Vamos continuar a série de postagens sobre como construir um Dashboard de métricas relacionadas a avaliação de ações e construção de um Portfolio de investimentos no Python. Trazemos nessa semana um componente importante para avaliação do risco: o cálculo do Índice de Sharpe.
Definindo o Sharpe
Cálculo do Índice de Sharpe
O Índice de Sharpe pode ser desmembrado em dois tipos: ex post e ex ante, isto é, a medida que tem como base comparar investimentos no passado, e aquela que tem como objetivo comparar investimentos de forma prospectiva, respectivamente.
As implementações práticas usam resultados ex post, enquanto as discussões teóricas focam em valores ex ante. Implícita ou explicitamente, assume-se que os resultados históricos têm pelo menos alguma capacidade preditiva, apostando que o que é visto no passado, ocorrerá no futuro.
Abaixo citamos como é possível calcular ambos os tipos, entretanto, como exemplo, criaremos somente o ex post no Python.
Ex ante
Para o cálculo ex ante, temos que  seja o retorno projetado do investimento i e
seja o retorno projetado do investimento i e  seja o retorno projetado do benchmark ou taxa de juros livre de risco. Os tildes na equação abaixo significam que não é conhecido com certeza os valores, portanto, chamados de retornos esperados. Definimos
seja o retorno projetado do benchmark ou taxa de juros livre de risco. Os tildes na equação abaixo significam que não é conhecido com certeza os valores, portanto, chamados de retornos esperados. Definimos  como o retorno diferencial.
como o retorno diferencial.

 será o valor esperado de d e
será o valor esperado de d e  será o valor previsto do desvio padrão, portanto, o índice de Sharpe será
será o valor previsto do desvio padrão, portanto, o índice de Sharpe será

Nessa versão, o Sharpe indica o diferencial do retorno esperado por unidades de risco associado ao retorno diferencial.
Ex post
Para o ex post, considere  o retorno do investimento i no tempo t, e
o retorno do investimento i no tempo t, e  o retorno do benchmark ou taxa de juros livre de risco no período t e
o retorno do benchmark ou taxa de juros livre de risco no período t e  o diferencial de retorno no período t.
o diferencial de retorno no período t.

Calculamos a média de obtendo  , que será o valor médio de D no período t=1 até T, e também o desvio padrão de .
, que será o valor médio de D no período t=1 até T, e também o desvio padrão de .
Com isso, o índice de Sharpe ex post será

Para tornar fácil a comparação de diferentes investimentos em diferentes janelas de tempo, é aconselhável utilizar o índice de Sharpe anualizado, obtido por meio do seguinte cálculo:

Em que T é o período para anualizar, e que pode tomar o valor de 252 dias para dados diários e 12 meses para dados mensais.
Para obter o código do Dashboard abaixo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais de R e Python.
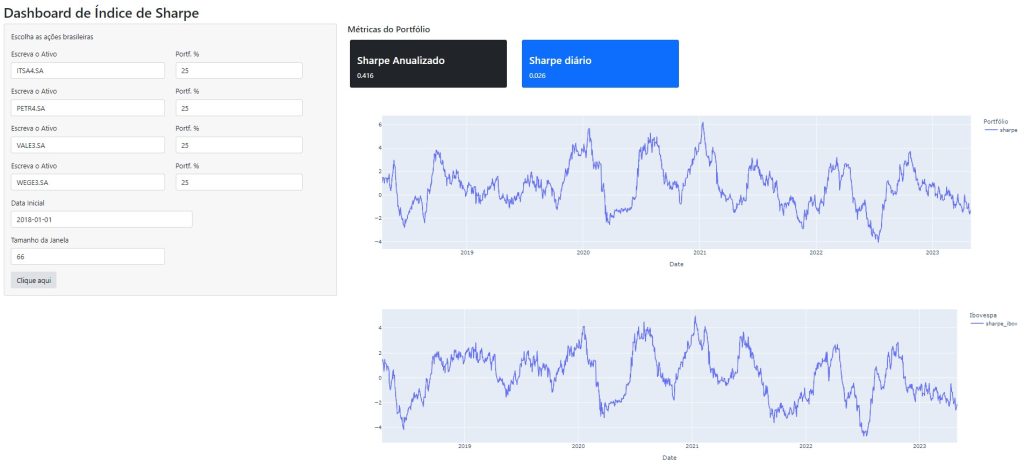
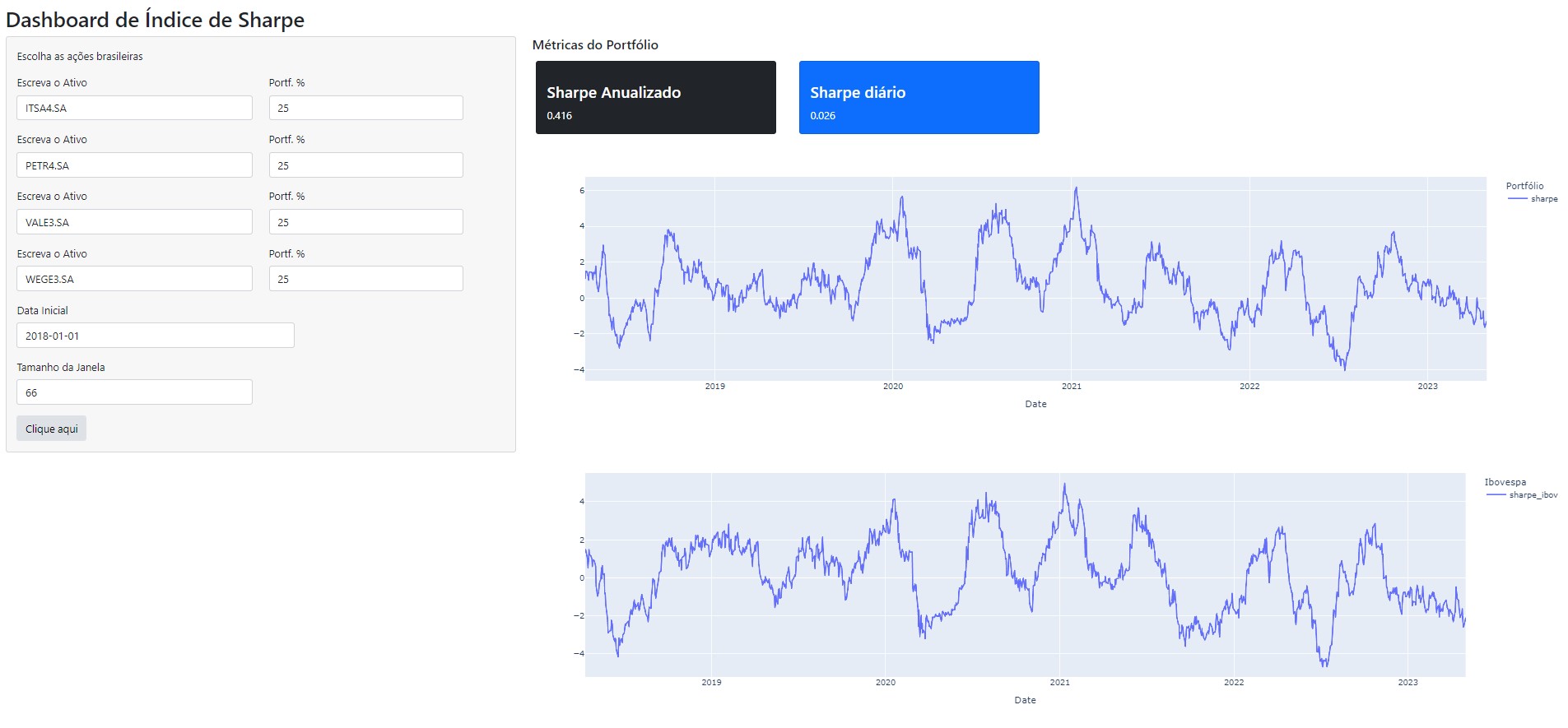
Dashboard de Índice de Sharpe
Para facilitar todo o trabalho de verificar essas métricas, é possível criar um Dashboard, que automatiza todo o processo de coleta, tratamento, criação das métricas e a visualização de dado. No Dashboard abaixo, o processo de coleta de dados financeiros foi feito por meio da biblioteca yfinance. O Dashboard é construído no ambiente da biblioteca Shiny e os gráficos construídos por meio do Plotly.
_____________________
Quer saber mais?
Veja nossa trilha de cursos de Finanças Quantitativas

