"Primeiro eu queria cumprimentar os internautas: oi internautas!"
- Roussef, DILMA. 2010
Tudo bem, seres humanos? Este é meu primeiro post aqui no blog e, comovido pelos protestos que tomaram as ruas do país e pelo recente afastamento-e-retorno do presidente do Senado, escolhi falar sobre o seguinte tema: cota parlamentar.
Antes de analisar qualquer coisa, é bom entender um pouco sobre o tema, não é mesmo?
No site da Câmara dos Deputados[1] lemos o seguinte:
"O Ato da Mesa nº 43 de 2009, que detalha as regras para o uso da CEAP, determina que só podem ser indenizadas despesas com passagens aéreas; telefonia; serviços postais; manutenção de escritórios de apoio à atividade parlamentar; assinatura de publicações; fornecimento de alimentação ao parlamentar; hospedagem; outras despesas com locomoção, contemplando locação ou fretamento de aeronaves, veículos automotores e embarcações, serviços de táxi, pedágio e estacionamento e passagens terrestres, marítimas ou fluviais; combustíveis e lubrificantes; serviços de segurança; contratação de consultorias e trabalhos técnicos; divulgação da atividade parlamentar, exceto nos 120 dias anteriores às eleições; participação do parlamentar em cursos, palestras, seminários, simpósios, congressos ou eventos congêneres; e a complementação do auxílio-moradia."
Ok, digamos que você queira conferir se seu deputado só utilizou sua cota nestas categorias, ou que você queira fazer alguma análise mais geral. Como fazer isso com R?
Felizmente 80% do trabalho já está feito, devido ao genial @dfalbel. Neste repositório no GitHub[2] já existe código R para transformar o XML "feio" do site da Câmara em arquivos CSV. Aliás, no repositório encontramos 3 coisas importantíssimas:
1. Descrição dos dados
2. Exemplo (dados 2016)
3. Código para reproduzir os resultados
Com o código encontrado no repositório, criei dois dataframes - dados_2015 e dados_2016. Os seus CSVs respectivos estão aqui[3]. Vamos olhar?
library(tidyverse)
library(lubridate)
options(scipen=999) ## Nada de notação científica
dados_2015 <- read_rds("data/processed/cota-parlamentar-2015.rds")
dados_2016 <- read_rds("data/processed/cota-parlamentar-2016.rds")
## Juntando e selecionando apenas as colunas mais importantes
dados <- rbind(
dados_2015 %>%
select(
datEmissao,
nuCarteiraParlamentar,
nuDeputadoId,
sgPartido,
sgUF,
txtCNPJCPF,
txtDescricao,
txtFornecedor,
txNomeParlamentar,
vlrLiquido
),
dados_2016 %>%
select(
datEmissao,
nuCarteiraParlamentar,
nuDeputadoId,
sgPartido,
sgUF,
txtCNPJCPF,
txtDescricao,
txtFornecedor,
txNomeParlamentar,
vlrLiquido
)
)
## Ajustando tipos das colunas
dados <- dados %>%
mutate(
vlrLiquido = as.numeric(vlrLiquido),
datEmissao = as_date(datEmissao)
)
head(dados) # Vamos ver!
#
# datEmissao nuCarteiraParlamentar nuDeputadoId sgPartido sgUF txtCNPJCPF
# 1 2015-11-14 1 3074 DEM RR 05939467000115
# 2 2015-12-10 1 3074 DEM RR 05939467000115
# txtDescricao
# 1 MANUTENÇÃO DE ESCRITÓRIO DE APOIO À ATIVIDADE PARLAMENTAR
# 2 MANUTENÇÃO DE ESCRITÓRIO DE APOIO À ATIVIDADE PARLAMENTAR
# txtFornecedor txNomeParlamentar vlrLiquido
# 1 COMPANHIA DE AGUAS E ESGOTOS DE RORAIMA ABEL MESQUITA JR. 165.65
# 2 COMPANHIA DE AGUAS E ESGOTOS DE RORAIMA ABEL MESQUITA JR. 59.48
Bacana! Agora vamos desenhar os top 10 fornecedores:
## Top Fornecedores
top_fornecedores <- dados %>%
group_by(txtCNPJCPF, txtFornecedor) %>%
summarise(
totalRecebido = sum(vlrLiquido)
) %>%
ungroup() %>%
arrange(desc(totalRecebido)) %>%
filter(!(
stringr::str_detect(txtFornecedor, "Cia Aérea"))) %>%
head(10) %>%
mutate(order = as.factor(row_number()))
top_fornecedores.plot <-
ggplot(top_fornecedores) +
aes(x = order,
y = totalRecebido/1000000) +
geom_bar(stat = "identity") +
scale_x_discrete(labels = top_fornecedores$txtFornecedor, breaks = order) +
labs(title = "Top Fornecedores 2015/16",
x = "Fornecedor",
y= "Valor recebido (R$1m)")+
theme(
axis.text.x=element_text(size = 8)
) +
coord_flip()
O código acima gerou o seguinte gráfico:
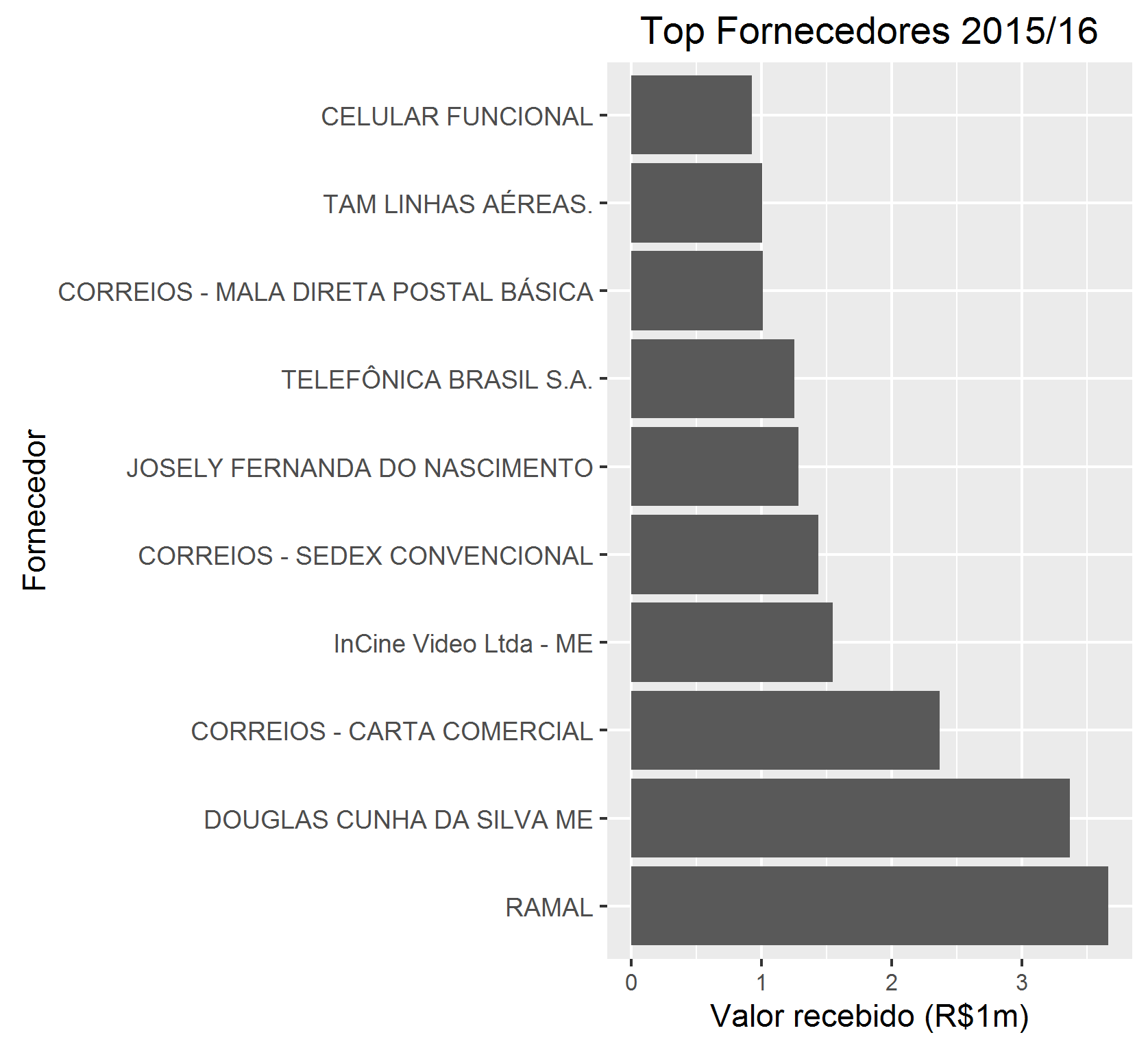
Repare no uso da função filter: tiramos os gastos com cias aéreas. Você consegue explicar o motivo?
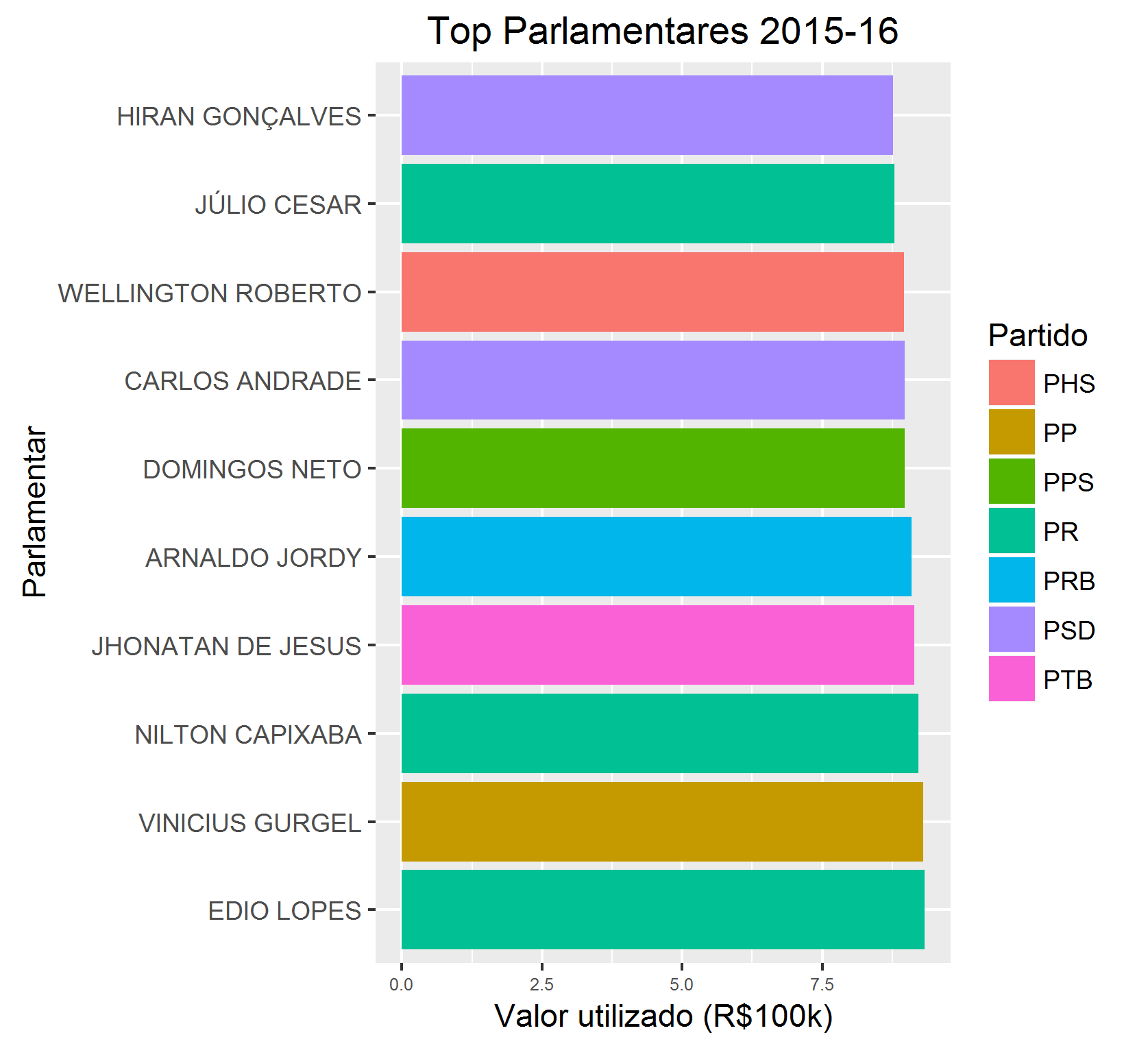
Podemos alterar só um pouco o código e fazer o mesmo para ter o top 10 parlamentares e as top 10 atividades:
## Top 10 parlamentares
top_parlamentares <- dados %>%
group_by(nuDeputadoId, txNomeParlamentar, nuCarteiraParlamentar, sgPartido) %>%
summarise(
totalUtilizado = sum(vlrLiquido)
) %>%
ungroup() %>%
arrange(desc(totalUtilizado)) %>%
head(10) %>%
mutate(order = as.factor(row_number()))
top_parlamentares.plot <-
ggplot(top_parlamentares) +
aes(x = order,
y = totalUtilizado/(10^5),
fill = sgPartido) +
geom_bar(stat = "identity") +
scale_x_discrete(labels = top_parlamentares$txNomeParlamentar, breaks = order) +
labs(title = "Top Parlamentares 2015-16",
x = "Parlamentar",
y= "Valor utilizado (R$100k)") +
guides(fill = guide_legend(title = "Partido"))+
theme(
axis.text.x=element_text(size = 6)
) +
coord_flip()
## Top Atividades
top_atividades <- dados %>%
group_by(txtDescricao) %>%
summarise(
totalUtilizado = sum(vlrLiquido)
) %>%
ungroup() %>%
arrange(desc(totalUtilizado)) %>%
head(10) %>%
mutate(order = as.factor(row_number()))
top_atividades.plot <-
ggplot(top_atividades) +
aes(x = order,
y = totalUtilizado/1000000) +
geom_bar(stat = "identity") +
scale_x_discrete(labels = top_atividades$txtDescricao, breaks = order) +
labs(title = "Top Atividades 2015/16",
x = "Atividade",
y= "Valor utilizado (R$1m)") +
theme(
axis.text.y=element_text(size = 6)
) +
coord_flip()
Com isso, temos:

Que acha de desenharmos a série? Também é fácil:
## Gastos ao longo do tempo
serie_gastos <- dados %>%
filter(
!is.na(datEmissao)
) %>%
mutate(
Ano = year(datEmissao),
Mes = month(datEmissao),
Data = as_date(paste(Ano,Mes,"01",sep = "-"))
) %>%
group_by(Data) %>%
summarise(
totalMensal = sum(vlrLiquido)
) %>%
mutate(
totalAcumulado = cumsum(totalMensal)
)
serie_gastos.plot <-
ggplot(serie_gastos) +
aes(x = Data,
y = totalMensal/1000000) +
geom_jitter() +
geom_smooth(span = 0.3, method = "loess") +
labs(title = "Utilização mensal - Cota Parlamentar",
x = "Ano-Mês",
y= "Valor utilizado (R$1m)")
Essa série eu deixo pro mestre Wilher interpretar! 🙂
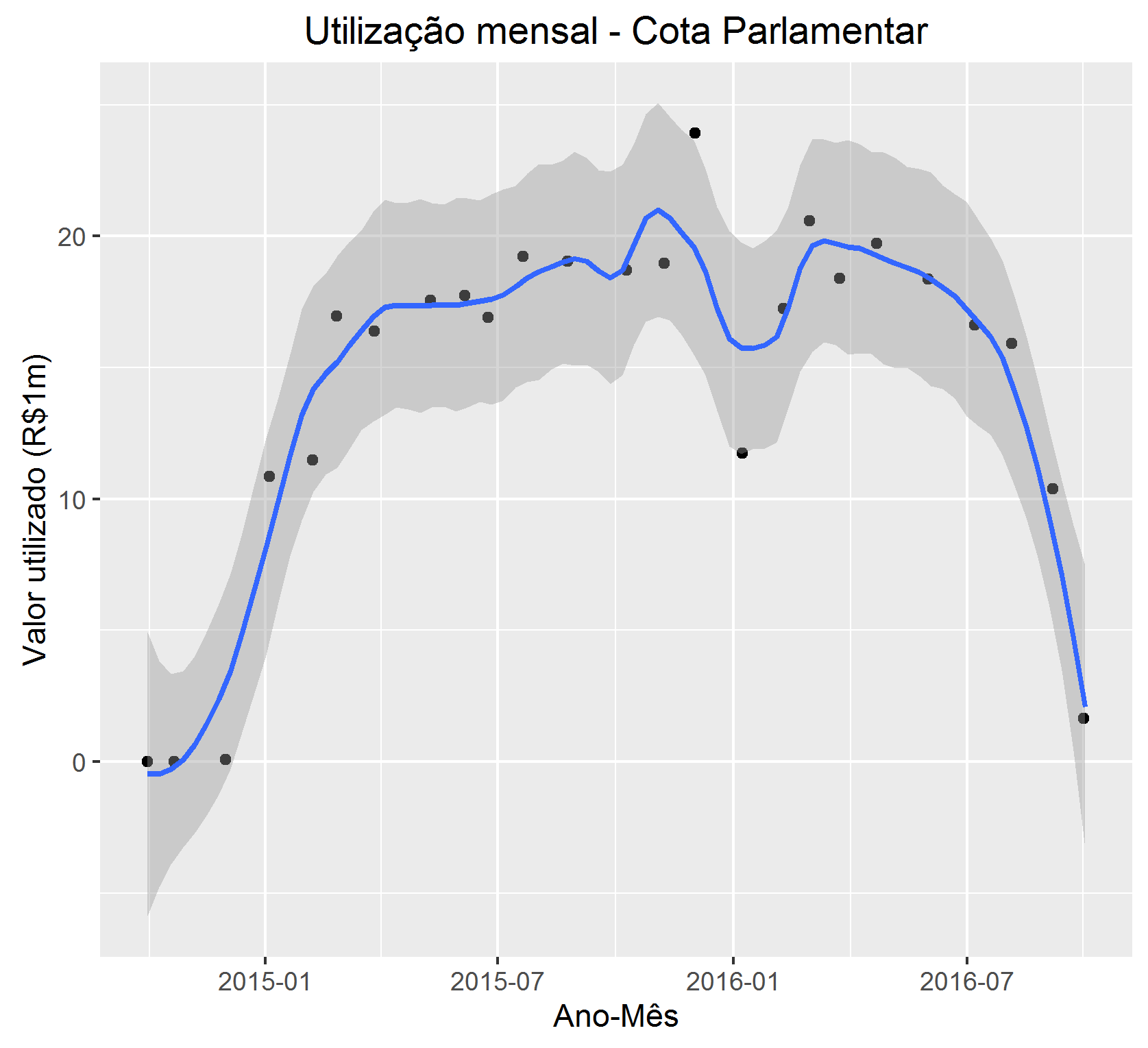
Na série, não vimos todos os valores porque muitos não tem data (NA no nosso dataset) e filtramos eles logo no início. Vamos entender quanto ficou de fora, e qual a descrição desses gastos?
## Entendendo o valor que ficou fora da análise
datas_na <- dados %>%
filter(
is.na(datEmissao)
) %>%
group_by(txDescricao) %>%
summarise(
total = sum(vlrLiquido)
)
head(datas_na)
#
# # A tibble: 1 x 2
# txtDescricao total
# <chr> <dbl>
# 1 TELEFONIA 3923815
# 3m de gastos com telefonia sem data! Pode isso, Arnaldo?
Resumindo
Vimos como analisar rapidamente alguns dados públicos em R.
E agora é com vocês: que acharam? Devo aprofundar a análise destes dados públicos?
Até a próxima!
Referências:
[1] http://www2.camara.leg.br/participe/fale-conosco/perguntas-frequentes/cota-para-o-exercicio-da-atividade-parlamentar
[2] https://github.com/dfalbel/cota-parlamentar
[3] Download dos dados

