Uma das grandes vantagens de utilizar o R é poder automatizar a coleta de dados. Para ilustrar, vamos utilizar o pacote GETTDData para coletar os dados do Tesouro Direto, bem como outros pacotes do R para tratamento e visualização dos dados.
library(tidyverse) library(tidyquant) library(timetk) library(scales) library(quantmod) library(GetTDData) library(ecoseries) library(RColorBrewer)
Com os pacotes carregados no meu arquivo .Rmd, posso começar a coletar os dados. Eu começo pelas NTN-B, agora nomeadas como Tesouro IPCA. O código abaixo faz o download e a leitura das planilhas.
download.TD.data('NTN-B')
ntnb <- read.TD.files(dl.folder = 'TD Files',
asset.codes = 'NTN-B')
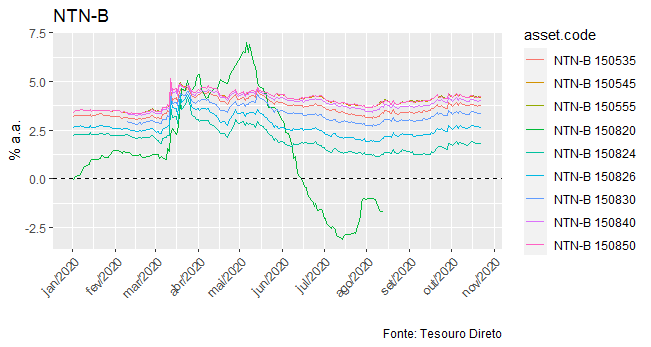
A seguir, nós podemos visualizar alguns dos títulos que acabamos de coletar tendo como referência janeiro do ano passado.
filter(ntnb, ref.date > '2020-01-01') %>%
ggplot(aes(x=ref.date, y=yield.bid*100, colour=asset.code))+
geom_line()+
geom_hline(yintercept=0, colour='black', linetype='dashed')+
scale_x_date(breaks = date_breaks("1 month"),
labels = date_format("%b/%Y"))+
theme(axis.text.x=element_text(angle=45, hjust=1))+
labs(x='', y='% a.a.',
title='NTN-B',
caption='Fonte: Tesouro Direto')
 _____________________
_____________________
(*) Isso e muito mais você irá aprender no nosso Novo Curso Mercado Financeiro e Gestão de Portfólios.

