Como dar novos nomes significativos para as colunas em uma tabela de dados usando Python? Neste tutorial mostramos os métodos de renomeação de colunas disponíveis na biblioteca pandas, que tem como vantagem sua sintaxe simples e prática.
A renomeação de colunas é uma etapa presente em quase todo tratamento/limpeza de dados. Afinal, com tabelas de dados cada vez maiores, é necessário adequar e padronizar os nomes das colunas para a análise dos dados. Sendo assim, vamos a um exemplo prático.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Dados de exemplo
Primeiro, coletamos online uma tabela de dados CSV de exemplo. A fonte dos dados é o Banco Central do Brasil e para coletar os dados também usamos a biblioteca pandas. Abaixo as últimas linhas presentes na tabela:
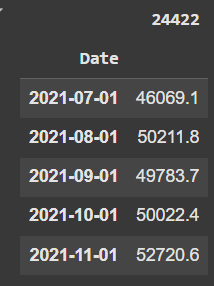
Como renomear colunas?
Para renomear colunas usamos a função rename() através da sintaxe tabela.rename(columns = {"nome_anterior": "novo_nome"). Por exemplo, para renomear uma única coluna:
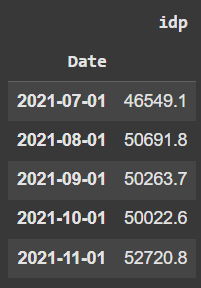
Seguindo a mesma sintaxe, podemos renomear quantas colunas desejarmos:
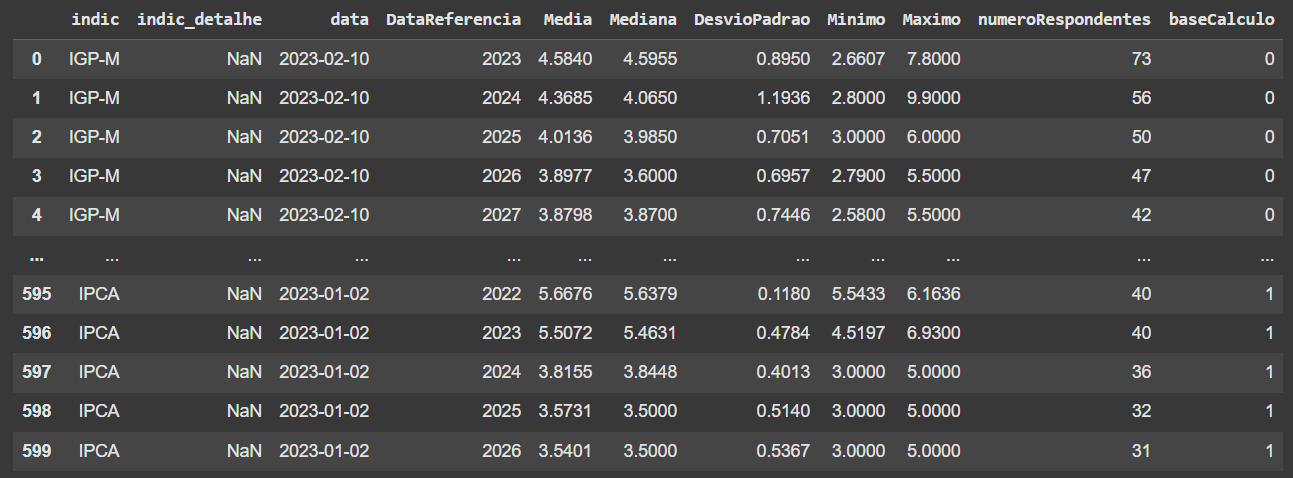
Conclusão
Como dar novos nomes significativos para as colunas em uma tabela de dados usando Python? Neste tutorial mostramos os métodos de renomeação de colunas disponíveis na biblioteca pandas, que tem como vantagem sua sintaxe simples e prática.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

