Não é qualquer dia, apesar da alta frequência do caso brasileiro, que vivenciamos uma mudança de regime fiscal da economia. A falta de novos erros e essa insistência nos velhos já traz consequências que começam a ser absorvidas pelos agentes. A repercussão do furo do teto de gastos se traduz em um claro e notório sentimento de desaprovação. Rodadas de revisão de projeções naturalmente já tomam corpo no mercado. Dessa forma, neste texto exercitamos uma forma de quantificar a repercussão do evento através de uma simples análise de sentimentos, usando dados do Twitter.
Sobre a técnica de análise de sentimentos e text mining, aqui no blog já exploramos, por exemplo, uma aplicação com as atas do COPOM e outra com detecção de plágio (códigos disponíveis em R). Para o exercício de hoje utilizaremos um framework semelhante, mas com dados diferentes.
Vamos ao código!
Pacotes
Para reproduzir os códigos de R deste exercício, certifique-se de que tenha os seguintes pacotes instalados/carregados:
library(magrittr) # CRAN v2.0.1 library(rtweet) # CRAN v0.7.0 library(lexiconPT) # CRAN v0.1.0 library(dplyr) # CRAN v1.0.7 library(tidytext) # CRAN v0.2.6 library(purrr) # CRAN v0.3.4 library(tidyr) # CRAN v1.1.3 library(ggplot2) # CRAN v3.3.5 library(ggtext) # CRAN v0.1.1 library(scales) # CRAN v1.1.1
Dados
Conforme mencionado, os dados utilizados são provenientes do Twitter, através de sua API. O objetivo é extrair tweets da rede social associados ao termo "teto de gastos", e então usar essas informações textuais no escopo da análise de sentimentos através de um léxico da língua portuguesa.
O acesso aos dados do Twitter exige que o usuário seja cadastrado e autenticado para interagir com a API. A interface em R para obter os dados é feita através do pacote rtweet, que descreve em sua documentação as opções e formas de realizar essa autenticação.
Já o léxico da língua portuguesa são provenientes de datasets do pacote {lexiconPT}.
Com essas informações em mãos, você estará apto a reproduzir os códigos do exercício. Caso tenha dificuldades, disponibilizamos neste link em formato RDS o dataset de tweets utilizado abaixo.
O código abaixo realiza a coleta dos dados, observando o que foi mencionado acima:
# Importante: coleta de dados do Twitter exige autenticação de uso da API # Veja como em: https://docs.ropensci.org/rtweet/#usage # Coleta dados de tweets dos últimos 6-9 dias df_tweets <- rtweet::search_tweets( q = '"teto de gastos"', # pesquisar termo exato n = 20000, # número de tweets desejados include_rts = FALSE, # não incluir retweets retryonratelimit = TRUE # para retornar o nº desejado de tweets ) dplyr::glimpse(df_tweets)
# Léxicos da língua portuguesa para análise de sentimentos oplex <- lexiconPT::oplexicon_v3.0 sentilex <- lexiconPT::sentiLex_lem_PT02 dplyr::glimpse(oplex) dplyr::glimpse(sentilex)
Observe que o dataset dos tweets traz diversas informações, contendo um identificador único de cada tweet (status_id), data e horário (created_at), mensagem de texto (text), dentre outras. E as opções de léxicos do pacote trazem uma coluna com o termo/palavra e outras informações, sendo a polaridade a principal delas pois indica se o termo está associado a um sentimento "negativo" ou "positivo", e é o que utilizaremos para fazer a análise de sentimentos.
Com esses conjuntos de informação já temos tudo que precisamos para iniciar uma simples análise de sentimentos.
Tokenização
O primeiro passo a ser feito é desagregar a informação das mensagens de texto de cada tweet de modo a separar essas mensagens em várias palavras/tokens. Esse processo é conhecido como "tokenização" e sua implementação é bastante simples, conforme abaixo:
# Separa coluna "text", que são os tweets, em n tokens/palavras df_token <- df_tweets %>% tidytext::unnest_tokens(output = "term", input = "text") # Resultado é a coluna "term" com um token/palavra por linha do data frame dplyr::glimpse(df_token)
Observe que o número de linhas aumentou consideravelmente, dada a separação dos tweets em n tokens.
Análise de sentimentos
Com esse volume de informações sobre a amostra de tweets coletada, podemos usar a classificação da polaridade (sentimento) de um dos léxicos acima para verificar por tweet quais palavras expressam sentimos mais positivos ou mais negativos:
# 1) Juntar tokens com léxicos e obter polaridade por tweet # Juntar dados df_sent <- purrr::reduce( .x = list( df_token, oplex, dplyr::select(sentilex, term, lex_polarity = polarity) ), .f = dplyr::inner_join, by = "term" ) %>% # Agrupar por identificador único de cada tweet dplyr::group_by(status_id) %>% # Obter sentimento total de cada tweet de acordo com polaridade # para saber quão negativo/positivo é um tweet dplyr::summarise( tweet_oplex = sum(polarity), tweet_sentilex = sum(lex_polarity) ) %>% dplyr::ungroup() dplyr::glimpse(df_sent)

O resultado é um novo dataset com a identificação de cada tweet e o correspondente sentimento (soma da polaridade) obtido através dos tokens extraídos acima. Perceba que perdemos observações pois algumas palavras não estão presentes nos léxicos utilizados.
O próximo passo é um tratamento adicional dos dados de modo a obter o sentimento diário desse conjunto amostral de tweets:
# 2) Usar polaridade por tweet para obter sentimento diário # Juntar dados de tweets e polaridades df_sent_by_date <- dplyr::inner_join(df_tweets, df_sent, by = "status_id") %>% # Filtrar somente polaridades positivas/negativas dplyr::filter(tweet_oplex != 0) %>% # Obter quantidade de tweets com sentimento "negativo/positivo" por dia dplyr::count( sentiment = dplyr::if_else(tweet_oplex < 0, "negativo", "positivo"), date = as.Date(created_at) ) %>% # Converter para formato wide tidyr::pivot_wider( id_cols = `date`, names_from = `sentiment`, values_from = `n` ) %>% # Obter sentimento diário dplyr::mutate(sentimento = positivo - negativo) dplyr::glimpse(df_sent_by_date)

O resultado é um dataset que contabiliza por dia o sentimento expresso nos tweets detectado através da polaridade.
Visualização de resultados
Por fim podemos gerar um gráfico bacana para observar a evolução do sentimento ao longo do tempo. É bastante notório o sentimento negativo após as declarações do Ministro da Economia, Paulo Guedes, em 20 de outubro de 2021:
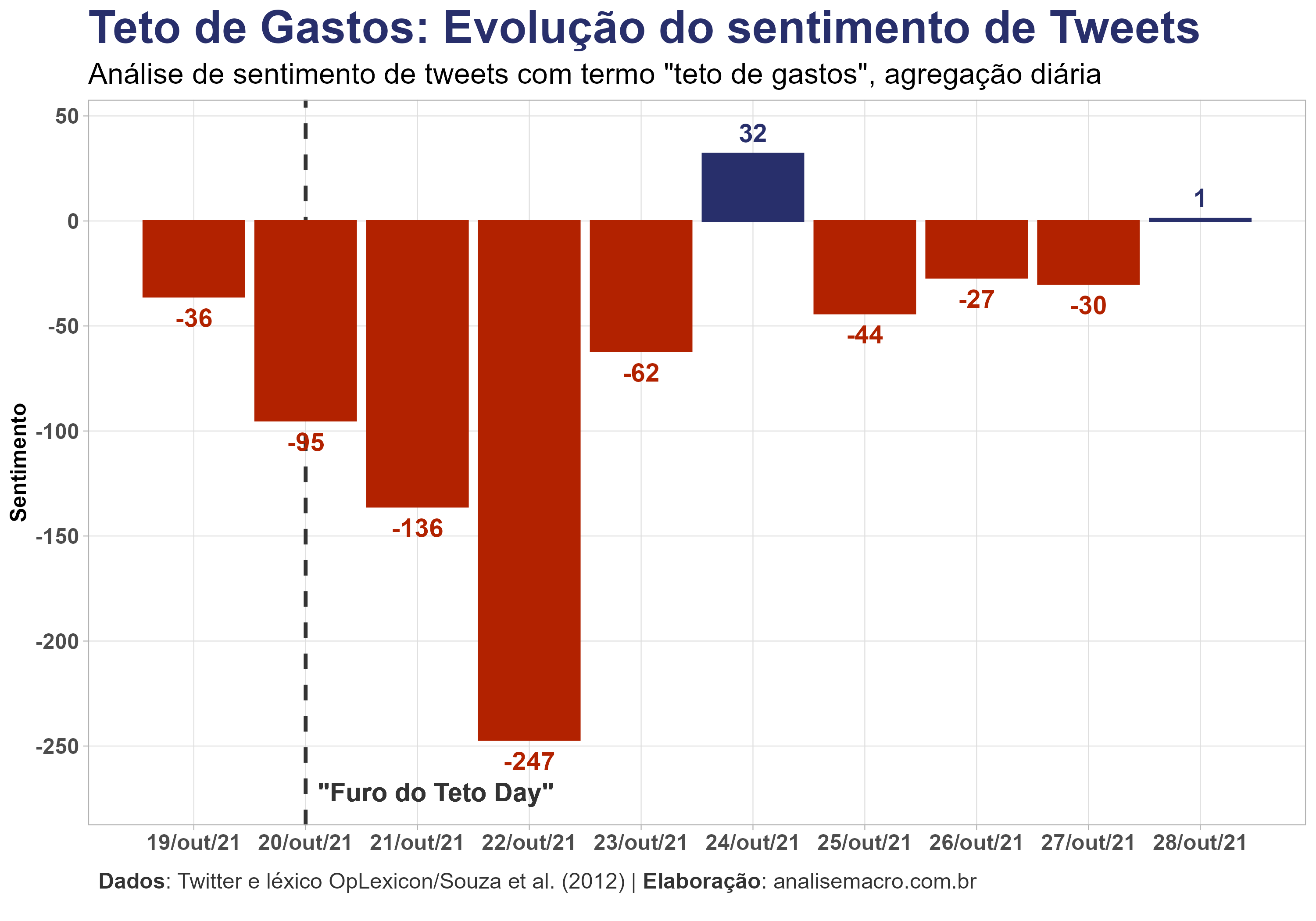
Interessante, não? A técnica de análise de sentimentos é bastante promissora, e este simples exercício já demonstra sua facilidade de aplicação.
Um ponto importante que foi ignorado é a possibilidade de haver, no conjunto amostral de tweets coletados através API, uma quantidade significativa de contas "bot" do Twitter. Quando o assunto é política, governo, etc. isso é particularmente expressivo e problemático (seja no sentido de apoio ou oposição ao governo), de modo que pode distorcer a análise acima. Pretendo abordar esse assunto em um post futuro!
Referências
Recomenda-se consultar a documentação dos pacotes utilizados para entendimento aprofundado sobre as funcionalidades.
- Exemplo de uso do lexiconPT com dados do Facebook: https://sillasgonzaga.github.io/2017-09-23-sensacionalista-pt01/


