O que informações textuais podem revelar sobre a situação da economia? Como transformar palavras em estatísticas e obter insights? Há algo informativo nas entrelinhas das atas do COPOM? Como usar Machine Learning para interpretar os comunicados da autoridade monetária? Neste exercício, damos continuidade aos posts sobre Natural Language Processing (NLP) demonstrando a aplicação da técnica de topic modeling com as atas do COPOM.
Para ter acesso a exercícios diários de análise de dados como esse, com vídeos, scripts, material complementar e suporte completo, conheça o Clube AM.
O que é topic modeling?
No contexto de text mining, nossos dados geralmente são coleções de documentos textuais, como postagens em blogs ou artigos de notícias, que gostaríamos de dividir em grupos para que possamos entendê-los separadamente. A modelagem de tópicos (topic modeling) é um método de Machine Learning para classificação não supervisionada de tais documentos, semelhante ao agrupamento em dados numéricos, que encontra grupos de observações mesmo quando não temos certeza do que estamos procurando. Em outras palavras, é um método para classificar/mapear textos em um número k de tópicos.
O modelo LDA
O modelo Latent Dirichlet Allocation (LDA) é um método probabilístico particularmente popular para estimar um modelo de tópico. Sem mergulhar na matemática por trás do modelo, podemos entendê-lo como sendo guiado por dois princípios:
- Cada documento textual é uma mistura de tópicos: imagine que cada documento pode conter palavras de vários tópicos em proporções particulares. Por exemplo, em um modelo de dois tópicos, poderíamos dizer “Documento 1 é 90% tópico A e 10% tópico B, enquanto o Documento 2 é 30% tópico A e 70% tópico B”.
- Cada tópico é uma mistura de palavras: por exemplo, poderíamos imaginar um modelo de dois tópicos para as notícias vinculadas na mídia brasileira, com um tópico para “política” e outro para “entretenimento”. As palavras mais comuns no tópico de política podem ser “presidente”, “congresso” e “governo”, enquanto que o tópico de entretenimento pode ser composto por palavras como “filmes”, “televisão” e “ator”. É importante ressaltar que as palavras podem ser compartilhadas entre os tópicos, ou seja, uma palavra como “dinheiro” pode aparecer em ambos os tópicos.
O modelo LDA estima as probabilidades de ambos ao mesmo tempo: encontrar a mistura de palavras que está associada a cada tópico, assim como também determinar a mistura de tópicos que descreve cada documento. Em nossa análise, um documento corresponde a cada texto que será extraído de cada ata do COPOM.
Existem várias implementações desse algoritmo, aqui exploraremos a abordagem que usa iterações de amostragem de Gibbs. Em resumo, construiremos esta análise:
Para ter acesso a exercícios diários de análise de dados como esse, com vídeos, scripts, material complementar e suporte completo, conheça o Clube AM.
Pacotes
Para reproduzir o exercício a seguir você precisará dos seguintes pacotes de R:
# Carregar pacotes/dependências library(jsonlite) # CRAN v1.7.3 library(purrr) # CRAN v0.3.4 library(dplyr) # CRAN v1.0.8 library(pdftools) # CRAN v3.1.1 library(magrittr) # CRAN v2.0.2 library(stringr) # CRAN v1.4.0 library(tidyr) # CRAN v1.2.0 library(lubridate) # CRAN v1.8.0 library(forcats) # CRAN v0.5.1 library(ggplot2) # CRAN v3.3.5 library(ggtext) # CRAN v0.1.1 library(tsibble) # CRAN v1.1.1 library(scales) # CRAN v1.1.1 library(tm) # CRAN v0.7-8 library(tidytext) # CRAN v0.3.2 library(topicmodels) # CRAN v0.2-12
Os dados
Como insumo para o modelo, precisamos dos textos das atas do COPOM, disponibilizados em arquivos PDFs no site do BCB. Conforme procedimentos já detalhados em um post anterior (clique aqui), o código abaixo importa os textos brutos e os salva em um objeto tabular:
# URL para página com JSON dos links das atas do COPOM
url_atas <- paste0(
"https://www.bcb.gov.br/api/servico/sitebcb/copomminutes/",
"ultimas?quantidade=2000&filtro="
)
# Web scraping para importar texto dos PDFs das atas
raw_copom <- jsonlite::fromJSON(url_atas) %>%
purrr::pluck("conteudo") %>%
dplyr::as_tibble() %>%
dplyr::select(
"date" = "DataReferencia",
"meeting" = "Titulo",
"url" = "Url",
) %>%
dplyr::mutate(url = paste0("https://www.bcb.gov.br", url)) %>%
dplyr::mutate(text = purrr::map(URLencode(url), pdftools::pdf_text))
Pré-processamento
Os dados importados vêm recheados de possíveis problemas se fossem diretamente utilizados no modelo LDA. Desta forma, é necessário realizar alguns tratamentos, que se resumem a:
- Determinar amostra de atas do COPOM de interesse (50ª ata/agosto de 2000 em diante);
- Remover caracteres e códigos indesejados no meio das palavras;
- Remover pontuações e números;
- Remover as stops words (palavras sem valor semântico como "que", "de", "e", etc.);
- Aplicar o processo de stemming: transformar várias palavras que significam a mesma coisa em apenas uma palavra. Por exemplo, palavras como “economia”, “economista” e “economizar” se tornam “economi”.
# Limpeza e pré-processamento dos textos das atas
copom_clean <- raw_copom %>%
dplyr::filter(
# Remover o que não é reunião do Copom e reuniões nº 42 a 49
!meeting == "Changes in Copom meetings",
!stringr::str_detect(string = meeting, pattern = "^4[2-9]")
) %>%
# Transforma cada elemento (página) do vetor textual das atas
# um linha no data.frame
tidyr::unnest(text) %>%
dplyr::group_by(meeting) %>%
dplyr::mutate(
# Trata end-of-line/carriage return dos textos
text = stringr::str_split(string = text, pattern = "\r") %>%
# Remove códigos ASCII/caracteres indesejados
stringr::str_replace_all(
pattern = "\n|\003|\017|\023|\024|\025|\026|\027|\028|\029|\030|\031|\032|\033|\034|\035",
replacement = ""
) %>%
# Remove pontuações e números
tm::removePunctuation() %>%
tm::removeNumbers() %>%
stringr::str_to_lower() %>%
# Remove "stop words"
tm::removeWords(words = tm::stopwords(kind = "english")) %>%
# Normalização de palavras: stemming
tm::stemDocument(),
# Transforma informação do nº XX da ata para padrão "Ata XX"
meeting = stringr::str_sub(string = meeting, start = 1, end = 3) %>%
stringr::str_remove(pattern = "[:alpha:]") %>%
stringr::str_c("Ata ", .),
# Transforma data para YYYY-MM-DD
date = lubridate::as_date(.data$date)
) %>%
dplyr::ungroup() %>%
dplyr::arrange(date)
Tokenização
Em seguida, precisamos obter a frequência de cada palavra em cada documento/ata, de modo a obter um objeto tabular onde cada linha contém um palavra por documento, conforme abaixo:
# Tokenização copom_token <- copom_clean %>% # Contabiliza frequência das palavras tidytext::unnest_tokens(output = term, input = text, token = "words") %>% dplyr::count(meeting, term, sort = TRUE, name = "count") %>% dplyr::ungroup()
Representação matricial
Agora transformamos o objeto anterior para a representação matricial M por N que representará a frequência das palavras nas atas, onde as linhas M representam as atas e as colunas N são as palavras, e os valores são as frequências das palavras. Além disso, aplicamos outro tratamento para remover palavras que aparecem com pouca frequência nas atas, processo similar a uma remoção de "outliers":
# Transformar em objeto DocumentTermMatrix copom_dtm <- copom_token %>% tidytext::cast_dtm( document = meeting, term = term, value = count, weighting = tm::weightTf ) %>% # Remoção de "outliers": manter apenas termos que aparecem # em 80% dos documentos (atas) tm::removeSparseTerms(sparse = 0.2)
Estimar modelo LDA
Para estimar o modelo LDA usamos o pacote topicmodels, com os valores padrão dos argumentos fornecidos pela função LDA(), exceto para alguns controles do amostrador de Gibbs e para o argumento k, que indica o número de tópicos a serem usados para classificar as atas do COPOM.
A especificação do parâmetro k é relativamente arbitrária, e apesar de existirem abordagens analíticas para decidir o valor de k, a maior parte da literatura o define de forma ad hoc. Ao escolher k temos dois objetivos que estão em conflito direto entre si. Queremos "prever" corretamente o texto e ser o mais específico possível para determinar o número de tópicos. No entanto, ao mesmo tempo, queremos ser capazes de interpretar nossos resultados e, quando nos tornamos muito específicos, o significado geral de cada tópico se perde.
A seguir definimos k = 5, assumindo que os diretores do BCB discutem apenas 5 tópicos que culminam nas atas do COPOM (você pode testar outros valores de k e ajustar o valor conforme necessidade).
# Estimar modelo Latent Dirichlet Allocation (LDA) usando Gibbs Sampling copom_lda <- topicmodels::LDA( x = copom_dtm, k = 5, method = "Gibbs", control = list( # nº de simulações repetidas com inicialização aleatória nstart = 5, # semente para reprodução (tamanho tem que ser igual a nstart) seed = as.list(1984:1988), # nº iterações descartadas burnin = 3000, # nº de iterações iter = 2000, # nº de iterações retornadas thin = 500 ) )
Resultados do modelo
Agora focamos na interpretação dos resultados do modelo estimado. Primeiro, podemos averiguar quais palavras foram associadas a cada tópico:
# Obter palavras associadas a cada tópico latente topicmodels::terms(copom_lda, k = 10) # Topic 1 Topic 2 Topic 3 Topic 4 Topic 5 # [1,] "price" "inflat" "increas" "price" "inflat" # [2,] "rate" "increas" "month" "inflat" "copom" # [3,] "increas" "price" "reach" "chang" "monetari" # [4,] "exchang" "month" "accord" "consid" "polici" # [5,] "result" "may" "data" "copom" "econom" # [6,] "indic" "year" "product" "regard" "risk" # [7,] "due" "rate" "respect" "economi" "scenario" # [8,] "declin" "period" "good" "monetari" "economi" # [9,] "month" "industri" "quarter" "growth" "committe" # [10,] "polici" "market" "last" "project" "rate"
Além dos palavras, também podemos obter suas probabilidades - chamada de ("beta") - associadas a cada tópico estimadas pelo modelo:
tidytext::tidy(copom_lda, matrix = "beta") # # A tibble: 985 x 3 # topic term beta # <int> <chr> <dbl> # 1 1 increas 0.0368 # 2 2 increas 0.0485 # 3 3 increas 0.0818 # 4 4 increas 0.00000203 # 5 5 increas 0.0000876 # 6 1 month 0.0195 # 7 2 month 0.0387 # 8 3 month 0.0581 # 9 4 month 0.00000203 # 10 5 month 0.0000235 # # ... with 975 more rows
Note que, por exemplo, o termo "increas" tem probabilidade de 0,0368 de ter sido gerado do tópico 1, mas 0.0818 de probabilidade de ter sido gerado do tópico 3.
Podemos gerar uma visualização para verificar quais são os 10 termos mais "comuns" de cada tópico, conforme abaixo:
tidytext::tidy(copom_lda, matrix = "beta") %>% dplyr::group_by(topic) %>% dplyr::slice_max(beta, n = 10) %>% dplyr::ungroup() %>% dplyr::arrange(topic, -beta) %>% dplyr::mutate(term = tidytext::reorder_within(term, beta, topic)) %>% ggplot2::ggplot() + ggplot2::aes(x = beta, y = term, fill = factor(topic)) + ggplot2::geom_col(show.legend = FALSE) + ggplot2::facet_wrap(~topic, scales = "free") + tidytext::scale_y_reordered() + ggplot2::labs(title = "Probabilidades por tópico por palavras")
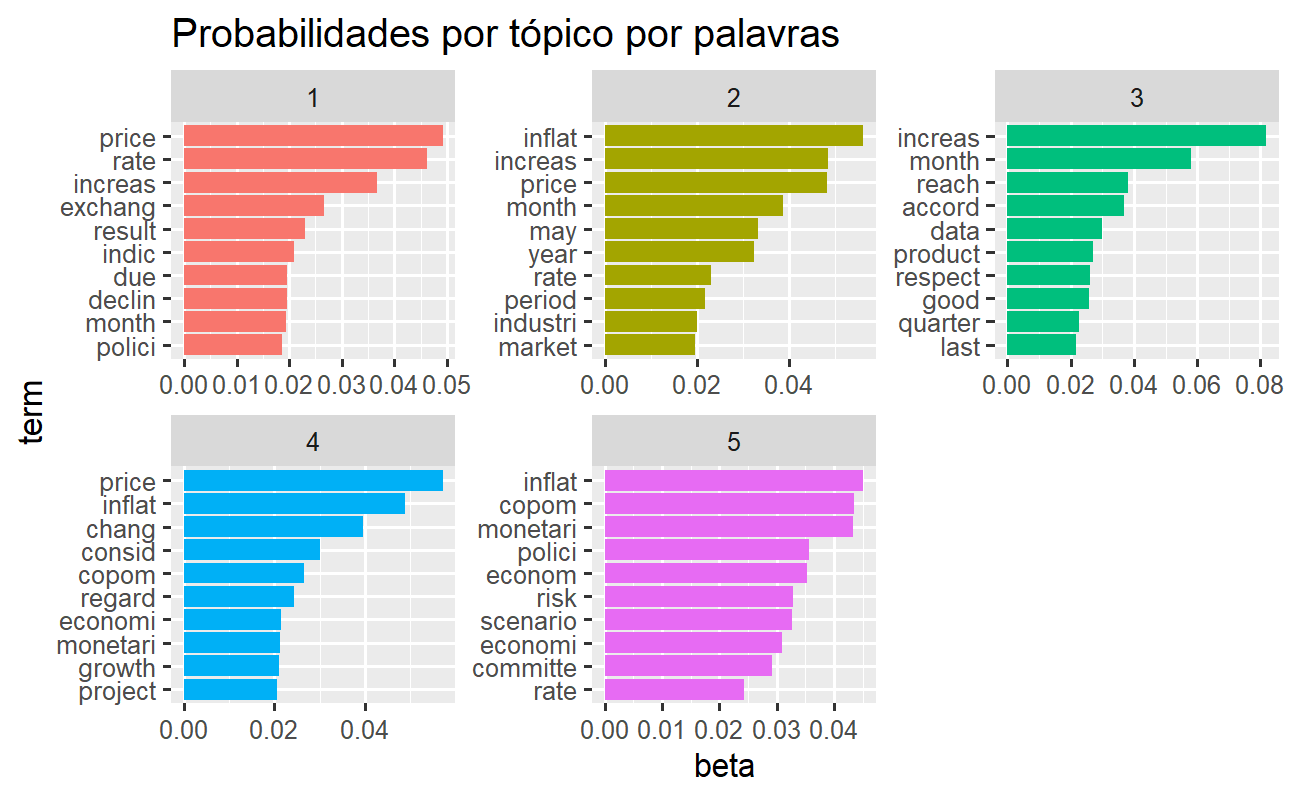
A visualização nos permite entender mais facilmente sobre os 5 tópicos que foram classificados através das atas do COPOM. As palavras mais comuns no tópico 1 incluem "rate", "price" e "increas", o que sugere que podem representar a discussão da decisão da política monetária quanto a taxa de juros. No tópico 2 são associados termos referentes a dinâmica corrente da inflação, como "inflat", "price" e "increas". Já o tópico 3 cobre discussões sobre os dados quanto ao atual nível da atividade econômica do país, incluindo termos como "data", "product" e "reach". Por sua vez, no tópico 4 aparecem termos relacionados às expectativas de inflação com os termos "project", "inflat" e "price". Por fim, no tópico 5 predominam termos associados a própria ação da autoridade monetária, incluindo termos como "copom", "monetari", "polici" e "committe".
Uma observação importante sobre as palavras em cada tópico é que algumas palavras, como “price” e “inflat”, aparecem em mais de um tópico. Esta é uma vantagem da modelagem de tópicos em oposição aos métodos de “agrupamento rígido”: tópicos usados em linguagem natural podem ter alguma sobreposição em termos de palavras. Em contrapartida, como desvantagem, podem haver tópicos demasiadamente redundantes.
Por fim, vamos analisar as probabilidades por documento (ata) por tópico, de modo a verificar os tópicos "mais discutidos" em cada reunião do COPOM. Essas probabilidades são chamadas de ("gamma") e podem ser obtidas conforme abaixo:
# Probabilidades de cada tópico por documento
copom_topics <- tidytext::tidy(copom_lda, matrix = "gamma") %>%
dplyr::left_join(
dplyr::distinct(copom_clean, meeting, date),
by = c("document" = "meeting")
) %>%
dplyr::arrange(date) %>%
dplyr::mutate(
date = as.character(date),
topic = dplyr::recode(
topic,
"1" = "Taxa de Juros",
"2" = "Inflação",
"3" = "Atividade Econômica",
"4" = "Expectativas de Inflação",
"5" = "Intervenção Monetária"
) %>%
forcats::as_factor()
)
copom_topics
# # A tibble: 975 x 4
# document topic gamma date
# <chr> <fct> <dbl> <chr>
# 1 Ata 50 Taxa de Juros 0.311 2000-09-12
# 2 Ata 50 Inflação 0.324 2000-09-12
# 3 Ata 50 Atividade Econômica 0.135 2000-09-12
# 4 Ata 50 Expectativas de Inflação 0.174 2000-09-12
# 5 Ata 50 Intervenção Monetária 0.0554 2000-09-12
# 6 Ata 51 Taxa de Juros 0.342 2000-10-04
# 7 Ata 51 Inflação 0.261 2000-10-04
# 8 Ata 51 Atividade Econômica 0.115 2000-10-04
# 9 Ata 51 Expectativas de Inflação 0.221 2000-10-04
# 10 Ata 51 Intervenção Monetária 0.0604 2000-10-04
# # ... with 965 more rows
Cada um desses valores é uma proporção estimada de palavras do documento que são geradas a partir do tópico. Por exemplo, o modelo estima que apenas cerca de 31% das palavras Ata nº 50 foram geradas a partir do tópico 1 (Taxa de Juros).
Com estes valores podem facilmente construir uma visualização para perceber a distribuição ao longo do tempo, conforme abaixo:
# Cores para gráfico
colors <- c(
blue = "#282f6b",
red = "#b22200",
yellow = "#eace3f",
green = "#224f20",
purple = "#5f487c",
black = "black"
)
# Função para formatar textos do eixo x (datas)
ym_label <- function(x) {
x <- lubridate::as_date(x)
dplyr::if_else(
is.na(dplyr::lag(x)) | tsibble::yearmonth(dplyr::lag(x)) != tsibble::yearmonth(x),
paste(lubridate::month(x, label = TRUE), "\n", lubridate::year(x)),
paste(lubridate::month(x, label = TRUE))
)
}
# Gráfico de colunas das probabilidades de cada tópico por documento
copom_topics %>%
ggplot2::ggplot() +
ggplot2::aes(x = date, y = gamma, fill = topic) +
ggplot2::geom_col() +
ggplot2::scale_x_discrete(
breaks = copom_topics %>%
dplyr::distinct(date) %>%
dplyr::filter(dplyr::row_number() %% 9 == 1) %>%
dplyr::pull(date),
labels = ym_label
) +
ggplot2::scale_y_continuous(
breaks = scales::extended_breaks(n = 6),
labels = scales::label_number(big.mark = ".", decimal.mark = ","),
expand = c(0, 0)
) +
ggplot2::scale_fill_manual(values = unname(colors)) +
ggplot2::labs(
title = "**Um conto de 4 crises**: o debate interno no COPOM",
subtitle = "Tópicos extraídos via modelo LDA usando textos das atas das reuniões",
y = "Probabilidade do Tópico",
x = "Data da Reunião",
fill = NULL,
caption = "**Dados**: BCB | **Elaboração**: analisemacro.com.br"
) +
ggplot2::theme_light() +
ggplot2::theme(
plot.title = ggtext::element_markdown(size = 28, colour = colors["blue"]),
plot.subtitle = ggtext::element_markdown(size = 14, face = "bold"),
plot.caption = ggtext::element_textbox_simple(size = 11),
legend.position = "top",
legend.text = ggplot2::element_text(size = 12, face = "bold"),
axis.text = ggplot2::element_text(size = 11, face = "bold"),
axis.title = ggtext::element_markdown(size = 12, face = "bold"),
axis.ticks = ggplot2::element_line(size = 0.7, color = "grey30"),
axis.ticks.length = ggplot2::unit(x = 1, units = "mm")
)

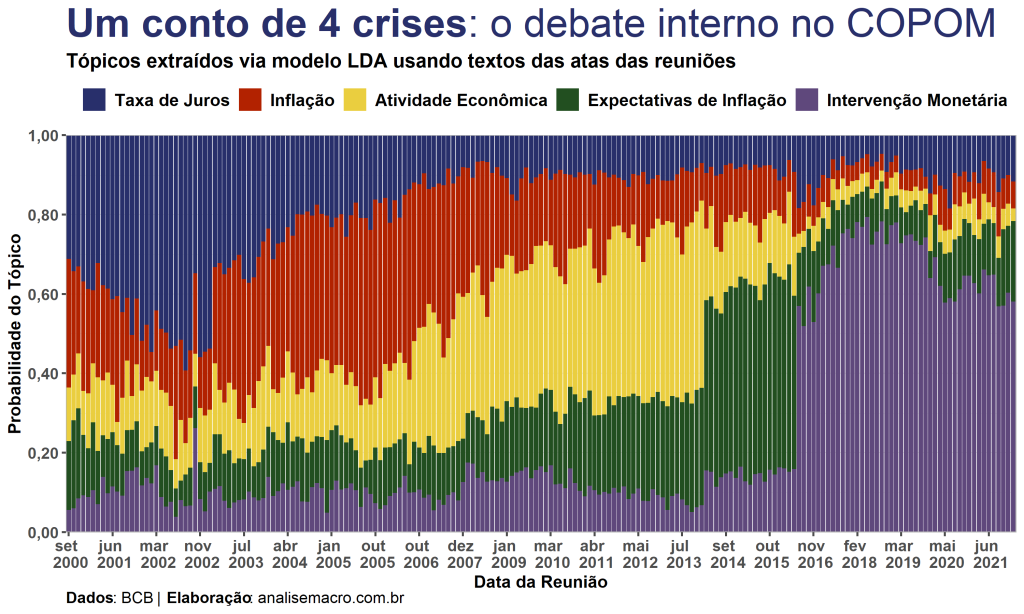
Podemos perceber que o modelo capta corretamente a "história" da política monetária brasileira ao longo destas duas últimas decadas. Em resumo, o choque de expectativas da eleição de 2002 (Lula) fez com que o BCB intervisse com juros, movimento visível no gráfico. Durante a crise financeira global de 2008, as discussões sobre o crescimento econômico cresceram significativamente. Já na crise da nova matriz econômica, durante os governos de Dilma Russef, as expectativas de inflação foram abruptamente se deteriorando e, com a mudança da diretoria do BCB em 2016, o aperto monetário tomou a cena. Por fim, e mais recentemente, preocupações com a escalada inflacionária e com as expectativas de inflação tiveram um aumento significativo da probabilidade de terem sido mais discutidas durante a pandemia da Covid-19.
Pessoalmente, estou satisfeito com os resultados encontrados. O modelo LDA parece ter se ajustado conforme o verdadeiro "tom" da política monetária no período. Porém, obviamente, como todo modelo há sempre espaços para aperfeiçoamentos e revisões, fique a vontade para usar o código disponível para tal.
Espero que o exercício tenha sido útil para você. Em última instância, a técnica aqui apresentada ao menos nos economiza o considerável tempo que seria necessário lendo todas as atas do COPOM para, só então, identificar tópicos discutidos.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.
Posts sobre o assunto:
- Análise das Atas do COPOM com text mining (análise de sentimentos)
- Detecção de plágio com NLP no R: o caso Decotelli
- Teto de Gastos: análise de sentimentos com dados do Twitter
Referências:
- Silge, J., & Robinson, D. (2017). Text Mining with R: A Tidy Approach (1st ed.). O’Reilly Media.
- Benchimol, J., Kazinnik, S., & Saadon, Y. (2021). Federal Reserve communication and the COVID-19 pandemic. Covid Economics, 218.
- Benchimol, J., Kazinnik, S., & Saadon, Y. (2020). Text mining methodologies with R: An application to central bank texts. Bank of Israel, Research Department.
- Blei D. M., Ng A. Y., Jordan M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 3, 993–1022.

