No mês de dezembro, iremos lançar uma nova versão do Clube do Código. O projeto de compartilhamento de códigos da Análise Macro vai avançar para uma versão 2.0, que incluirá a existência de uma comunidade no Telegram/Whatsapp, de modo a reunir os membros do Novo Clube, compartilhando com eles todos os códigos dos nossos posts feitos aqui no Blog, exercícios de análise de dados de maior fôlego, bem como tirar dúvidas sobre todos os nossos projetos e Cursos Aplicados de R.
Para ilustrar o que vamos compartilhar lá nesse novo ambiente, vou publicar aqui nos próximos dias alguns dos nossos exercícios completos de análise de dados. Esses exercícios fazem parte do repositório atual do Clube, que irá migrar para o novo projeto. Além de todos os exercícios existentes, vamos adicionar novos exercícios e códigos toda semana, mantendo os membros atualizados sobre o que há de mais avançado em análise de dados, econometria, machine learning, forecasting e R.
Hoje, vou mostrar como é possível utilizar a já famosa ferramenta Google Trends dentro do R. O Google Trends é uma ferramenta do Google que mostra os mais populares termos buscados em um passado recente. A ferramenta apresenta gráficos com a frequência em que um termo particular é procurado em várias regiões do mundo, e em vários idiomas.
Para ilustrar o seu uso com o R, vamos ver como está o comportamento das buscas pelas palavras "seguro desemprego" e "emprego". Como sempre, o script começa carregando alguns pacotes.
library(gtrendsR) library(tidyverse) library(lubridate) library(scales)
Na sequência, usamos a função gtrends do pacote gtrendsR para buscar as palavras que queremos.
data_gtrends = gtrends(keyword = c("seguro desemprego", 'emprego'),
geo = "BR", time='all', onlyInterest=TRUE)
Fazemos algum tratamento dos dados que pegamos com o código abaixo.
seguro_desemprego = data_gtrends$interest_over_time %>% filter(keyword == 'seguro desemprego') %>% mutate(mes = floor_date(date, "month")) %>% group_by(mes) %>% summarize(interesse = mean(hits)) %>% mutate(date = as.Date(mes)) %>% select(date, interesse)
A seguir, um gráfico com os dados resultantes.
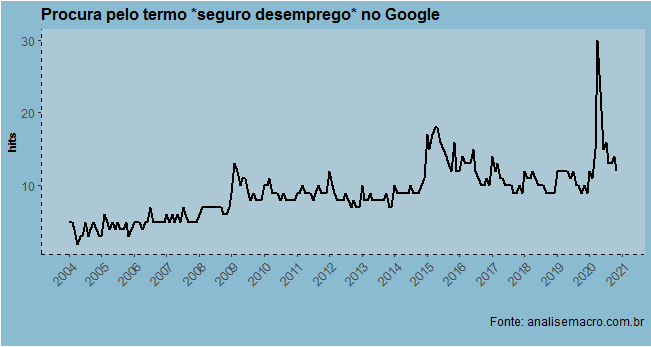
O Google Trends é uma excelente ferramenta para capturar tendências. No exemplo acima, podemos ver que os pedidos de seguro-desemprego explodiram com a eclosão da pandemia e vem se reduzindo desde então.
______________________
(*) Cadastre-se aqui na nossa Lista VIP para receber um super desconto na abertura das Turmas 2021.


