Antes de desenvolver bons modelos preditivos é necessário organizar e conhecer muito bem os dados. Neste artigo, damos algumas dicas de recursos, como gráficos, análises e estatísticas, que podem ser usados para melhorar o entendimento sobre os dados usando Python.
Aqui vamos usar como exemplo um base de dados desenvolvida no curso de Previsão Macroeconômica usando Python e IA, tomando como objetivo de análise a variável da taxa de inflação, medida pelo IPCA.
Primeiro, carregamos as bibliotecas e a base de dados:
ipca ibc_br ... inpc ipca_15
data ...
2004-01-01 0.76 -0.011597 ... 0.83 0.68
2004-02-01 0.61 0.008685 ... 0.39 0.90
2004-03-01 0.47 0.118665 ... 0.57 0.40
2004-04-01 0.37 -0.042133 ... 0.41 0.21
2004-05-01 0.51 -0.012466 ... 0.40 0.54
[5 rows x 93 columns]Dica 01: analise a evolução temporal dos dados
Será que os dados possuem alguma tendência? Algum valor extremo? Os dados são ruidosos ou suaves? Todas estas questões podem ser analisadas através de um gráfico de linha:
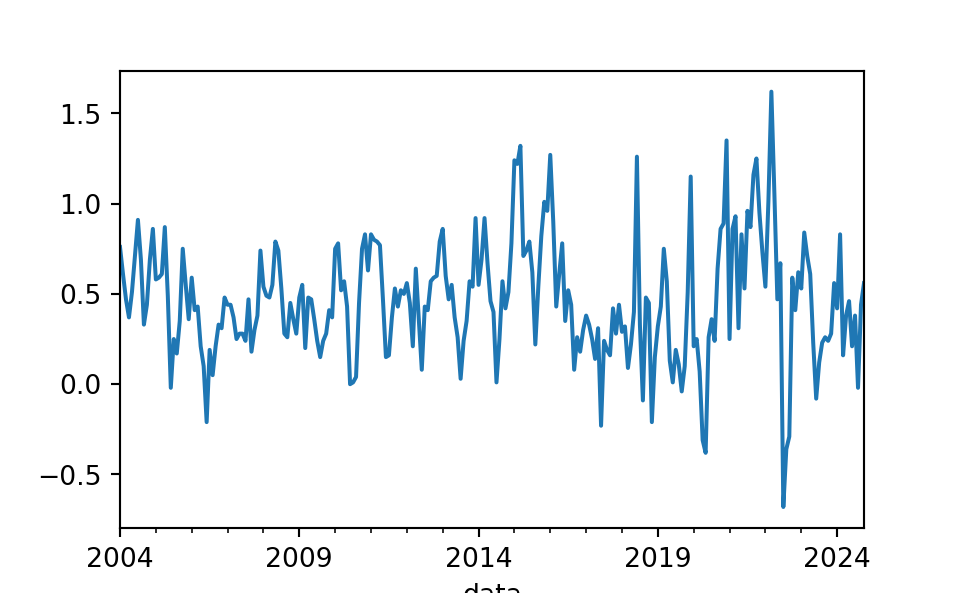
Dica 02: desagregue os dados em pequenas partes
Quais são as pequenas “peças” que formam a variável? Uma decomposição entre tendência, sazonalidade e ruído pode ajudar a analisar esta questão:
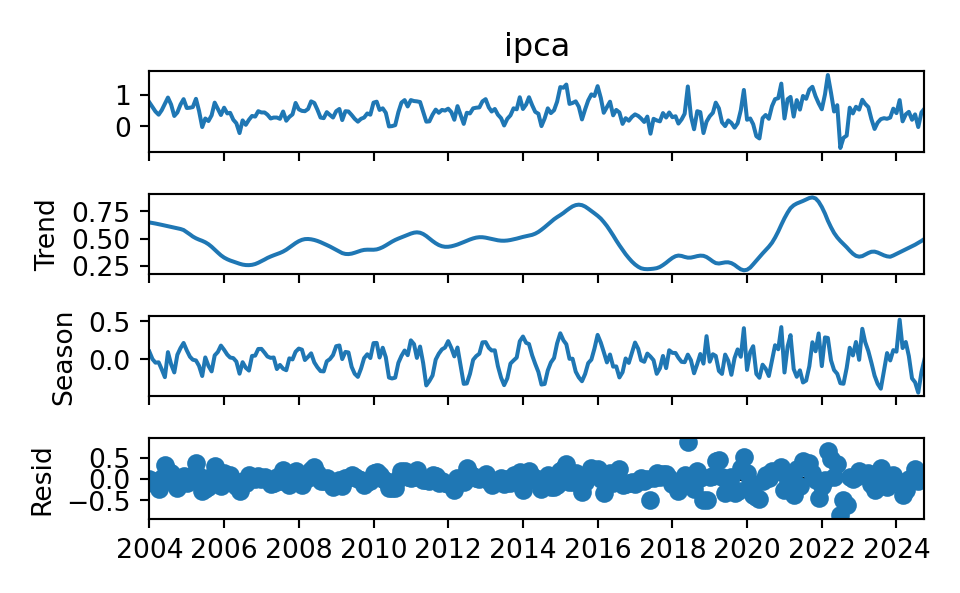
Dica 03: analise a influência do passado
O quão os dados passados influenciam os dados do presente e futuro? Como quantificar essa relação? O cálculos das funções de autocorrelação podem ajudar a entender estas características:
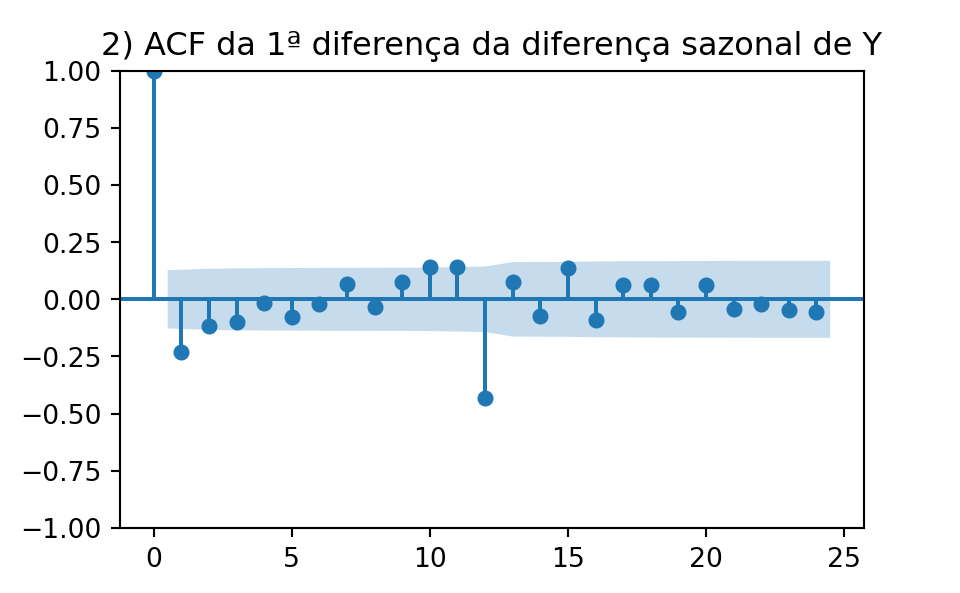
Dica 04: analise a relação entre os dados
Por fim, qual é a relação entre as variáveis da tabela? A relação é forte, nula ou fraca? A relação é positiva ou negativa? Estas questões podem ser analisadas através do cálculo do coeficiente de correlação:
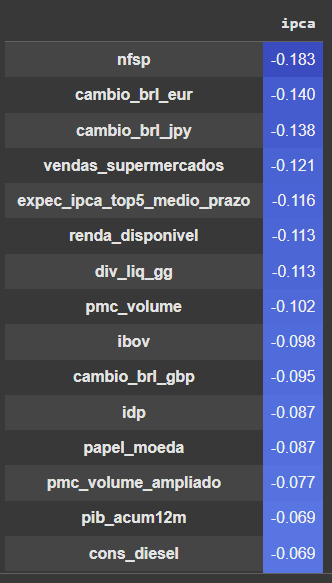
Conclusão
Antes de desenvolver bons modelos preditivos é necessário organizar e conhecer muito bem os dados. Neste artigo, damos algumas dicas de recursos, como gráficos, análises e estatísticas, que podem ser usados para melhorar o entendimento sobre os dados usando Python.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, conheça o Clube AM clicando aqui.

