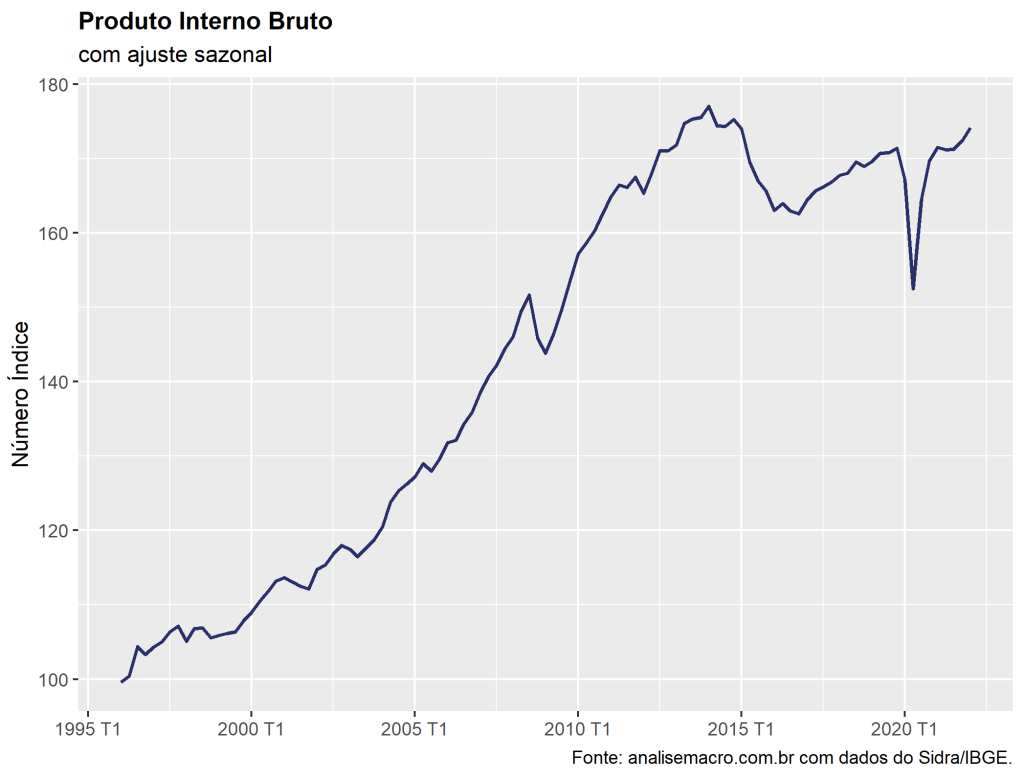
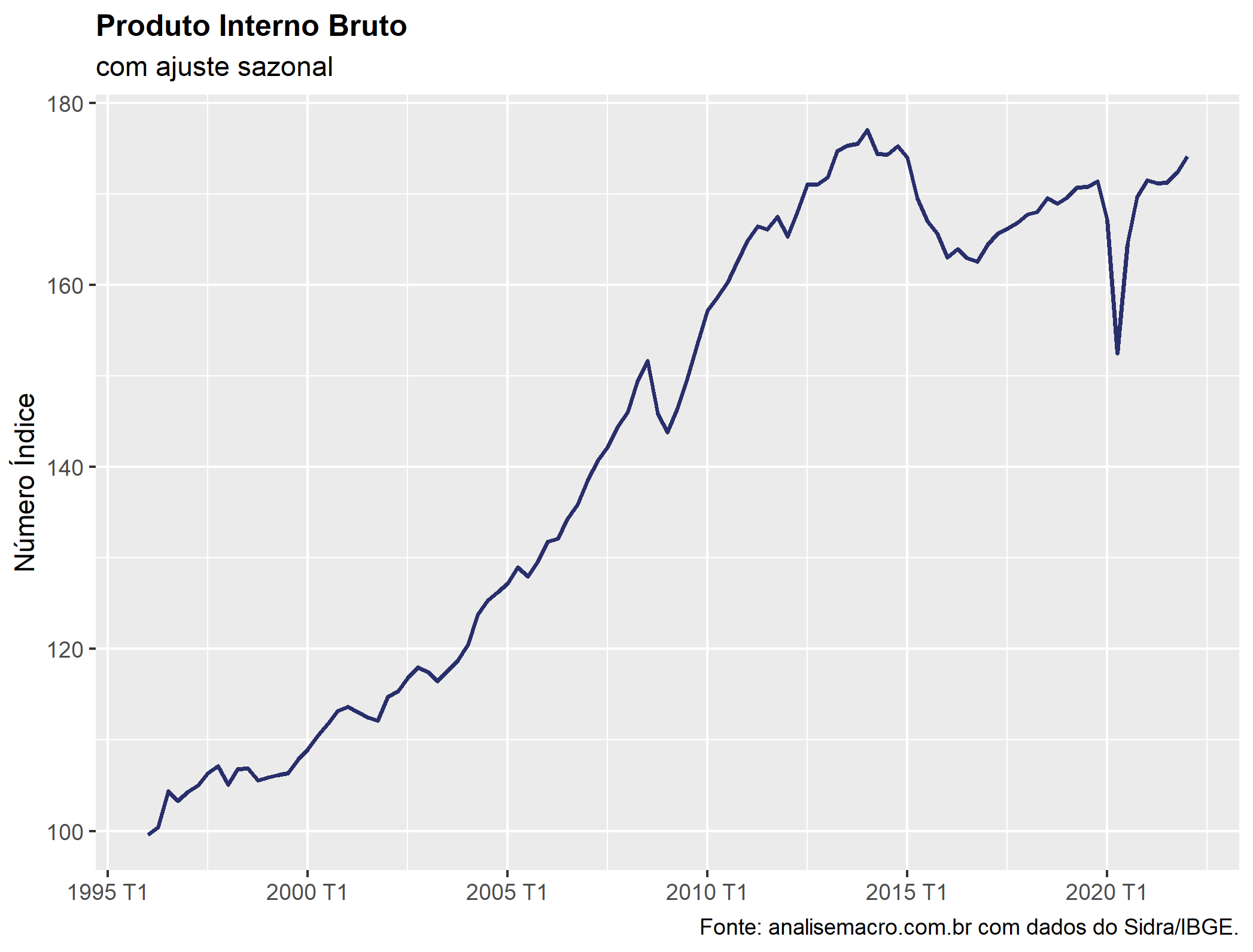
O Produto Interno Bruto é o principal indicador para acompanhamento do nível de atividade no Brasil, medindo a soma final de todos os bens e serviços produzidos no país. Os dados do PIB podem ser acessados através do Sidra, sendo importados facilmente com o R através do pacote {sidrar}. Mostramos no post de hoje como é possível extrair automaticamente e de forma totalmente reprodutível os dados do PIB da plataforma do Sidra utilizando o R.
O primeiro passo será carregar o pacote {sidrar}, que oferecerá a possibilidade de acessar a API do indicador obtido através do Sidra. Também carregamos o {tidyverse} para que possamos realizar limpezas nos dados.
Em seguida, com a API do indicador, utilizaremos a função sidrar::get_sidra() para obter os dados do indicador direto no R.
Por fim, realizamos algumas limpeza de forma que possamos trabalhar com os dados.
Agora temos em mãos a série do PIB com ajuste sazonal totalmente limpa para que possamos trabalhar!
________________________________________
Quer saber mais?
Veja nossos cursos de Macroeconomia através da nossa trilha de Macroeconomia Aplicada.

