Dia desses, publiquei aqui no Blog um post sobre o projeto maddison, que busca publicar dados de pib per capita de todos os países do mundo para tempos remotos. Um baita trabalho de história econômica, diga-se de passagem. Com base no respectivo pacote maddison no R, a propósito, é possível fazer comparações de pib per capita entre diversos países...
Por exemplo, muitas pessoas gostam de falar do sistema de proteção social da Suécia e, indubitavelmente, querem ter esse sistema aqui no Brasil. O problema desse tipo de coisa é que ela não leva em conta, justamente, o tal do pib capita. Abaixo, fazendo uso do pacote maddison, nós pegamos o dado para os dois países.
library(maddison)
df = subset(maddison, year >= '1870-01-01' &
iso2c %in% c('BR', 'SE'))
E a seguir, colocamos um gráfico.
ggplot(df, aes(x=year, y=gdp_pc, colour=country))+
geom_line(size=.8)+
scale_colour_manual('',values=c('Brazil'='darkblue',
'Sweden'='orange'))+
scale_x_date(breaks='10 years',
date_labels = '%Y')+
labs(x=NULL, y='PIB per capita (GK dólar int, 1990)',
title='PIB per capita: Brasil vs. Suécia',
subtitle='Fonte: Maddison Project Dataset')+
theme(panel.background = element_rect(fill='#acc8d4',
colour='#acc8d4'),
plot.background = element_rect(fill='#8abbd0'),
axis.line = element_line(colour='black',
linetype = 'dashed'),
axis.line.x.bottom = element_line(colour='black'),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
legend.position = c(.4,.5),
legend.background = element_rect((fill='#acc8d4')),
legend.key = element_rect(fill='#acc8d4',
colour='#acc8d4'),
plot.margin=margin(5,5,15,5))+
annotation_custom(g,
xmin=as.Date('1870-01-01'),
xmax=as.Date('1893-01-01'),
ymin=15000, ymax=25000)
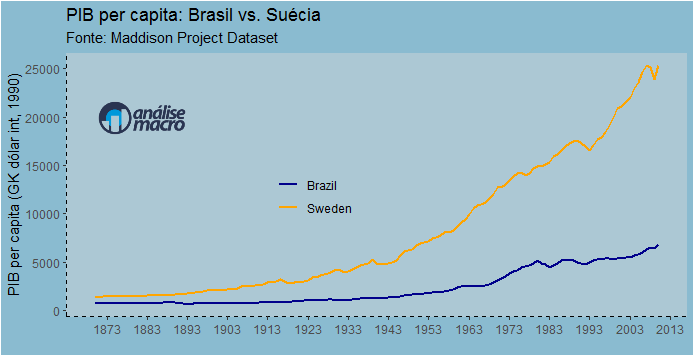
No início da série, 1870, a Suécia tinha um pib per capita cerca de 1.9 maior do que o Brasil. No último dado da série, 2010, o pib per capita da Suécia é cerca de 3.7 maior do que o nosso. Em outras palavras, houve um processo de divergência entre os dois países.

