As manifestações no Chile não param de produzir textos pelas redes sociais. A última que vi foi a relação entre o preço do cobre e o pib per capita do país vizinho. Resolvi dar uma olhada nas séries e alertar para alguns problemas nessa relação. Os dados utilizados no exercício são do FMI e estão disponíveis no final do post. Eu os importo com o código abaixo para o R.
library(readxl)
library(forecast)
library(xts)
library(ggplot2)
library(stargazer)
cobre = read_excel('cobre.xlsx', col_types = c('date', 'numeric'))
pib = window(ts(read_excel('pib.xlsx')[,-1], start=1960, freq=1),
start=1980)
A série de preço do cobre que consegui é mensal, então de modo a comparar com o pib per capita do Chile, é preciso anualizá-la. Faço isso abaixo, já pegando uma janela que eu possa comparar com o pib do Chile.
cobre = xts(cobre$cobre, order.by = cobre$date) cobre = apply.yearly(cobre, FUN=mean) cobre = window(cobre, start='1980-12-01', end='2018-12-01')
Com os dados devidamente comparáveis, faço um gráfico de correlação como abaixo.
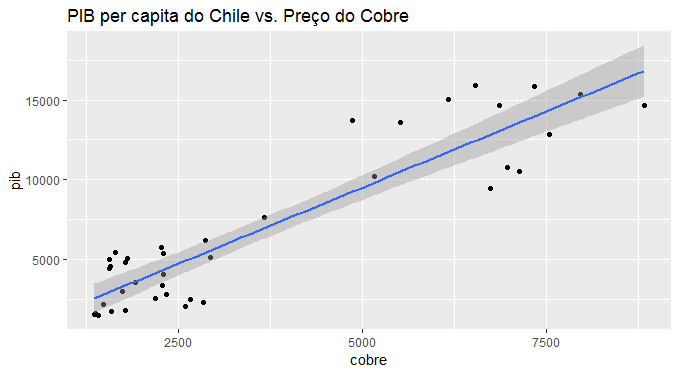
A correlação entre as séries é altamente positiva, de 0,91. Os gráficos das séries são colocados em seguida.
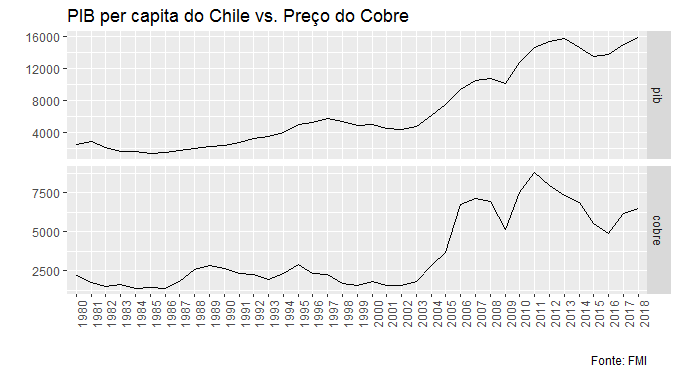
Como podemos ver, as séries não são estacionárias. Isso, entretanto, não impede que possamos trabalhar com elas em nível, desde que exista o que chamamos de relação de longo prazo entre as mesmas. No jargão econométrico, dizemos que existe uma relação de longo prazo entre duas séries não estacionárias se as mesmas cointegram. Há algumas formas de verificar isso. Talvez a mais simples seja rodar uma regressão entre elas e verificar se os resíduos são estacionários. Se for o caso, é possível dizer que as séries cointegram. Abaixo, coloco o output de uma regressão entre o pib per capita do Chile e o preço do cobre.
| Dependent variable: | |
| pib | |
| cobre | 1.916*** |
| (0.141) | |
| Constant | -77.583 |
| (606.886) | |
| Observations | 39 |
| R2 | 0.834 |
| Adjusted R2 | 0.829 |
| Residual Std. Error | 2,049.611 (df = 37) |
| F Statistic | 185.387*** (df = 1; 37) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 |
E agora, coloco um gráfico dos resíduos da regressão...
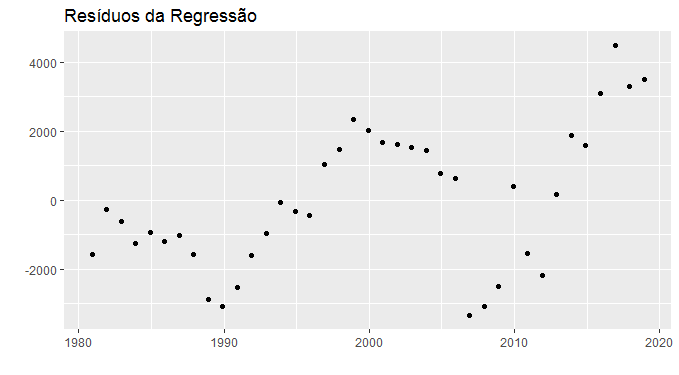
Como se vê, os resíduos da regressão estão longe de serem estacionários. O leitor mais interessado pode rodar um teste de raiz unitária sobre os mesmos. Assim, não podemos acreditar no output da regressão simplesmente porque os resultados são espúrios...
Por fim, outro alerta: não estou querendo dizer nada com esse exercício simples sobre a dependência ou não da economia chilena em relação ao cobre. Apenas que não podemos confiar em uma regressão entre o pib per capita do Chile contra o preço do Cobre... 😉
___________________________________________
(*) Quer aprender mais sobre séries temporais? Veja nosso Curso de Séries Temporais usando o R.
(**) As séries que utilizei podem ser baixadas aqui.


