PIB per capita não é tudo, mas é quase tudo. As manifestações no Chile têm levado alguns economistas a fazerem críticas ao modelo liberal implementado por lá há algumas décadas. Cumprindo a missão desse espaço, vou mostrar novamente a base de dados do Maddison Project, que conta com um pacote de mesmo nome no R. Abaixo, carregamos os pacotes utilizados para criar um gráfico comparando o pib per capita do Brasil com o do Chile.
library(maddison) library(ggplot2) library(scales) library(png) library(grid) library(tidyverse)
Uma vez carregado o pacote maddison, posso pegar os dados dos dois países.
df = subset(maddison, year>='1974-01-01' &
iso2c %in% c('BR','CL'))
E agora construo um data frame com a razão entre o pib per capita dos dois países.
df2 = data.frame(date = df$year[df$country=='Chile'], razao = df$gdp_pc[df$country=='Chile']/ df$gdp_pc[df$country=='Brazil'])
Por fim, gero o gráfico abaixo...
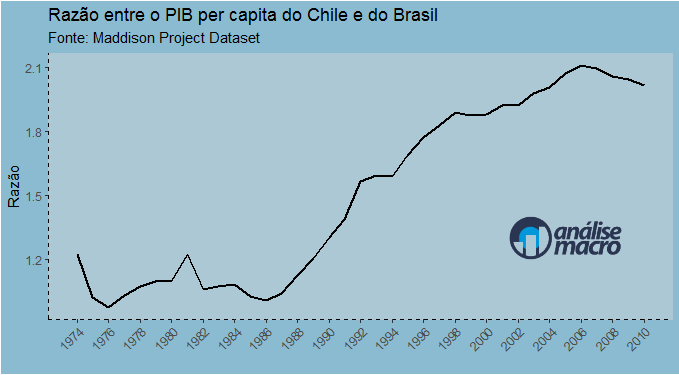
Pois é, o Brasil perde de goleada para o modelo chileno...
_________________________________________


