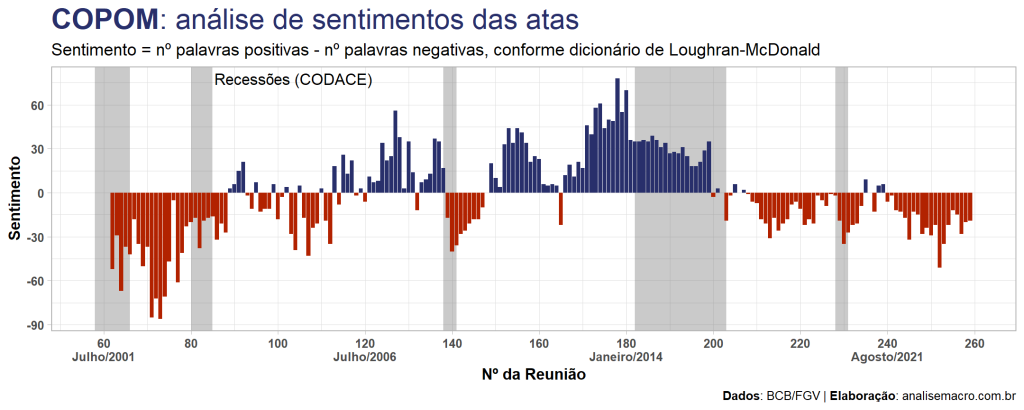
No exercício anterior, construímos um indicador que quantifica o sentimento proveniente das decisões de política monetária, implícito nas atas do COPOM. Hoje, avaliaremos se o indicador provê informações úteis para tomadores de decisão, seus pontos fortes e fracos, assim como sua interpretação prática.
Para obter o código deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Interpretação do indicador
O indicador de sentimentos aqui abordado foi construído pelo método de contagem de palavras positivas/negativas nos textos, com o auxílio do dicionário Loughran-McDonald. Dessa forma, o indicador assume valores inteiros, {..., -2, -1, 0, 1, 2, ...}, onde valores positivos indicam sentimos positivos, valores negativos indicam sentimentos negativos e valor igual a zero indica neutralidade. O sentimento é atribuído para cada texto (ata) e informa o líquido entre as classificações das palavras no texto (positivo - negativo), após uma série de pré-processamentos.
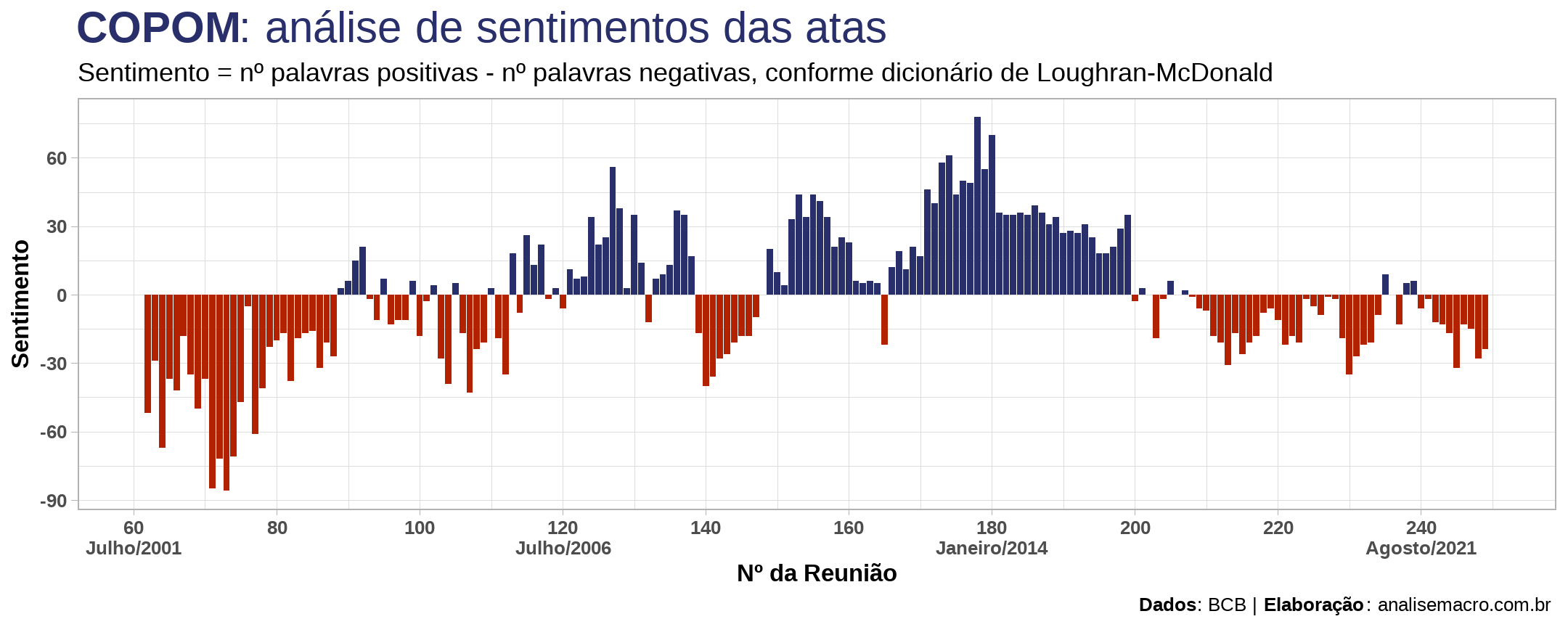
Sendo assim, quando vemos uma coluna em azul no gráfico anterior, podemos esperar que — lendo a ata desta reunião do COPOM — os diretores usaram palavras com sentimentos/emoções mais positivos do que negativos. Tomando como exemplo a coluna mais alta do gráfico, referente a reunião nº 178 de outubro/2013, nosso algoritmo encontrou 74 palavras negativas e 152 positivas, das quais algumas destas últimas são "fortalecimento", "melhora" e "progresso".
Seguindo esse raciocínio, as colunas em vermelho indicam mais palavras com sentimentos negativos do que positivos e as observações em que a coluna possui valor zero indicam o mesmo número de palavras positivas e negativas. Isso é tudo que você consegue interpretar deste indicador. Qualquer análise além disso está sujeita a viés do analista.
Portanto, vamos falar de vieses do indicador, seus pontos fortes e fracos.
Pontos fortes e fracos
O indicador produzido é um trabalho inicial e embrionário, isto posto, destacamos brevemente algumas considerações pertinentes sobre o seu uso.
Pontos fortes:
- Fácil interpretação;
- Algoritmo simples de implementar e automatizável;
- Não exige uso de modelos/estatística;
- Apelo visual/facilidade de comunicar resultados.
Pontos fracos:
- O número de palavras total em cada texto é desconsiderado;
- O contexto da palavra não é levado em consideração;
- O método não considera dependências temporais;
- O indicador é agnóstico ao ciclo econômico.
Uma crítica que pode surgir sobre o indicador exposto é a sua divergência em relação ao ciclo econômico, conforme pontuado acima, especialmente na crise de 2014-16. O gráfico abaixo, atualizado com áreas sombreadas indicando períodos datados como recessão da economia brasileira pelo CODACE/FGV, pode ajudar a entender.
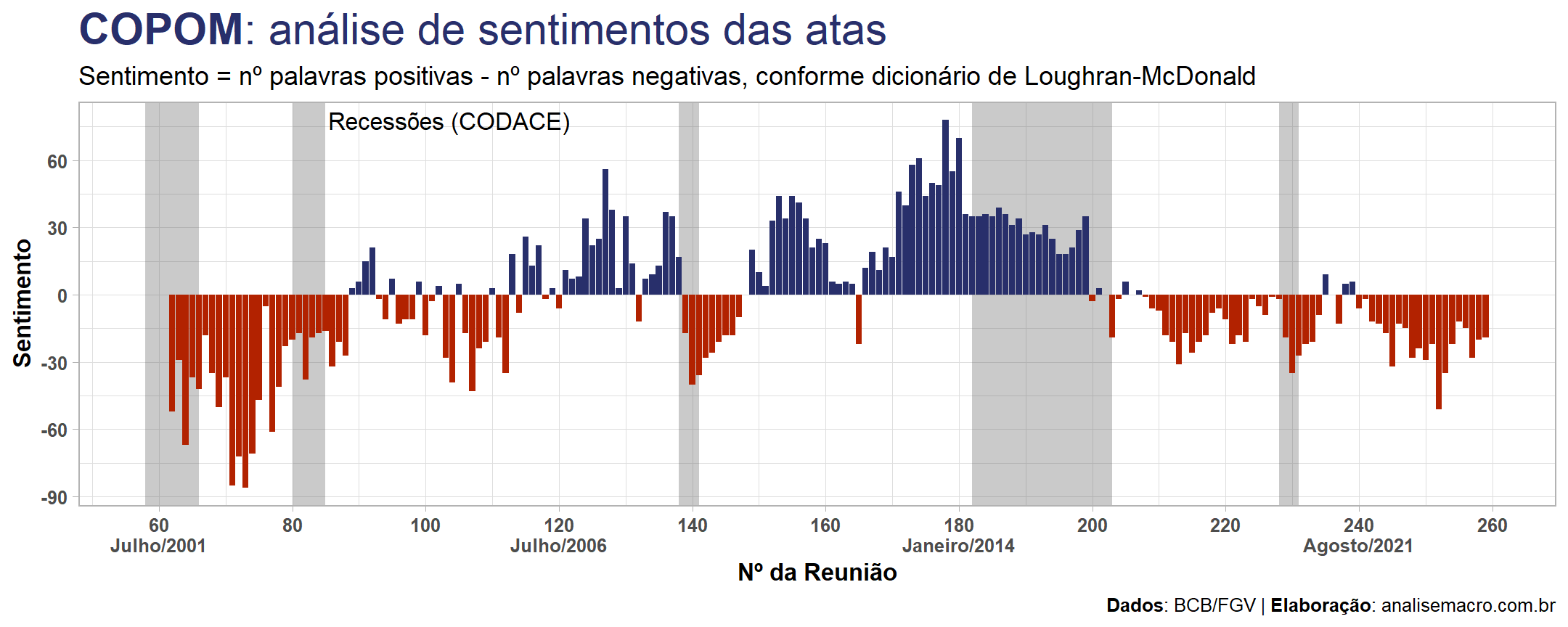
Uma expectativa razoável, para a maioria das pessoas, em relação ao indicador de sentimentos é a de que períodos recessivos estejam associados a sentimentos negativos. Nos períodos prévios a crise de 2014-16 essa relação parece se manifestar relativamente bem, ao passo que na crise a relação inverte-se. E isso pode ser resultado da simplicidade "em excesso" do indicador, conforme considerações pontuadas acima. Em outras palavras, há certamente espaço para aperfeiçoar o indicador.
Em suma, o procedimento quantitativo empregado simplifica bastante a leitura dos comunicados de política monetária, mas perde-se informações valiosas no processo.
Saiba mais
Códigos de replicação em R estão disponíveis para membros do Clube AM da Análise Macro. Se você achou o tema interessante, confira o próximo exercício onde trataremos da relação entre o indicador de sentimentos e variáveis macroeconômicas brasileiras.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

