Podemos dizer que um fato é certeiro na vida de todo Cientista de Dados: encontrar Missing Values. A vida de quem trabalha com finanças também não é diferente, sendo comum encontrar séries financeiras com dados faltantes. Neste post, iremos mostrar como podemos lidar com este problema.
library(quantmod) library(zoo) library(knitr) library(magrittr) library(timetk)
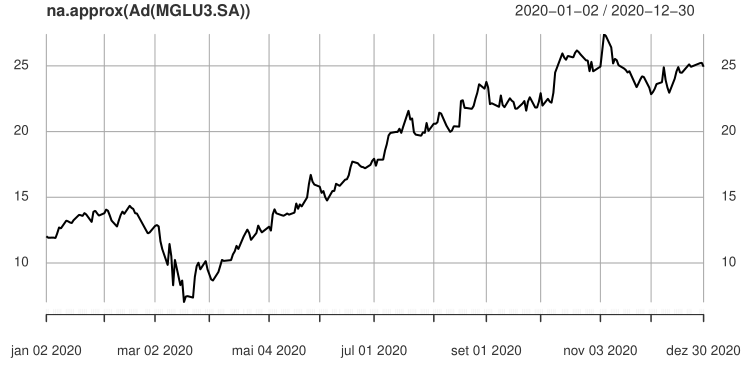
Vamos aqui trabalhar com a série de preços da MGLU3. Podemos ver através do gráfico que há um NA faltante no dia 26 de fevereiro de 2020.
getSymbols("MGLU3.SA",
auto.assign = TRUE,
from = "2020-01-01",
to = "2020-12-31")
plot(Ad(MGLU3.SA))
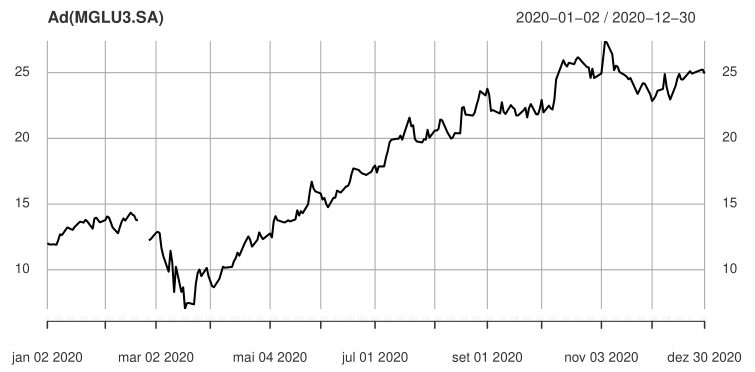
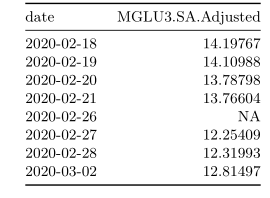
Podemos utilizar a função window() para visualizar detalhadamente a data em que nossa série de preços possui dados faltantes.
mglu_na <- window(Ad(MGLU3.SA),
start = "2020-02-18",
end = "2020-03-02")
Agora iremos trabalhar em como podemos lidar com esse NA.
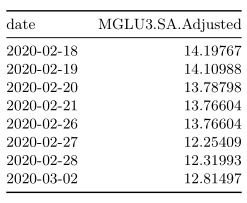
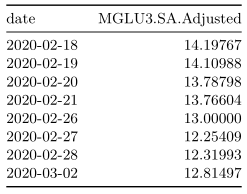
A primeira forma será utilizando a função na.locf(), do pacote {zoo}. Ela permite que o último valor, anterior ao NA, seja repetido para que seja feito esse preenchimento.
na.locf(mglu_na) %>%
tk_tbl(preserve_index = TRUE,
rename_index = "date") %>%
kable()
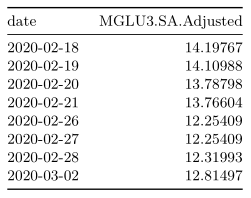
É possível também utilizar o valor adiante ao NA, passando o argumento fromLast = TRUE na função na.locf().
na.locf(mglu_na, fromLast = TRUE) %>%
tk_tbl(preserve_index = TRUE,
rename_index = "date") %>%
kable()
Outra forma de resolver o problema, pode ser preenchendo o dado faltante de forma manual, com a função na.fill(), passando no argumento fill o valor desejado.
na.fill(mglu_na, fill = 13) %>%
tk_tbl(preserve_index = TRUE,
rename_index = "date") %>%
kable()
Pode-se utilizar a função na.omit() para que o valor seja simplesmente retirado da série de preços.
na.omit(mglu_na) %>%
tk_tbl(preserve_index = TRUE,
rename_index = "date") %>%
kable()

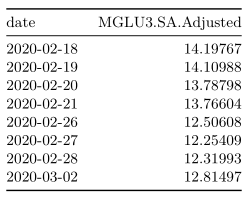
Por fim, uma forma interessante é utilizar a função na.approx() do pacote {zoo}. A função realiza uma interpolação linear para preencher o valor faltante.
na.approx(mglu_na) %>%
tk_tbl(preserve_index = TRUE,
rename_index = "date") %>%
kable()
plot(na.approx(Ad(MGLU3.SA)))
________________________
(*) Para entender mais sobre Mercado Financeiro e aprender como realizar a coleta, tratamento e visualização de dados financeiros, confira nosso curso de R para o Mercado Financeiro.

