Já comentei aqui nesse espaço sobre o projeto maddison, que busca publicar dados históricos de pib per capita para diversos países. Dentro desse fantástico banco de dados, há dados do pib per capita das duas Coreias, separadas em meados do século passado. A trajetória das duas Coreias é um desses laboratórios práticos sobre as diferenças existentes entre dois modelos de organização social e econômica. Os dados são baixados através do pacote maddison abaixo.
library(maddison)
df = subset(maddison, year>='1950-01-01' &
iso2c %in% c('KP', 'KR'))
Com os dados em mãos, podemos gerar o gráfico a seguir...
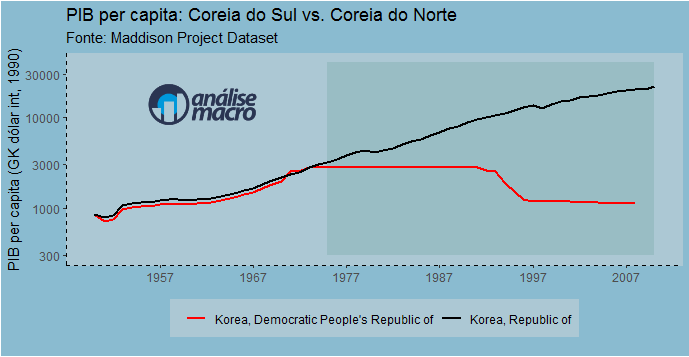
Difícil achar comparação mais nítida entre dois modelos de organização social e econômica do que esse, bem como seus resultados práticos, não é mesmo?


