Quem trabalha com modelagem costuma ter que escrever equações de forma bastante rotineira. Para exercícios simples, é bastante tranquilo escrever uma ou outra equação em  . O problema é quando você tem muitas equações no mesmo documento. Nessa Dicas de R - disponível toda quarta-feira aqui no blog da AM -vamos divulgar um novo pacote, o equatiomatic, que trata justamente desse problema.
. O problema é quando você tem muitas equações no mesmo documento. Nessa Dicas de R - disponível toda quarta-feira aqui no blog da AM -vamos divulgar um novo pacote, o equatiomatic, que trata justamente desse problema.
library(equatiomatic) library(palmerpenguins) library(ggplot2) library(latex2exp)
Usei a própria documentação do pacote para exemplificar o seu uso. Primeiro, rodamos um lm qualquer como o abaixo.
m <- lm(bill_length_mm ~ bill_depth_mm + flipper_length_mm, penguins)
Agora, basta usar a função extract_eq para que tenhamos acesso à equação.
extract_eq(m)
(1) 
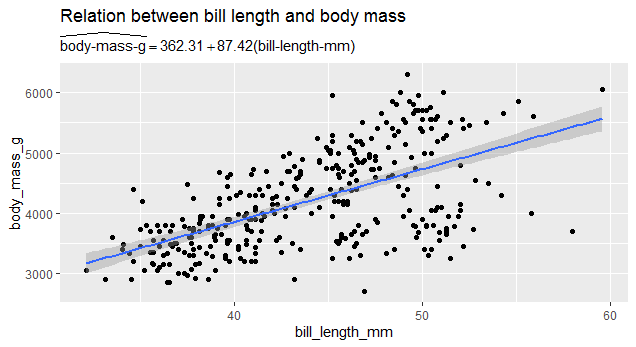
A equação extract_eq contém, inclusive, alguns argumentos que permitem a customização da equação a ser exibida. Para além disso, outra coisa legal do pacote é poder plotar gráficos com equações, como abaixo.
# Fit an lm model
m <- lm(body_mass_g ~ bill_length_mm, penguins)
# extract equation with `ital_vars = TRUE` to avoid the use of `\operatorname`
m_eq <- extract_eq(m, use_coef = TRUE, ital_vars = TRUE)
# swap escaped underscores for dashes
prep_eq <- gsub("\\\\_", "-", m_eq)
# swap display-style
prep_eq <- paste("$", as.character(prep_eq), "$", sep = "")
# Plot
ggplot(penguins, aes(x = bill_length_mm, y = body_mass_g)) +
geom_point() +
geom_smooth(method = "lm") +
labs(title = "Relation between bill length and body mass",
subtitle = TeX(prep_eq))
____________
Um pdf e um script com todo o código desse exercício está disponível para os membros do Clube AM.


