Análise dos Maiores Salários de Contratação no CAGED 2025 com Python
Este artigo apresenta uma análise detalhada dos maiores salários de contratação no Brasil em 2025, com foco nos estados do Sudeste. Utilizando a linguagem Python e Google Colab, o estudo detalha a construção de um pipeline de engenharia de dados para processar milhões de microdados do Novo CAGED, desde a coleta via FTP até a agregação e armazenamento em formato Parquet. A metodologia inclui a aplicação de filtros estatísticos e o cálculo da mediana salarial para ranquear as 15 ocupações mais bem remuneradas.
Luiz Henrique Barbosa Filho
8 de abril de 2026
12:24
Introdução
O mercado de trabalho formal brasileiro é monitorado mensalmente pelo Novo Cadastro Geral de Empregados e Desempregados (Novo CAGED), base de registros administrativos gerida pelo Ministério do Trabalho e Emprego (MTE). Esta base captura o fluxo de todas as admissões e desligamentos sob o regime da CLT, incluindo uma variável de extrema relevância para a análise macroeconômica: o salário contratado no ato da admissão.
Analisar o salário de contratação permite observar o "preço na margem" da mão de obra. Diferente do estoque total de salários da economia — que carrega a inércia de dissídios passados e planos de carreira de funcionários antigos —, o salário de admissão reflete a disposição atual das empresas em remunerar novos talentos, evidenciando as pressões de oferta e demanda por qualificações específicas no tempo presente.
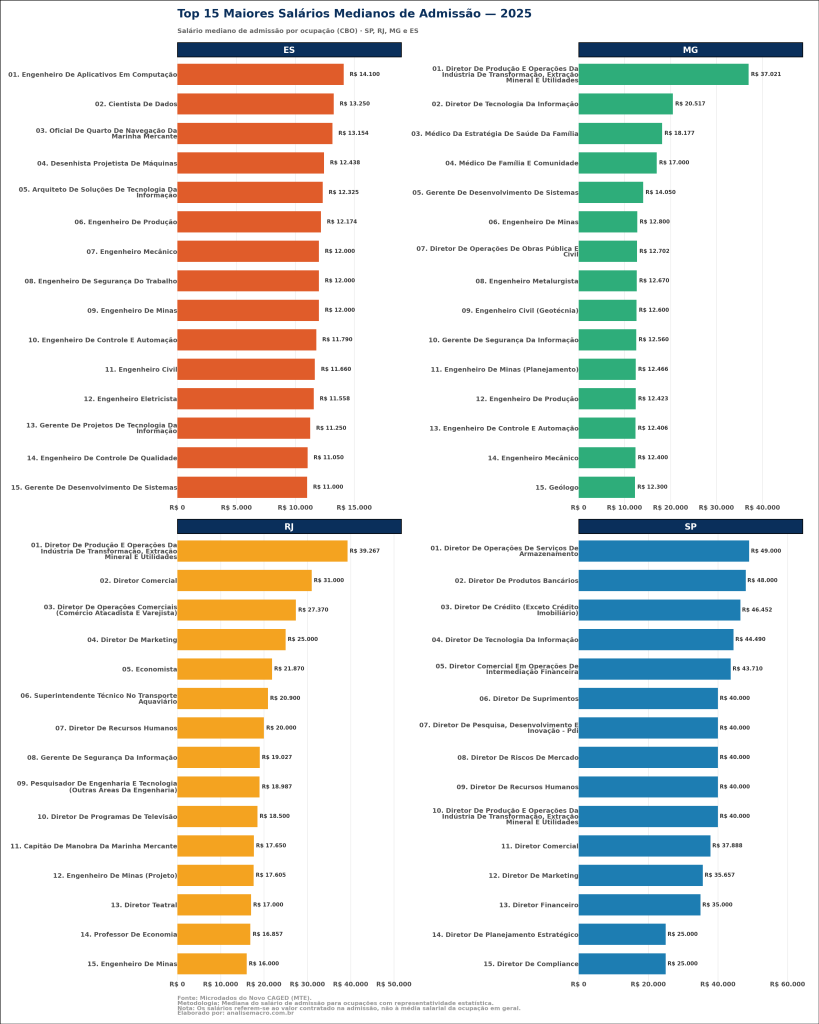
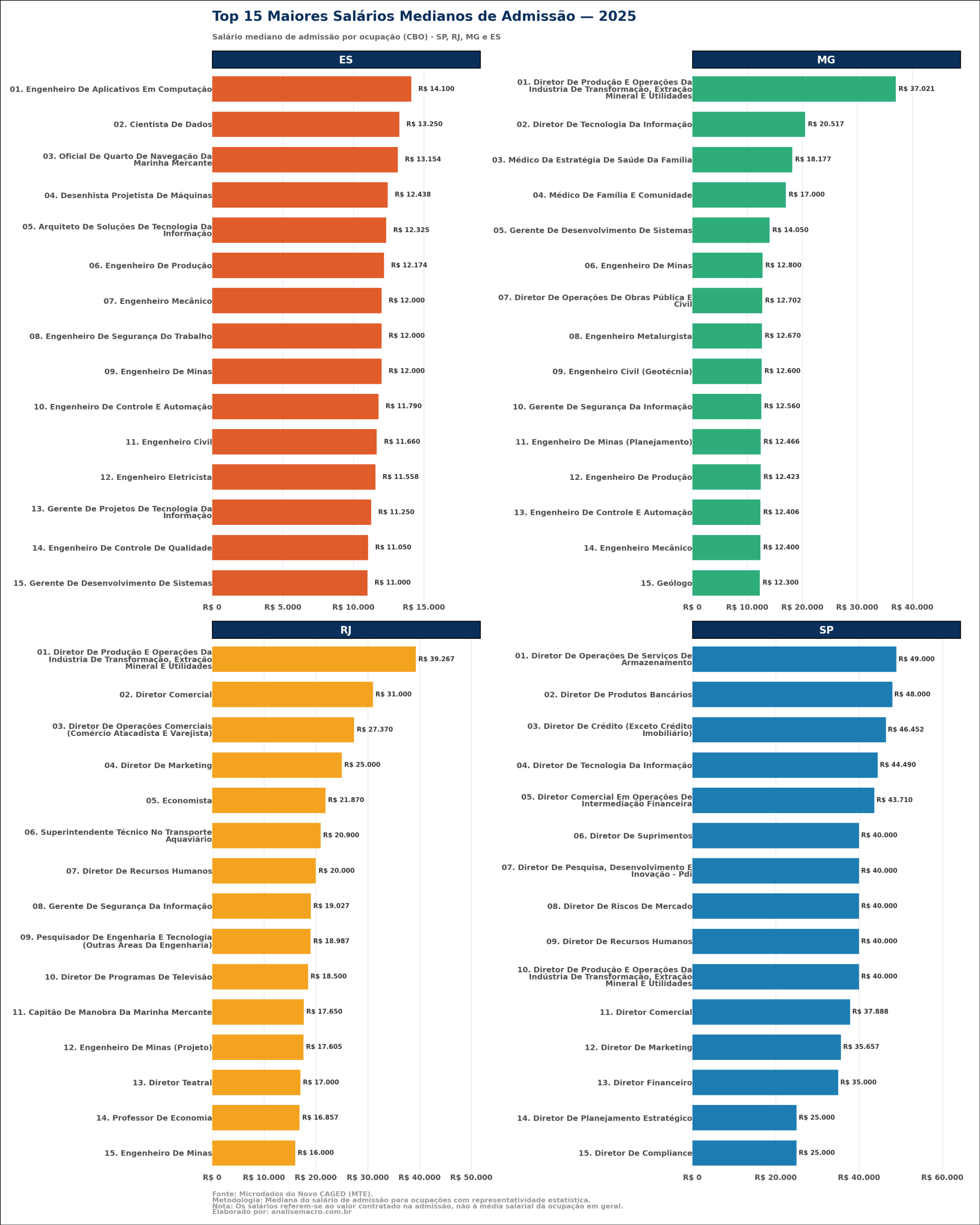
Este estudo responde a uma pergunta direta: quais ocupações pagaram os maiores salários de contratação em 2025? O escopo analítico foi delimitado aos quatro estados da região Sudeste (São Paulo, Rio de Janeiro, Minas Gerais e Espírito Santo), apresentando as 15 ocupações mais bem remuneradas em cada unidade federativa.
Para obter o código e o tutorial deste exercício faça parte doClube AMe receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Objetivo
O objetivo central deste exercício é mapear e ranquear as remunerações de entrada no mercado de trabalho formal do Sudeste em 2025.
É fundamental estabelecer uma premissa metodológica: os salários calculados dizem respeito exclusivamente ao valor pago para profissionais recém-contratados no ano de 2025. Portanto, não podem ser utilizados como proxy para a média salarial da ocupação na sua totalidade.
O indicador final a ser extraído é a mediana do salário de admissão registrado no Novo CAGED, agrupado por ocupação (utilizando o código CBO de 6 dígitos) e por Unidade da Federação (UF), consolidando todos os meses do ano de 2025.
Arquitetura de Dados e Processamento
Trabalhar com os microdados do Novo CAGED exige uma infraestrutura de dados robusta, visto que os arquivos mensais disponibilizados via FTP são massivos (arquivos de texto que ultrapassam facilmente os 400 MB descompactados por mês). Para viabilizar a extração e a análise sem esgotar a memória RAM, o projeto foi estruturado em Python utilizando o ambiente do Google Colab integrado ao Google Drive.
A engenharia de dados foi desenhada com um pipeline incremental e paralelizado:
Conexões Paralelas: Utilizou-se a biblioteca concurrent.futures (ThreadPoolExecutor) para abrir 4 conexões simultâneas (workers) ao servidor FTP do MTE via comando curl, acelerando o gargalo de I/O (entrada e saída) da rede.
Extração e Leitura em Lotes (Chunks): Os arquivos .7z baixados são extraídos localmente. Para evitar o colapso da memória, a biblioteca pandas lê os arquivos .txt em blocos de 150.000 linhas (chunksize). Além disso, apenas 4 colunas estritamente necessárias são carregadas na memória.
Agregação em Memória e Armazenamento Eficiente: Dentro de cada lote, os dados são filtrados e agregados. O resultado mensal é salvo diretamente no Google Drive no formato Parquet (via pyarrow). O formato colunar Parquet aplica uma compressão severa: o arquivo que originalmente possuía centenas de megabytes é reduzido para cerca de 200 KB por mês. Um ano inteiro de dados processados ocupa aproximadamente 2,4 MB no Drive.
Coleta Incremental (Cache): O script verifica o diretório do Google Drive antes de iniciar o download. Se o arquivo Parquet de um determinado mês já existir, o código pula essa etapa. Isso torna o pipeline eficiente para atualizações mensais.
Tratamento do Dicionário CBO
Para que os códigos numéricos das profissões presentes nos microdados façam sentido, é necessário cruzá-los com a Classificação Brasileira de Ocupações (CBO). Contudo, o portal do MTE possui bloqueios contra raspagem de dados (web scraping) automatizada para este arquivo específico.
Dessa forma, a arquitetura do projeto exige uma intervenção manual que deve ser feita uma única vez:
O arquivo deve ser salvo no Google Drive no caminho especificado pelo código: Meu Drive > caged_cache > CBO2002_Ocupacao.csv.
Filtros Aplicados aos Microdados
A qualidade da análise econômica depende da limpeza rigorosa dos dados brutos. Durante a leitura em lotes (chunks), o código aplica uma máscara de filtros (mask) para isolar apenas os registros que representam contratações padronizadas. Os filtros aplicados foram:
Apenas Admissões:saldomovimentação == 1. Exclui todos os registros de desligamento.
Declarações no Prazo:indicadordeforadoprazo == 0. Exclui declarações feitas fora da competência original, evitando distorções temporais.
Exclusão de Trabalho Intermitente:indtrabintermitente == 0. Contratos intermitentes possuem remuneração variável e não comparável ao salário mensal padrão.
Padronização da Unidade Salarial:unidadesaláriocódigo == 5. Este é um dos filtros mais importantes. Ele garante que apenas salários com periodicidade mensal sejam incluídos, descartando remunerações cadastradas por hora, dia, semana ou quinzena, que distorceriam a base de cálculo.
Filtro Geográfico:uf.isin(UFS). Restringe a base aos estados de SP, RJ, MG e ES.
Salários Válidos:salário > 0. Remove erros de preenchimento com salários zerados ou negativos.
Após a consolidação de todos os meses, um último filtro de representatividade estatística é aplicado: Mínimo de Admissões (MIN_N = 10). Ocupações que tiveram menos de 10 contratações no estado durante todo o ano de 2025 são excluídas do ranking. Isso evita que uma única contratação com salário atipicamente alto (um outlier, como a transferência de um CEO global) coloque uma ocupação no topo da lista de forma artificial.
Cálculo do Indicador e Visualização
Com os dados limpos e consolidados, o código calcula a mediana do salário de admissão para cada ocupação. A escolha da mediana, em detrimento da média aritmética, é a abordagem econométrica correta para distribuições de renda, pois a mediana não é influenciada por valores extremos (erros de digitação no eSocial com salários na casa dos milhões, por exemplo).
A etapa final utiliza a biblioteca plotnine (baseada na gramática dos gráficos) para gerar a visualização. O resultado é um painel de gráficos de barras horizontais, facetado por estado (facet_wrap). O gráfico exibe o Top 15 das ocupações, ordenadas do maior para o menor salário mediano, com os valores nominais formatados em reais (R$) plotados diretamente nas barras para facilitar a leitura direta.
Conclusão
A identificação das ocupações com os maiores salários de contratação fornece um mapa claro de onde está alocado o prêmio salarial na economia do Sudeste brasileiro.
Mais do que o resultado econômico, este exercício comprova a necessidade de ferramentas avançadas de programação para a análise de políticas públicas e mercado de trabalho. O uso do Python permitiu contornar as limitações de hardware através do processamento em lotes, otimizar o armazenamento com a tecnologia Parquet e aplicar filtros estatísticos rigorosos sobre milhões de linhas de dados brutos. O resultado é um pipeline de dados analítico, reprodutível e pronto para ser atualizado a cada nova divulgação do Ministério do Trabalho.