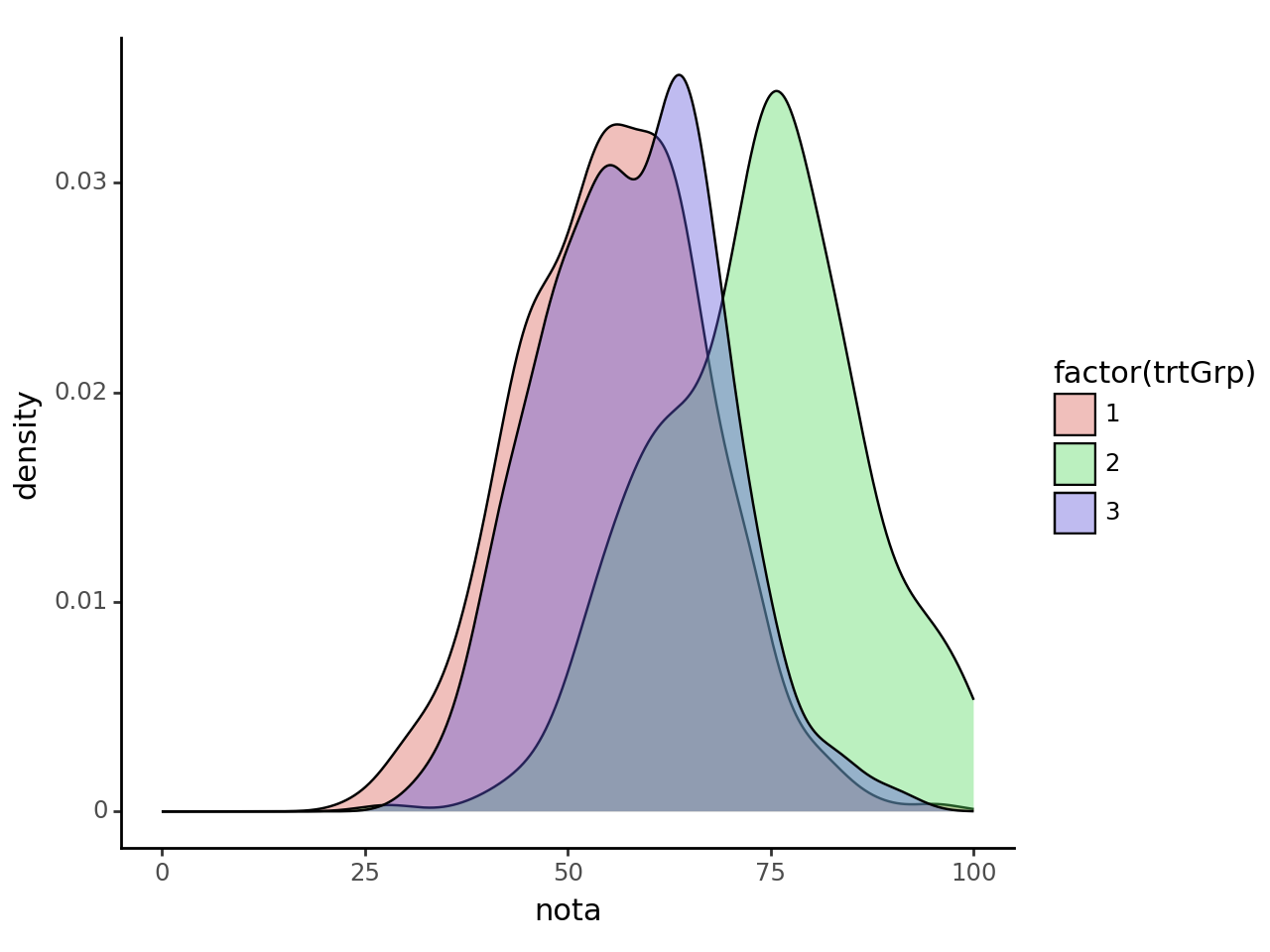
Primeiramente, podemos realizar uma comparação visual da distribuição das notas entre os grupos. De modo semelhante ao estudo original, o grupo 2, que representa os alunos que ficaram nas menores salas, também teve média maior do que os outros dois grupos.
Para atestar o efeito da política, podemos rodar uma regressão dos diferentes tratamentos sobre a nota. Perceba que o tratamento é representa por variáveis binárias exclusivas, ou seja, o mesmo aluno só pode ter recebido uma das opções de sala. Veja que assim, nosso grupo de “controle”, que é o grupo 1, não recebe uma variável binária, por conta que isso acarretaria em multicolineariedade.
Assim, de forma semelhante a (Krueger 1999) estimamos quatro especificações de regressão diferentes. A primeira recebe apenas as duas variáveis binárias de tratamento. A segunda inclui efeitos fixos da escola. A terceira acrescenta algumas variáveis de controle. A última, não presente no estudo original, visa mostrar um possível efeito da interação entre o tratamento e a experiência do professor.
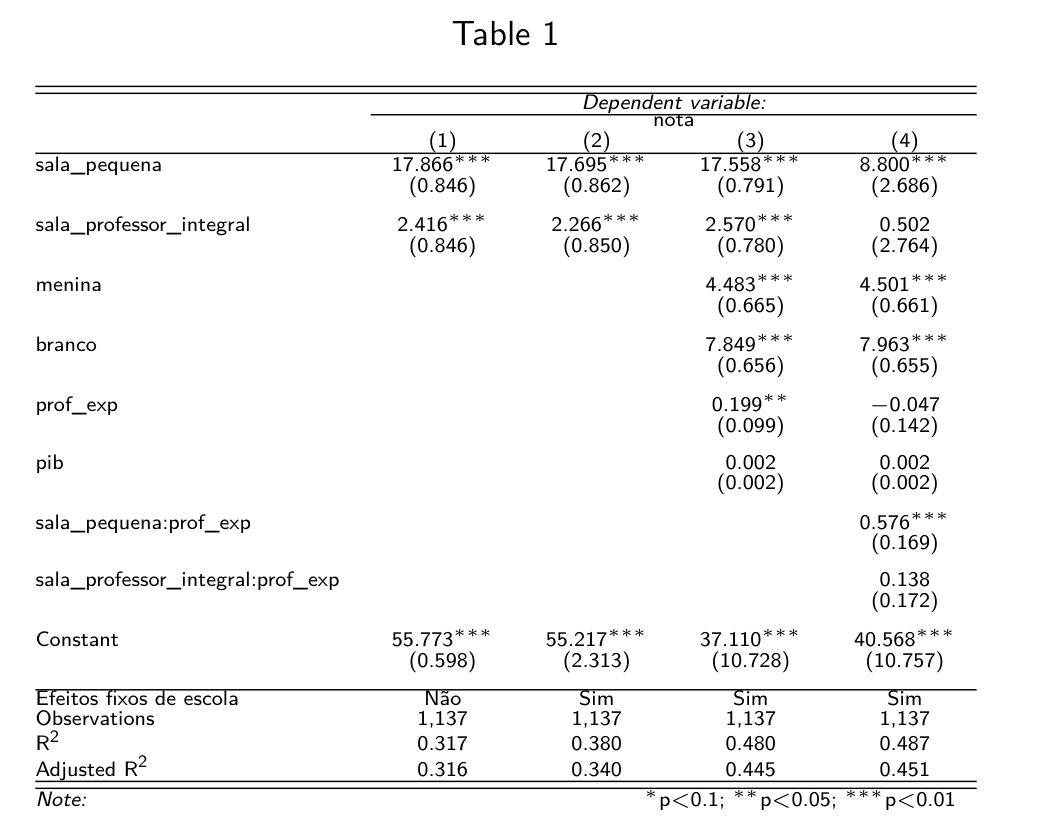
Os resultados encontrados se assemelham aos do estudo original. O efeito do tratamento no grupo 2 é igual a cerca de 17 pontos na prova. Já o tratamento 3 também apresenta efeito estatísticamente significante, mas de menor magnitude. A especificação com interação entre a o tratamento do grupo 2 e a experiência do professor mostrou-se positiva e significante. Ou seja, professores mais experientes melhoraram o desempenho de salas com menos alunos.
Este exemplo é importante para mostrar o poder dos estudos que envolvem RCT. Com um bom desenho de metodologia, é possível fazer inferência estatística causal sem utilizar métodos complexos ou hipóteses mais frágeis. Entretanto, o custo associado pode ser proibitivo.
Referências
Krueger, Alan B. 1999. «Experimental estimates of education production functions». The quarterly journal of economics 114 (2): 497–532.

