Com o R, é possível acessar diversas bases de dados e baixar o que precisa diretamente para o RStudio. Um exemplo disso é a base de dados do Banco Mundial. Nessa Dica de R - sim, volto a publicar toda quarta-feira uma dica de R aqui no Blog - vamos mostrar como pegar os dados sobre poupança e taxa de juros de diversos países com o pacote WDI. Como de praxe, o código começa carregando alguns pacotes que utilizaremos.
library(WDI) library(ggplot2) library(ggrepel) library(png) library(grid)
A seguir, podemos pegar os dados que precisamos.
interest = WDI(country='all',
indicator = 'FR.INR.RINR',
start=2019, end=2019)
saving = WDI(country = 'all',
indicator = 'NY.GNS.ICTR.ZS',
start=2019, end=2019)
data = cbind(interest, saving)
data = data[complete.cases(data),]
data$iso2c = data$iso2c = data$country = data$year = data$year = NULL
colnames(data) = c('interest', 'country', 'saving')
data = subset(data, interest>0 & saving>0)
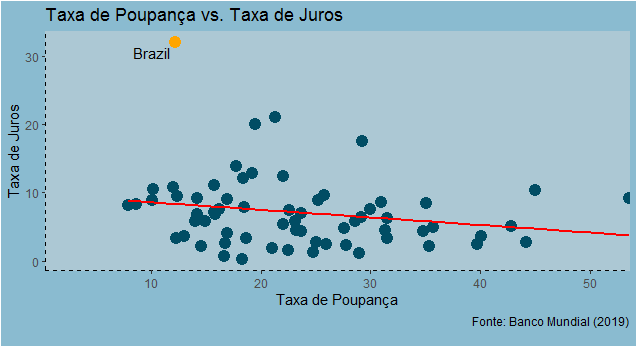
Um gráfico com os dados é posto abaixo.
______________
Para acessar os códigos completos desse exercício, é preciso fazer parte do Clube AM.


