1 O que vamos construir
O entregável é um relatório do IPCA em HTML, igual aos que bancos e consultorias publicam todo mês — só que ele se reescreve sozinho a cada divulgação do índice. Concretamente, ao rodar um comando você obtém:
- os gráficos e tabelas de sempre (inflação cheia contra a meta, núcleos, padrão sazonal, contribuição dos grupos), recalculados com os dados novos;
- os textos analíticos do mês — uma síntese da surpresa em relação ao Focus, a leitura de cada bloco e a investigação de por que o número veio como veio — escritos a partir do release do IBGE, do noticiário e da ata do Copom;
- a garantia de que todo número no texto existe nos dados, conferida antes de o relatório ser gerado.
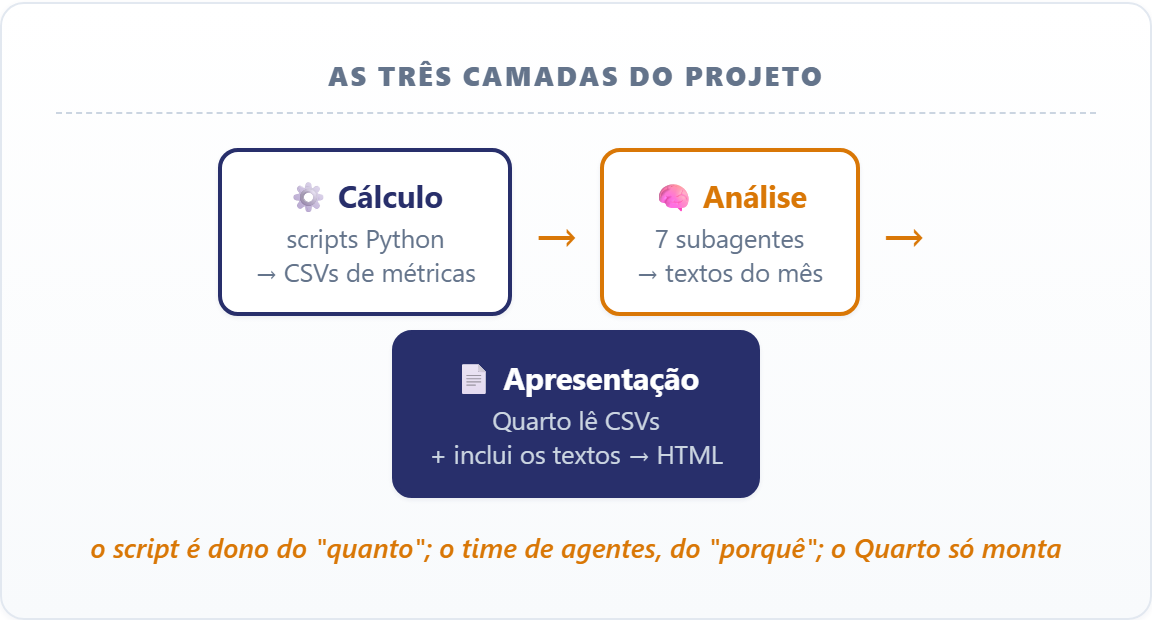
O que torna isso possível é separar dois tipos de trabalho. O cálculo, o gráfico e a tabela são determinísticos, porque um script Python resolve e o resultado é sempre conferível. Já a interpretação, que exige pesar evidências dispersas e escrever uma narrativa defensável, não tem gabarito, e é aí que entram os agentes. A aula inteira gira em torno de decidir o que vai para cada lado dessa divisão.
1.1 A arquitetura em uma olhada
Três camadas, com fronteiras nítidas entre elas:
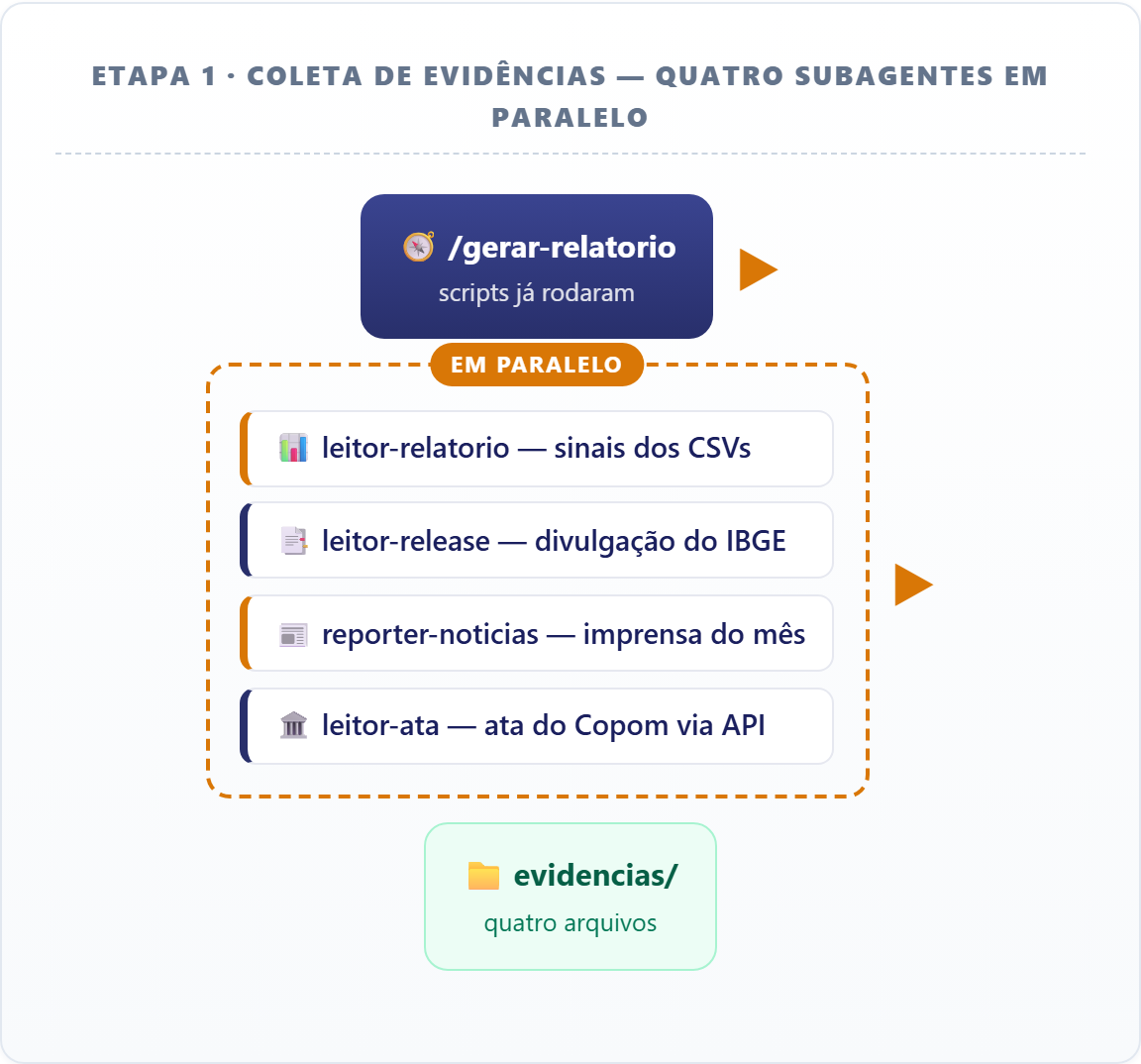
A camada de análise é a parte nova desta aula, e por dentro ela é um time de subagentes que roda em duas etapas. Primeiro, quatro coletores buscam evidência em paralelo, cada um numa fonte:
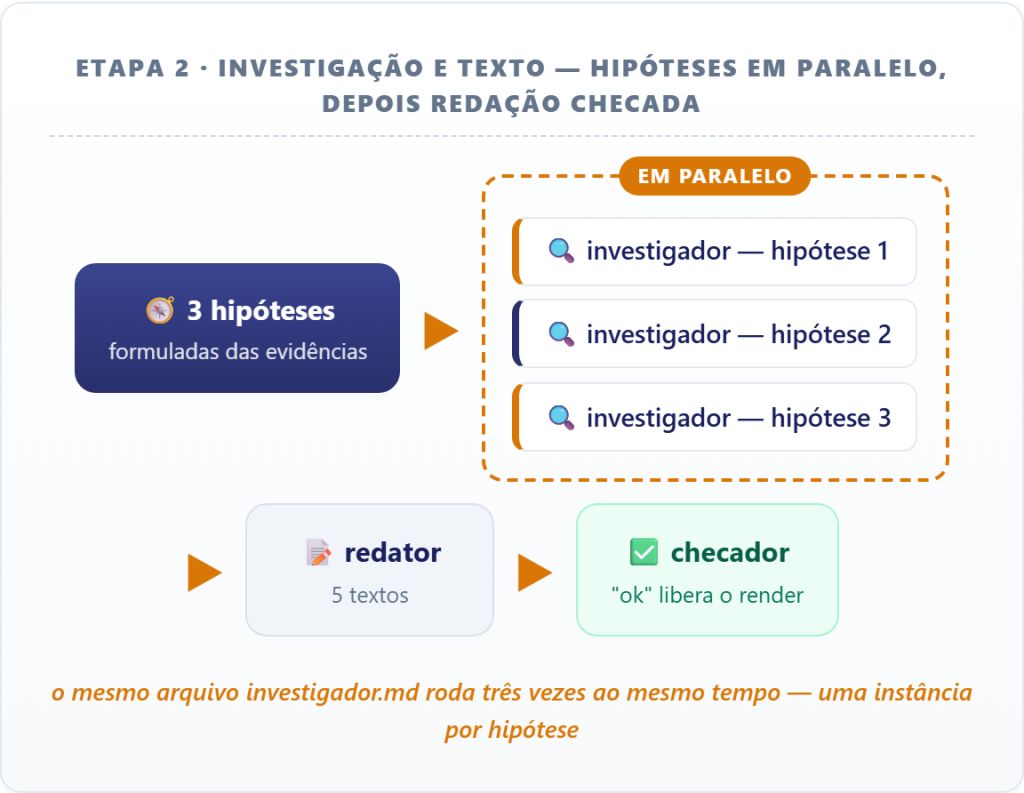
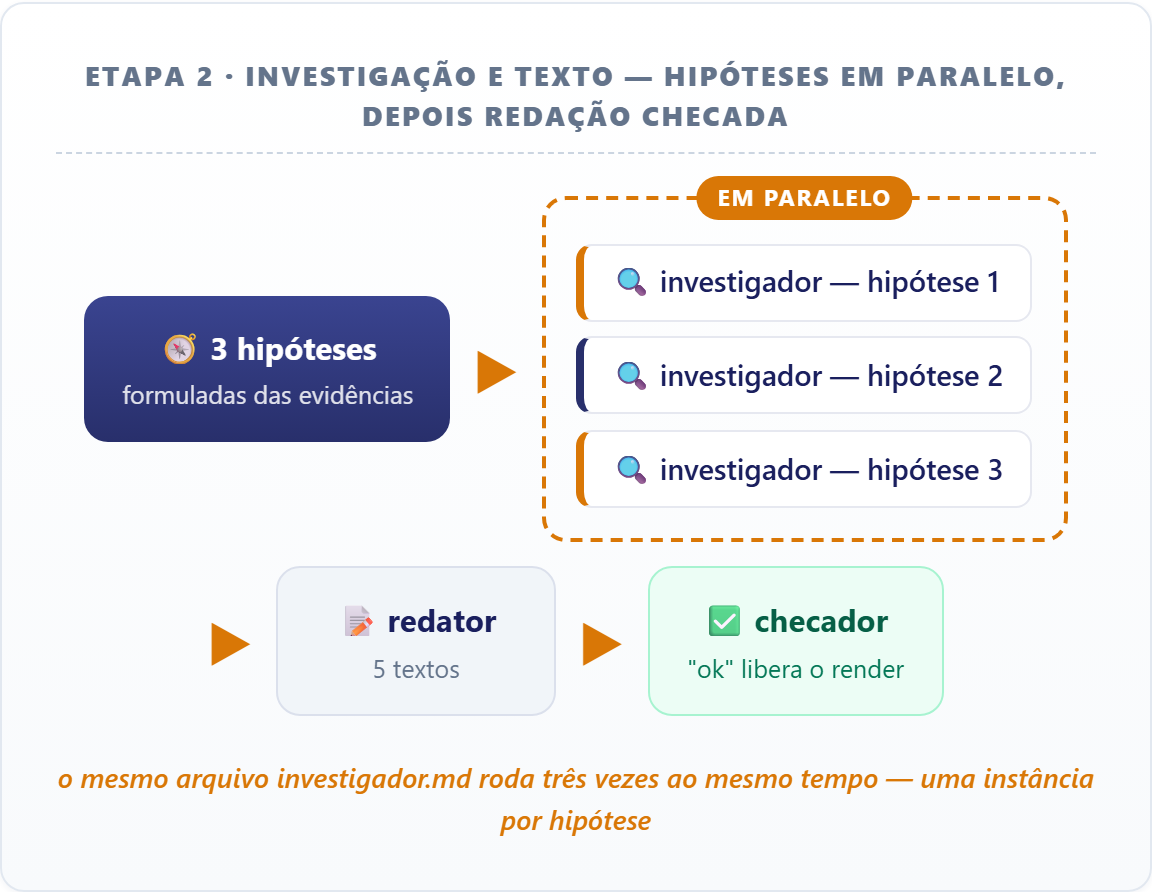
 Depois, três investigadores testam hipóteses para a surpresa (também em paralelo), um redator escreve os textos e um checador confere cada número antes de liberar o render:
Depois, três investigadores testam hipóteses para a surpresa (também em paralelo), um redator escreve os textos e um checador confere cada número antes de liberar o render:
2 Os mecanismos de agente no Claude Code
2 Os mecanismos de agente no Claude Code
“Sistema de agentes” virou guarda-chuva para coisas bem diferentes. O Claude Code oferece quatro mecanismos, e escolher o errado sai caro porque adiciona complexidade, gasta mais tokens ou exige uma coordenação que não compensa. Separá-los antes de montar o projeto evita o erro mais comum, que é aplicar um mecanismo elaborado a um problema que pedia algo simples — a aula usa um deles de propósito.
| Mecanismo | O que é | Quando usar |
|---|---|---|
| Subagente | Um auxiliar que o agente principal invoca para uma tarefa; roda em contexto próprio e devolve só o resultado. É um arquivo em .claude/agents/. |
Delegar uma tarefa especializada e recuperar o resultado sem inchar a conversa principal. É o que esta aula usa. |
| Equipe de agentes | Várias instâncias do Claude Code rodando lado a lado, que trocam mensagens entre si e dividem uma lista de trabalho comum. | Tarefas longas em que os agentes precisam negociar entre si. Experimental, desligada por padrão, cada instância custa contexto próprio. |
| Workflow | Um script que orquestra subagentes de forma determinística — laços, condições, fan-out — em vez de deixar o modelo decidir a ordem. | Quando a sequência de orquestração precisa ser fixa e repetível (uma varredura, uma migração, uma revisão multi-etapa). |
| Worktree | Uma cópia isolada do repositório (via git worktree) onde um agente trabalha sem colidir com os outros. |
Quando vários agentes editam arquivos ao mesmo tempo e pisariam no trabalho um do outro. |
O projeto desta aula é um caso de subagentes mais um orquestrador, e a escolha tem motivo em cada linha:
- Subagentes, não equipe. Os coletores não precisam negociar nada entre si — o que a ata do Copom diz independe do que saiu no jornal. Cada um faz sua parte e entrega; quem junta os resultados é o agente principal. Equipe seria coordenação cara para um problema que não pede coordenação.
- Um slash command, não um workflow. A ordem do nosso pipeline é fixa, mas curta e linear o bastante para caber num comando em linguagem natural (
.claude/commands/). O agente principal lê o comando e segue os passos. Workflow-como-script faz sentido quando a orquestração tem laços e ramificações que você quer blindar contra improviso — não é o caso aqui. - Sem worktree. Os subagentes escrevem em arquivos distintos (
evidencias/release_ibge.md,evidencias/noticias.md…), nunca no mesmo. Sem risco de colisão, isolamento de repositório seria peso morto. - Paralelo, mas plano. Os quatro coletores rodam ao mesmo tempo porque o agente principal os dispara numa única mensagem — isso é fan-out de subagentes, não uma equipe. Eles continuam sem se falar; o paralelismo serve só para ganhar tempo.
Informação:
A distinção que mais confunde é subagente em paralelo versus equipe de agentes. Os dois têm “vários agentes ao mesmo tempo”, mas no primeiro eles são mudos entre si e respondem só ao principal (é o nosso caso); no segundo eles conversam e se coordenam. Para quase todo pipeline de análise de dados, o fan-out de subagentes basta — e é muito mais barato.
3 A pergunta que o script não responde
Em 9 de abril de 2026, a pesquisa Focus do Banco Central registrava mediana de 0,60% para o IPCA de março, com 151 instituições respondendo. Dias depois o IBGE divulgou o número: 0,88%. Uma surpresa de 0,28 ponto percentual para cima.

Calcular a surpresa é uma subtração: qualquer script faz. A pergunta que paga o salário do analista é outra — por que o número veio tão acima?
A resposta de março estava espalhada em quatro lugares diferentes: na abertura por grupos do IBGE (alimentação acelerando), no noticiário (conflitos no Oriente Médio pressionando commodities), na ata do Copom (que registrou leituras de alimentos “significativamente acima das inicialmente esperadas”) e no padrão sazonal histórico (março costuma ser mais leve). Juntar isso e escrever três parágrafos defensáveis exige ler, comparar e julgar — e nada disso cabe num script.
3.1 O quanto e o porquê
Essa divisão organiza a aula inteira e o projeto que vamos montar:
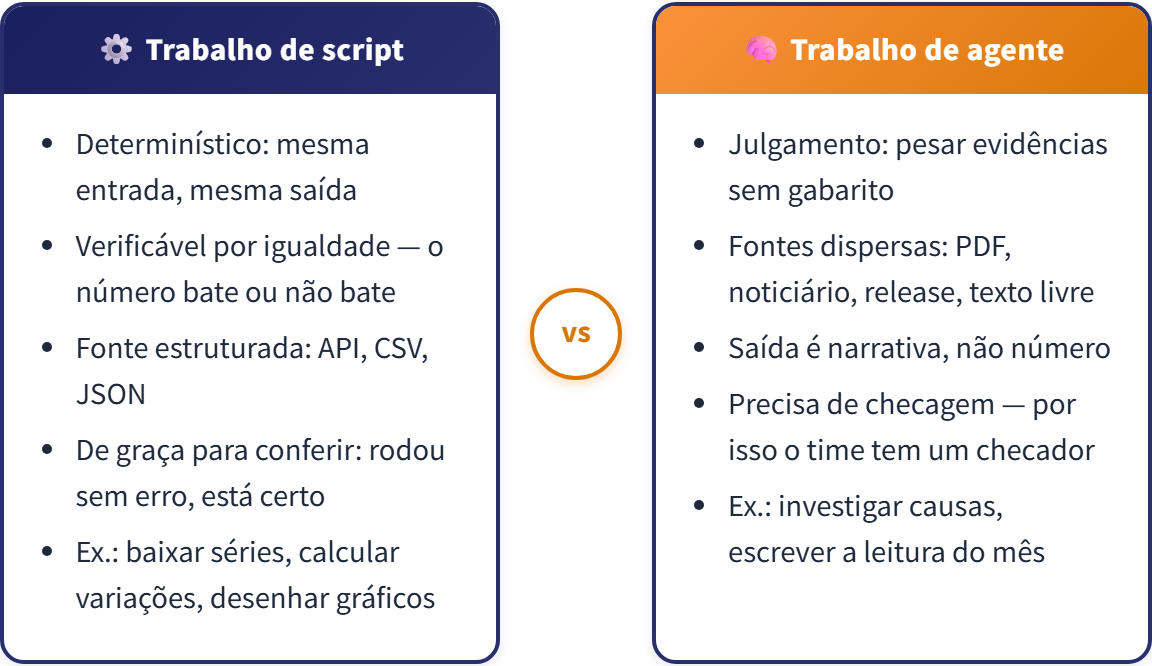
- O quanto é determinístico. Baixar a série do SGS, buscar a mediana na API do Focus, subtrair, calcular o acumulado em 12 meses, desenhar o gráfico: mesma entrada, mesma saída, conferível por igualdade. Trabalho de script.
- O porquê não tem gabarito. Exige juntar evidências de fontes dispersas, pesar umas contra as outras e escrever uma narrativa que um leitor exigente aceite. Trabalho de agente — e, como veremos, de um time de agentes, porque as evidências vêm de lugares diferentes e podem ser coletadas ao mesmo tempo.
4 Script ou agente: o critério
Antes de criar qualquer subagente, vale fixar o critério que decide para onde vai cada tarefa. Três perguntas resolvem a maioria dos casos:
- A tarefa é determinística? Mesma entrada produz sempre a mesma saída?
- O resultado é verificável por igualdade? Dá para conferir com um
==, um teste, uma comparação de números? - A fonte é estruturada? API com JSON, CSV com colunas conhecidas, tabela com layout fixo?
Se a resposta às três for sim, escreva um script. Se qualquer uma for não, provavelmente é caso de agente.
requests + pandas não precisa de revisão: se o script rodou, o valor é o que a API devolveu. Número que sai de um modelo de linguagem precisa ser conferido sempre, porque o modelo pode produzir um valor errado com a mesma naturalidade com que produz um certo, sem sinalizar a diferença. Delegar cálculo a um agente, portanto, é pagar duas vezes: uma pela geração, outra pela conferência que ela obriga.
4.1 O erro comum: agente calculando
src/ de uma vez. Os agentes ficam só com o que nenhum script entrega: leitura, investigação e texto.
5 Subagentes, o essencial em uma página
Um subagente é um auxiliar especializado que o agente principal invoca para uma tarefa: ele roda numa conversa própria, com contexto separado, faz o trabalho e devolve só o resultado. O principal não vê os passos intermediários do auxiliar — e é isso que mantém a conversa principal enxuta mesmo quando o trabalho por trás é extenso.

5.1 A anatomia do arquivo
.claude/agents/, criado pelo comando /agents ou escrito direto. O cabeçalho YAML tem quatro campos; o corpo é a instrução de trabalho. Um exemplo de um revisor de relatório mostra o formato:
---
name: revisor
description: Revisa o relatório antes da publicação
tools: Read, Write
model: sonnet
---
Confere no relatório:
1. Números batem com os CSVs de origem
2. Unidades corretas (Selic em p.p., não pontos-base)
...
Limites: não edita o relatório — só aponta.Cada campo tem um papel prático:
name— como o agente principal (e você) chama o subagente.description— o gatilho da delegação automática: é o que o Claude lê para decidir se a tarefa encaixa. Escreva-a específica e com verbo (“revisa o boletim antes da publicação”), não vaga (“ajuda com o relatório”).tools— o cinto de segurança. Um coletor de evidências não precisa deEdit; um checador não deve escrever no relatório. Menos ferramentas, menos forma de errar.model— subagente de tarefa pontual roda bem com um modelo mais barato; reserve o modelo maior para o agente principal que orquestra.
E uma convenção que vale ouro no corpo: termine com os limites (“não calcula”, “não opina”, “só aponta”). Subagente sem limite explícito tende a fazer mais do que devia — e o excesso de um contamina o trabalho do outro.
5.2 Fila ou paralelo
Subagentes podem trabalhar de dois jeitos. Em fila, quando cada um depende do resultado do anterior e a ordem é obrigatória. Ou em paralelo, quando o agente principal dispara várias Tasks numa única mensagem e elas trabalham ao mesmo tempo, cada uma no seu contexto. Este projeto usa os dois: os coletores rodam em paralelo, mas o redator só começa depois que as investigações terminam.

O paralelo é seguro quando duas condições valem: as tarefas não leem o resultado umas das outras, e cada uma escreve num arquivo diferente. É o caso dos nossos coletores de evidência, porque o que a ata do Copom diz não depende do que saiu no jornal. Por isso cada subagente deste projeto tem um arquivo de saída próprio, nomeado no seu corpo, de modo que todos gravam na mesma pasta sem que um sobrescreva o texto do outro.
Os subagentes não falam entre si. Quem coleta os resultados e alimenta a etapa seguinte é sempre o agente principal — no nosso caso, guiado por um comando que você vai escrever no Passo 7.
6 O projeto: as fontes e o ponto de partida
O ponto de partida é um relatório de IPCA que você já tem pronto, em relatorio/relatorio-ipca.qmd, com os gráficos e tabelas de um trabalho profissional. Ele coleta os dados via SGS e SIDRA e a partir deles calcula a dessazonalização, o acumulado em 12 meses e a média móvel anualizada (SAAR), além de trazer os núcleos, o padrão sazonal e a abertura por grupos com a contribuição de cada um em pontos percentuais. O que ele não tem é o texto: a leitura do mês que um analista escreveria embaixo de cada gráfico. É aí que entra o time que você viu no diagrama.
O encaixe entre as camadas tem um detalhe que vale fixar antes de começar: o relatório Quarto inclui os textos de textos/ em vez de gerá-los, e essa pasta é a única parte reescrita a cada divulgação. Se os agentes falharem, o relatório ainda renderiza com os textos do mês anterior, porque a parte determinística não depende de os agentes terem rodado.
As cinco fontes que o time consome, com as pegadinhas que custaram tentativa e erro:
| Fonte | Onde | Pegadinha |
|---|---|---|
| IPCA realizado | BCB SGS, série 433 (JSON) | valor vem como string com ponto decimal |
| Mediana Focus | API Olinda, recurso ExpectativaMercadoMensais |
espaço no filtro tem que ser %20; o + padrão do requests dá erro 400 |
| Grupos do IPCA | SIDRA, tabelas 7060 e 1737 (sidrapy) | primeiro elemento da resposta é cabeçalho, não dado |
| Ata do Copom | bcb.gov.br/api/servico/sitebcb/atascopom/ultimas |
filtro= vazio é obrigatório — sem ele, HTTP 500 |
| Release do IBGE | API de notícias + caderno PDF no FTP público | a Agência de Notícias bloqueia robôs (Cloudflare) — use a API |
O site do BCB bloqueia IPs de nuvem. Este pipeline foi desenhado para rodar na sua máquina — os coletores baixam PDF do BCB e do IBGE direto, o que funciona localmente e falharia numa execução agendada na nuvem sem adaptação.
Daqui em diante, o guia segue o formato dos guias de Git/GitHub: cada passo traz o prompt para colar no Claude Code, o que ele vai gerar e como conferir que deu certo. O projeto pronto está em claude-code-08/meu-projeto/ — use-o como gabarito quando o seu resultado divergir.
7 Passo 1 — A fundação: pastas e o CLAUDE.md
Todo projeto das aulas começa igual: uma pasta, um CLAUDE.md com as regras e a estrutura vazia que os scripts e agentes vão preencher. A novidade aqui é que o CLAUDE.md precisa registrar a divisão de trabalho — scripts calculam, agentes interpretam — porque é ela que os subagentes vão consultar quando tiverem dúvida sobre o próprio papel.
Parta da pasta do seu relatório de IPCA — aquele .qmd que já calcula e desenha os gráficos. Abra o Claude Code nela e cole:
Prompt:
Este projeto gera um relatório mensal do IPCA em que gráficos e tabelas
saem de scripts Python e os textos analíticos são escritos por subagentes
a cada divulgação. Crie a estrutura de pastas e o CLAUDE.md.
Pastas: src/, relatorio/dados/, textos/, dados/brutos/, evidencias/,
investigacoes/, output/, logs/, .claude/agents/, .claude/commands/.
O CLAUDE.md deve registrar:
- A divisão inegociável: cálculo, gráfico e tabela são trabalho de script;
interpretação, investigação e narrativa são trabalho de agente. Nenhum
agente calcula número novo; nenhum script opina.
- Um mapa de pastas dizendo quem escreve em cada uma.
- As fontes: SGS 433 (IPCA), SGS 13521 (meta), núcleos 11427/27839/4466/
16122/28750, Focus via API Olinda (ExpectativaMercadoMensais, baseCalculo
eq 0), SIDRA 7060 e 1737, ata do Copom via
https://www.bcb.gov.br/api/servico/sitebcb/atascopom/ultimas?quantidade=1&filtro=
(o filtro= vazio é obrigatório, sem ele dá HTTP 500), release do IPCA via
https://servicodados.ibge.gov.br/api/v3/noticias/?qtd=10&busca=IPCA
— nunca acessar agenciadenoticias.ibge.gov.br, que bloqueia robôs.
- Convenções: CSVs com sep=";" e decimal=","; mês de referência é o último
disponível na SGS 433, nunca o calendário; números no texto em pt-BR.
- Regras: nunca inventar número (todo número citado existe nos CSVs);
o checador dá a palavra final; máximo 2 ciclos redator-checador;
falha de script para o pipeline.
- A lista de vícios de texto a evitar, a mesma do projeto Focus.
Também crie o requirements.txt: requests, pandas, python-bcb, sidrapy,
statsmodels, plotnine, mizani, great-tables, jupyter.O que o Claude vai gerar. A árvore de pastas e um CLAUDE.md parecido com o do projeto pronto — confira lá o texto completo. O trecho que importa é o primeiro bloco:
## O projeto
Todo mês, na divulgação do IPCA, o comando /gerar-relatorio refaz o
relatório completo: scripts Python baixam os dados e calculam as métricas,
um time de subagentes investiga por que o número surpreendeu a mediana do
Focus e escreve os textos analíticos, e o Quarto monta o HTML final.
**Divisão inegociável**: cálculo, gráfico e tabela são trabalho de script.
Interpretação, investigação de causas e narrativa são trabalho de agente.
Nenhum agente calcula número novo; nenhum script opina.As dez pastas existem, o requirements.txt tem as nove bibliotecas e o CLAUDE.md traz a divisão script/agente logo no topo. Rode pip install -r requirements.txt antes de seguir — o Passo 3 depende dessas bibliotecas.
8 Passo 2 — O quanto, em um script: surpresa.py
O primeiro script responde “o quanto”: baixa o IPCA realizado na SGS, busca na API do Focus a mediana esperada e grava a diferença — não só do mês, mas dos últimos doze, para a investigação enxergar se a surpresa é pontual ou parte de uma sequência. Repare que o prompt já carrega as descobertas que custariam tentativa e erro, porque foi nele que ficaram registrados o nome do recurso na API Olinda e o filtro baseCalculo eq 0, junto com o encoding que esse filtro exige e o corte temporal da pesquisa Focus.
Esse corte temporal é o detalhe que separa uma surpresa honesta de uma forjada. A mediana do Focus tem que ser a da última pesquisa anterior à divulgação do IPCA daquele mês — senão você compara o realizado com uma expectativa que já sabia o resultado, e toda surpresa vira zero.
Prompt:
Crie src/surpresa.py, que calcula a surpresa inflacionária: IPCA realizado
vs mediana do Focus. Uso: python src/surpresa.py [AAAA-MM] (sem argumento,
usa o último mês disponível na SGS, nunca o calendário).
Gere 12 meses de histórico (o mês de referência + os 11 anteriores), para
que a investigação veja se a surpresa é pontual ou sequência.
- IPCA realizado: https://api.bcb.gov.br/dados/serie/bcdata.sgs.433/dados?formato=json&dataInicial=01/01/2024
(data vem como DD/MM/YYYY e valor como string com ponto)
- Mediana Focus, por mês: API Olinda, recurso ExpectativaMercadoMensais,
filtrando Indicador eq 'IPCA', DataReferencia eq 'MM/AAAA' e
baseCalculo eq 0. Use a última pesquisa ANTERIOR à divulgação do IPCA
desse mês (o IPCA sai ~dia 10 do mês seguinte): filtre Data le esse dia
e pegue $orderby=Data desc, $top=1. Atenção: a API exige espaço como %20
na query string — o "+" que o requests faz por padrão devolve erro 400,
então monte a URL com urllib.parse.quote. Mês sem Focus → linha sem
surpresa, não aborta.
- surpresa = realizado - mediana, em pontos percentuais.
- Saídas com sep=";" e decimal=",": dados/surpresa.csv (12 linhas, mês de
referência na primeira: mes_referencia, ipca_realizado, mediana_focus,
surpresa, data_pesquisa_focus, respondentes) e dados/ipca_historico.csv.
- Erro de fonte → SystemExit nomeando a fonte e a URL (o exit code != 0
para o pipeline depois). Um main() que imprime o resumo em uma linha.
Comente o código em português e me mostre o arquivo.O que o Claude vai gerar. O coração do script é a função que consulta o Focus — note a URL montada à mão por causa do %20 e o corte Data le que garante a expectativa pré-divulgação:
def mediana_focus(mes: str) -> dict | None:
"""Mediana da última pesquisa Focus anterior à divulgação do IPCA do mês."""
data_ref = f"{mes[5:7]}/{mes[0:4]}" # AAAA-MM -> MM/AAAA
corte = (pd.Timestamp(mes) + pd.offsets.MonthBegin(1) + pd.Timedelta(days=9)).strftime("%Y-%m-%d")
filtro = (
f"Indicador eq 'IPCA' and DataReferencia eq '{data_ref}' "
f"and baseCalculo eq 0 and Data le '{corte}'"
)
url = (
f"{URL_FOCUS}?$filter={quote(filtro, safe='')}"
"&$orderby=Data%20desc&$top=1&$format=json"
)
...Rode python src/surpresa.py. Quando esta aula foi escrita, o último mês com surpresa relevante era março de 2026:
IPCA 2026-03: 0.88 | mediana Focus: 0.6 | surpresa: +0.28 p.p. | histórico: 12 mesesUma surpresa de +0,28 p.p. — o IPCA veio bem acima do que o mercado esperava. E o surpresa.csv mostra que não foi um acaso: depois de meses de surpresas negativas ou nulas, fevereiro veio +0,20 e março +0,28 — duas leituras altistas em sequência, o tipo de virada que pede explicação.
dados/surpresa.csv tem 12 linhas (o mês de referência na primeira), com decimais em vírgula, e cada data_pesquisa_focus é anterior à divulgação do respectivo mês. Teste também o caminho do erro, que é metade do valor do script: python src/surpresa.py 2030-01 deve abortar com mensagem clara (“SGS 433 nao tem o mes 2030-01”), não com traceback.
9 Passo 3 — Separar o relatório em duas camadas
Seu relatório hoje faz tudo num arquivo só: as células calculam as métricas e desenham os gráficos. Para um time de agentes entrar, esse arquivo precisa virar dois. O motivo é direto: os agentes não rodam o seu .qmd, eles leem arquivos — e leem mal um .qmd cheio de código de plotagem. Se as métricas saírem para CSVs limpos, cada subagente lê o número que precisa sem reabrir a conta, e o relatório passa a só desenhar e incluir texto.
A regra da separação: o que produz número vai para um script (src/preparar_dados.py), o que produz figura ou tabela fica no .qmd. Os CSVs no meio viram a interface entre as duas camadas — e, de quebra, a fonte única que o checador vai usar para validar cada número do texto.
9.1 preparar_dados.py: as métricas viram CSVs
Prompt:
No meu relatório de IPCA, os cálculos e os gráficos estão juntos. Extraia
TODOS os cálculos para um script src/preparar_dados.py que salva CSVs em
relatorio/dados/ (sep=";", decimal=","), sem desenhar nada. Mantenha a
lógica que já está no relatório: decomposição sazonal aditiva (statsmodels),
acumulado 12m por produtório, MM3M SAAR = média móvel de 3 meses da série
dessazonalizada x 12, média dos 5 núcleos, mediana e quartis históricos por
mês, contribuição dos grupos = variação x peso / 100.
CSVs de saída:
- ipca_12m_meta.csv: data, ipca_12m, ipca_mm3m_saar, meta, limites (2018+)
- nucleos.csv: idem para a média dos núcleos (2020+)
- padrao_sazonal.csv: por mês, q25/mediana/q75 históricos + valores do ano
- ipca_grupos.csv: último mês por grupo — variações, peso, contribuição
- contribuicao_12m.csv: 12 meses de contribuição por grupo (p/ gráfico)
- acumulados.csv: variações do mês e acumulados 3m/6m/ano/12m (tabela 1737)
Cuidados: use header="n" no sidrapy; valide que o índice geral da 7060 bate
com a SGS 433 e que a SIDRA já tem o mês da SGS — se não tiver, SystemExit
pedindo para rodar mais tarde. Arredonde a 4 casas.O que o Claude vai gerar. Um script de ~280 linhas com uma função por CSV. As fórmulas saem iguais às que já estavam no relatório — o SAAR, por exemplo:
def acumular_12m(serie: pd.Series) -> pd.Series:
"""Acumula variações mensais em 12 meses por produtório."""
return ((serie / 100) + 1).rolling(12).apply(lambda y: (y.prod() - 1) * 100)
# ...
base["ipca_mm3m_saar"] = base["ipca_sa"].rolling(3).mean() * 12Rode python src/preparar_dados.py:
relatorio/dados/ipca_12m_meta.csv: 98 linhas
relatorio/dados/nucleos.csv: 75 linhas
relatorio/dados/padrao_sazonal.csv: 12 linhas
relatorio/dados/ipca_grupos.csv: 10 linhas
relatorio/dados/contribuicao_12m.csv: 108 linhas
relatorio/dados/acumulados.csv: 7 linhas
Mes de referencia do relatorio: 2026-03O ipca_grupos.csv de março já conta uma história — Transportes e Alimentação, juntos, respondem por mais de três quartos do índice:
grupo;variacao_mes;variacao_acum_ano;variacao_acum_12m;peso;contribuicao
Índice geral;0,88;1,92;4,14;100,0;0,88
5.Transportes;1,64;3,01;3,69;20,4516;0,3354
1.Alimentação e bebidas;1,56;2,07;2,16;21,3095;0,3324
7.Despesas pessoais;0,65;1,39;5,91;10,2891;0,0669Seis CSVs em relatorio/dados/, todos no mesmo mês de referência. Duas conferências de consistência: o variacao_mes do Índice geral em ipca_grupos.csv é igual ao último valor de dados/ipca_historico.csv (mesma inflação, duas fontes), e a soma das contribuições dos 9 grupos chega perto do índice geral.
9.2 relatorio-ipca.qmd: os visuais leem os CSVs e incluem os textos
Agora o outro lado da separação: o .qmd mantém os mesmos gráficos e tabelas de antes (plotnine e great_tables), mas em vez de calcular, passa a ler os CSVs — e, entre uma figura e outra, incluir os arquivos de textos/ com o shortcode {{< include >}} do Quarto. É esse mecanismo que deixa os agentes reescreverem a análise sem tocar em uma linha do código de visualização.
Prompt:
Reescreva meu relatorio/relatorio-ipca.qmd para SÓ apresentar (theme cosmo,
embed-resources, echo: false, engine jupyter): em vez de calcular, ele lê
os CSVs de relatorio/dados/ e mantém os mesmos gráficos (plotnine) e tabelas
(great_tables) que eu já tinha.
Seções, cada uma com seu visual seguido de um include de texto:
1. Síntese do mês — tabela IPCA vs Focus (lendo ../dados/surpresa.csv) e
tabela de variações acumuladas; inclui ../textos/sintese.md
2. Inflação cheia — gráfico IPCA 12m + MM3M SAAR + meta com faixa;
inclui ../textos/cheio.md
3. Núcleos — gráfico da média dos núcleos; inclui ../textos/nucleos.md
4. Padrão sazonal — gráfico do ano vs mediana histórica e quartis;
inclui ../textos/sazonalidade.md
5. Grupos — tabela por grupo e barras empilhadas de contribuição;
inclui ../textos/grupos.md
Detalhes: mantenha a paleta de cores do relatório; rótulos de data em pt-BR
(o %b do strftime sai em inglês — use uma função própria); rótulo do último
ponto nos gráficos de linha; números nas tabelas com vírgula decimal.
Crie também os 5 arquivos de textos/ com um placeholder em itálico
("Texto pendente — rode /gerar-relatorio...").O que o Claude vai gerar. O esqueleto de cada seção fica assim — visual determinístico em cima, texto dinâmico embaixo:
## Síntese do mês
{{< include ../textos/sintese.md >}}
```{python}
#| label: tbl-surpresa
# tabela IPCA vs Focus, lida de ../dados/surpresa.csv
```Rode quarto render relatorio/relatorio-ipca.qmd e abra o HTML: os quatro gráficos e as três tabelas aparecem com os dados do mês, e no lugar das análises você lê os placeholders em itálico. O relatório já é publicável — só ainda não diz nada.
Se o render terminar com os error 32 (“arquivo já está sendo usado”), é o Dropbox/OneDrive segurando a pasta _files/ durante o cleanup. O HTML já foi escrito; feche o visualizador e re-renderize se precisar. Não é erro do seu código.
O HTML mostra os visuais com os números do mês de referência e os cinco placeholders em itálico nos lugares certos. Guarde essa imagem mental: a diferença entre este HTML e o final é exatamente o que o time de agentes vai produzir.
10 Passo 4 — Quatro coletores de evidência
Com o “quanto” calculado, começa o “porquê” — e a primeira etapa é juntar evidência. São quatro fontes, e cada uma fica com um especialista que tem só as ferramentas mínimas de que precisa e grava o resultado num arquivo de saída próprio em evidencias/:
leitor-relatoriolê os CSVs de métricas e extrai os sinais do mês: 12 meses contra a meta, SAAR contra 12 meses (acelerando ou não), núcleos, posição no padrão sazonal, maiores contribuições e a trajetória das últimas surpresas. SóReadeWrite— evidência interna.leitor-releasebusca a divulgação do IPCA na API de notícias do IBGE e baixa o caderno em PDF do FTP para extrair o que o próprio IBGE destacou.reporter-noticiasvarre o noticiário do mês comWebSearche devolve manchetes com veículo e data — o que a imprensa apontou como causa.leitor-ataconsulta a API de atas do Copom e lê as três reuniões mais recentes (anteriores à divulgação do mês), resumindo a trajetória do que o comitê disse sobre os vetores de inflação, com citações literais.
Prompt:
Crie quatro subagentes em .claude/agents/, todos com model: sonnet e
corpo curto terminando numa linha de "Limites:":
1. leitor-relatorio (tools: Read, Write) — lê relatorio/dados/*.csv e
dados/surpresa.csv e extrai os sinais do mês: IPCA 12m vs meta e
limites; MM3M SAAR vs 12m (acelera ou desacelera na margem?); média
dos núcleos; mês vs mediana histórica e intervalo q25-q75 do padrão
sazonal; 3 maiores contribuições por grupo; e a trajetória da surpresa
(surpresa.csv tem 12 meses — é pontual ou sequência?). Saída:
evidencias/relatorio_ipca.md, máx 16 linhas, cada sinal com o número
e o arquivo de origem. Não recalcula nada, não opina.
2. leitor-release (tools: WebFetch, Bash, Read, Write) — acha o release
do IPCA do mês em
https://servicodados.ibge.gov.br/api/v3/noticias/?qtd=10&busca=IPCA
(ignorando IPCA-15 e INPC), baixa o caderno
ipca-inpc_AAAAMMcaderno.pdf do FTP do IBGE com curl para dados/brutos/
e lê com Read. Saída: evidencias/release_ibge.md. NUNCA acessar
agenciadenoticias.ibge.gov.br (bloqueado para robôs). Se uma fonte
falhar, registra e segue com a outra.
3. reporter-noticias (tools: WebSearch, WebFetch, Write) — 3 a 5
manchetes do mês sobre IPCA/inflação, cada uma com veículo, data e uma
linha de contexto; descarta notícia sem data ou fora do mês. Saída:
evidencias/noticias.md. Só reporta, não conclui.
4. leitor-ata (tools: Bash, Read, Write) — consulta
https://www.bcb.gov.br/api/servico/sitebcb/atascopom/ultimas?quantidade=6&filtro=
(o filtro= vazio é obrigatório, sem ele HTTP 500), seleciona as 3 atas
mais recentes anteriores à divulgação do mês, baixa cada PDF (bcb.gov.br
+ campo Url) para dados/brutos/ e lê com Read. Saída:
evidencias/ata_copom.md, uma seção por ata (da mais recente à mais
antiga) com citações literais, e ao fim como o discurso evoluiu.
Declare se a reunião mais recente foi antes ou depois da divulgação do
IPCA do mês. Não projeta juros, não opina sobre a surpresa.A coerência temporal do leitor-ata evita um erro de leitura fácil de cometer. A reunião do Copom pode ser anterior à divulgação do IPCA do mês — nesse caso o comitê ainda não viu o número que surpreendeu, e a ata é leitura prévia, não reação. O agente declara isso no topo, e o investigador respeita.
O que o Claude vai gerar. Quatro arquivos no formato da anatomia do início da aula. O leitor-ata inteiro, para calibrar o tamanho:
---
name: leitor-ata
description: Baixa a ata mais recente do Copom e resume o que o comitê disse sobre inflação
tools: Bash, Read, Write
model: sonnet
---
1. Bash: curl "https://www.bcb.gov.br/api/servico/sitebcb/atascopom/ultimas?quantidade=1&filtro="
O filtro= vazio é obrigatório — sem ele a API devolve HTTP 500.
2. Baixe o PDF (https://www.bcb.gov.br + campo Url do JSON) com curl
para dados/brutos/ e leia com Read.
3. Extraia o que o comitê disse sobre os vetores de inflação:
alimentos, administrados, câmbio e repasse, núcleos, expectativas.
Saída: evidencias/ata_copom.md — número e data da reunião no topo,
8 a 12 linhas, citações literais entre aspas.
API fora do ar → registre o erro no arquivo e encerre.
Limites: não projeta juros, não opina sobre a surpresa do IPCA.Repare nos tools: o leitor-ata não tem WebFetch (o WebFetch não interpreta PDF — o caminho é curl + Read, que lê PDF nativamente), e nenhum coletor tem Edit, porque é o cabeçalho que restringe cada subagente às ferramentas de que ele realmente precisa.
10.1 O primeiro fan-out
Hora de ver as quatro Tasks subirem juntas. Peça os quatro de uma vez:
Prompt:
Use os quatro coletores em paralelo para o mês 2026-03: leitor-relatorio,
leitor-release, reporter-noticias e leitor-ata. Depois me mostre um resumo
do que cada um encontrou.No terminal, você vê o agente principal disparar quatro Tasks numa única mensagem — os badges dos quatro subagentes aparecem juntos e progridem ao mesmo tempo, cada um na sua conversa. Minutos depois, evidencias/ tem quatro arquivos. O leitor-ata, em particular, mostra o valor de ler três reuniões em vez de uma: ele reconstrói a trajetória do discurso do comitê e cuida da coerência temporal — a ata mais recente que ele pode usar é anterior à divulgação do número:
## Coerência temporal — aviso obrigatório
A ata mais recente utilizada é a 277ª Reunião (17-18 de março de 2026).
O IPCA de março/2026 foi divulgado em torno do dia 10 de abril de 2026.
A reunião de 17-18/março ocorreu ANTES da divulgação do IPCA de março/2026.
Portanto, esta ata é leitura prévia do comitê — ela não comenta nem reage
ao número de março que mais tarde surpreendeu o mercado.
## Evolução do discurso entre as três atas
Janeiro/2026 → Março/2026: o choque geopolítico no Oriente Médio interrompeu
a trajetória benigna. As expectativas subiram (Focus 2026 de 4,0% para 4,1%),
a projeção de IPCA administrados saltou de 3,0% para 4,3%, e o câmbio passou
de vetor de alívio a fonte explícita de risco.E o leitor-relatorio, que só olhou para dentro — os CSVs calculados no Passo 3 —, devolveu os sinais que ancoram a investigação, incluindo a trajetória das surpresas:
## 2. MM3M SAAR vs 12m — inflação na margem [ipca_12m_meta.csv]
- IPCA MM3M SAAR: 6,082% vs IPCA 12m: 4,143%
- Margem muito acima do acumulado 12m: inflação na margem acelera
## 4. Comparação com padrão sazonal de março [padrao_sazonal.csv]
- IPCA realizado em março/2026: 0,88% | q25: 0,31% | Mediana: 0,48% | q75: 0,77%
- Resultado: ACIMA do q75 — fora do intervalo interquartil histórico
## 5. Três maiores contribuições por grupo [ipca_grupos.csv]
1. Transportes: variação +1,64%, peso 20,45 — contribuição 0,3354 p.p.
2. Alimentação e bebidas: variação +1,56%, peso 21,31 — contribuição 0,3324 p.p.
3. Despesas pessoais: variação +0,65%, peso 10,29 — contribuição 0,0669 p.p.
## 6. Trajetória da surpresa [surpresa.csv]
- Fevereiro +0,20 p.p., março +0,28 p.p.: duas surpresas altistas em sequência,
depois de meses de surpresas negativas ou nulasQuatro arquivos em evidencias/, cada um assinado pela fonte certa, e nenhum deles opina — coletor que conclui está invadindo o trabalho do investigador. Se os quatro rodaram em fila (um badge por vez), o pedido não deixou claro o paralelismo: repita pedindo “em paralelo, numa única mensagem”.
11 Passo 5 — O investigador: um arquivo, várias instâncias
A etapa seguinte testa hipóteses: alimentação explica o número do mês? E o câmbio? E os administrados? A tentação é criar investigador-alimentos.md, investigador-cambio.md, investigador-administrados.md — três arquivos quase idênticos, três lugares para manter a mesma instrução.
Não faça isso. Crie um investigador.md genérico e deixe a hipótese viajar no prompt de cada invocação. O agente principal pode invocar o mesmo subagente várias vezes em paralelo, cada instância com a sua tarefa — exatamente como uma função recebe argumentos em vez de você copiar a função três vezes.
Prompt:
Crie .claude/agents/investigador.md (tools: Read, Write; model: sonnet).
Ele recebe NO PROMPT: uma hipótese para a surpresa do IPCA, o valor e o
sinal da surpresa, e o mês. Lê dados/surpresa.csv, relatorio/dados/*.csv
e evidencias/*.md e avalia só a SUA hipótese: o que a sustenta, o que a
enfraquece. Todo número citado deve existir nos CSVs; toda citação, em
evidencias/. Use o histórico a favor: surpresa.csv tem 12 meses (a
surpresa é repetição de um padrão ou ruptura?) e ata_copom.md traz 3
reuniões (o comitê já sinalizava esse vetor?). Respeite a linha do tempo:
se a ata é anterior à divulgação do IPCA, ela é leitura prévia, não reação
ao número. Saída: investigacoes/<slug-da-hipotese>.md com veredito
(sustentada / parcialmente sustentada / não sustentada), confiança
(alta/média/baixa) e 2 a 4 evidências decisivas com a fonte. Se a
evidência for insuficiente, dizer isso — nunca completar com suposição.
Limites: não investiga hipótese de colega, não escreve os textos do
relatório.Antes de paralelizar, teste com uma hipótese só: roda a versão mínima, observa o que saiu e só então confia no fan-out.
Prompt:
Use o investigador com a hipótese "Transportes foi o vetor que mais
surpreendeu em março, puxado por combustíveis e passagens, e o mercado
subestimou esse repasse". A surpresa foi de +0,28 p.p. (realizado 0,88%,
mediana Focus 0,60%), mês 2026-03.O que o Claude vai gerar. Um veredito com cada evidência rastreada à fonte — inclusive as evidências contra, que um analista de verdade não esconde. E veja como ele usa o histórico e a coerência temporal das atas a favor da análise. Trechos da investigação real desta aula:
# H1 — Choque de combustíveis em Transportes
**Veredito:** sustentada · **Confiança:** alta
### 1. Transportes respondeu por 0,3354 p.p. do IPCA — sozinho supera a surpresa total
O grupo variou 1,64% em março e contribuiu 0,3354 p.p. (peso 20,45%;
ipca_grupos.csv). A surpresa total foi +0,28 p.p. (surpresa.csv) — a
contribuição de Transportes excede sozinha a surpresa: se ele tivesse vindo
conforme o Focus esperava, a surpresa seria nula ou negativa.
### 3. A 277ª reunião do Copom é leitura prévia — não reação ao dado
A 277ª (17-18/03) é anterior à divulgação de março (~10/04), então a ata não
comenta o resultado. Ainda assim, o Copom já registrava o choque do Oriente
Médio e a projeção de administrados saltando de 3,0% para 4,3% — o vetor
estava ativo no mês de referência. (evidencias/ata_copom.md)
## O que enfraquece
- Alimentação contribuiu 0,3324 p.p., quase igual a Transportes: a surpresa
teve dois vetores, não um. H1 explica por que o Focus errou, mas não toda
a extensão do erro. (ipca_grupos.csv)
- A surpresa de março (+0,28) é a maior dos 12 meses da série, e o Focus
vinha calibrado — compatível com choque exógeno não precificado. (surpresa.csv)Compare com o que o mesmo fluxo produziria num mês morno: aqui a hipótese fecha em “sustentada, confiança alta” porque os dados, as notícias e a ata convergem; num mês sem surpresa, a conclusão seria “não sustentada”. É essa diferença de conclusão, que depende de pesar e relacionar as evidências, que um script não consegue produzir.
O arquivo em investigacoes/ tem veredito, confiança e evidências com a fonte nomeada (arquivo de origem). Confira uma por uma: cada número citado existe mesmo nos CSVs? É a checagem que o checador fará em escala no Passo 6 — fazê-la à mão uma vez ensina o que ele precisa pegar.
12 Passo 6 — O redator e o checador
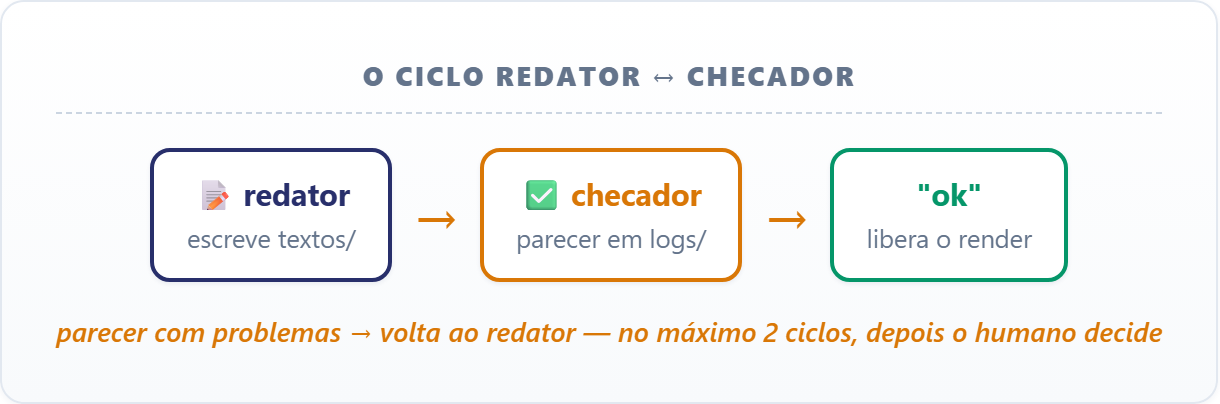
Faltam os dois últimos papéis: quem escreve os cinco textos do relatório e quem confere antes de publicar. A separação é deliberada — quem escreve não confere, quem confere não escreve. O redator produz textos/; o checador devolve um parecer em logs/checagem.md que ou libera o render (“ok”) ou lista correções.
Prompt:
Crie dois subagentes (model: sonnet):
1. redator (tools: Read, Write) — lê dados/surpresa.csv,
relatorio/dados/*.csv, evidencias/*.md e investigacoes/*.md e escreve
os 5 textos do relatório, cada um com o mês em itálico na primeira
linha: textos/sintese.md (o número do mês, a surpresa vs Focus e a
explicação principal em 1 parágrafo), textos/cheio.md (12m vs meta e
o que a SAAR diz da margem), textos/nucleos.md, textos/sazonalidade.md
(mês vs mediana histórica e q25-q75), textos/grupos.md (contribuições
+ vereditos das investigações em ordem de confiança). Todo número vem
dos CSVs, em formato pt-BR (0,88%). Toda citação vem de evidencias/.
Períodos de 20 a 30 palavras com conectivos; evitar os vícios do
CLAUDE.md. Se receber correções do checador, corrige só o apontado.
2. checador (tools: Read, Write) — confere nos 5 textos: cada número
existe em dados/surpresa.csv ou relatorio/dados/*.csv (comparar o
VALOR, não a string — vírgula no texto, ponto no CSV, tolerância de
arredondamento a 2 casas); cada citação existe em evidencias/;
coerência de sinal (surpresa para cima ⇔ realizado > mediana,
"acelera" ⇔ SAAR > 12m); vereditos batem com investigacoes/; mês
certo na primeira linha; vícios de estilo. Parecer em
logs/checagem.md: "ok" na primeira linha OU lista numerada (arquivo +
trecho + problema + correção). Regra inegociável: número sem fonte
nos CSVs impede o "ok". Não edita os textos — só aponta.O que o Claude vai gerar. Dois arquivos curtos; o detalhe que faz diferença está nas linhas finais do checador:
Regra inegociável: número sem fonte nos CSVs impede o "ok".
Limites: não edita os textos — só aponta.12.1 O ciclo de correção tem teto
Redator e checador formam um ciclo: parecer com problemas volta para o redator, que corrige só o apontado, e o checador confere de novo. Esse ciclo precisa de um teto — dois turnos — porque dois agentes podem discordar para sempre, e pipeline que não termina é pior que pipeline que falha. Quem impõe o teto é o comando do próximo passo: na terceira divergência, ele para e mostra os problemas para você decidir.
Os dois arquivos existem e os papéis não vazam: o redator não tem instrução de conferir, o checador não tem permissão de corrigir. Se quiser ver o ciclo funcionando antes do comando, invoque o redator e depois o checador manualmente e leia logs/checagem.md.
13 Passo 7 — /gerar-relatorio: o pipeline num comando
Cada peça funciona, mas ainda falta o que junta tudo numa única execução. Um comando em .claude/commands/ cuida dessa orquestração: ele encadeia os scripts, o fan-out, as hipóteses, a redação, a checagem e o render numa linha que você (ou um agendador) digita uma vez por mês.
Prompt:
Crie .claude/commands/gerar-relatorio.md, um comando que coordena o time
para gerar o relatório IPCA do mês $ARGUMENTS (AAAA-MM; vazio = último
disponível). Passos numerados:
1. python src/surpresa.py $ARGUMENTS — conferir dados/surpresa.csv;
falhou → parar.
2. python src/preparar_dados.py — conferir os 6 CSVs no mesmo mês;
falhou → parar.
3. Invocar EM PARALELO, numa única mensagem, os quatro coletores,
passando o mês. Conferir os 4 arquivos em evidencias/.
4. Ler ipca_grupos.csv e as evidências e formular 3 hipóteses para a
surpresa (priorizar grupos de maior |contribuição| e o que
release/notícias/ata destacam).
5. Invocar o investigador EM PARALELO, uma instância por hipótese.
6. Invocar o redator → conferir os 5 textos com o mês certo.
7. Invocar o checador → ler logs/checagem.md. "ok" → seguir; senão
devolver a lista ao redator e checar de novo (máx 2 ciclos;
persistindo, parar e mostrar os problemas).
8. quarto render relatorio/relatorio-ipca.qmd e copiar o HTML para
output/relatorio-ipca-AAAA-MM.html (nunca sobrescrever mês anterior).
"os error 32" no cleanup é o Dropbox — o HTML foi gerado, seguir.
9. Mostrar: a surpresa em p.p., os vereditos com confiança e o caminho
do HTML.
Parar em qualquer falha de script. Nunca renderizar sem "ok" do checador.A execução inteira, do dado bruto ao HTML:

Digite /gerar-relatorio 2026-03 e acompanhe o terminal. Primeiro os dois scripts imprimem seus resumos e os quatro badges dos coletores sobem juntos. Em seguida rodam três instâncias do investigador, depois o redator e o checador, e por fim o render. A execução desta aula levou alguns minutos, e a maior parte do tempo ficou nos coletores, que baixam e leem PDFs.
logs/checagem.md começa com “ok”, output/ tem o HTML datado e os cinco textos de textos/ trazem o mês de referência em itálico na primeira linha. Se o checador reprovou duas vezes, o comando parou e mostrou a lista — leia os apontamentos antes de rodar de novo: quase sempre é número sem fonte.
14 O relatório que saiu da máquina
No HTML final, as partes calculadas pelos scripts aparecem lado a lado com o que os agentes escreveram: o gráfico da inflação cheia com a faixa da meta vem seguido da leitura do mês, e a tabela de grupos vem ao lado da conclusão de quem investigou aquele número. A síntese que abriu o relatório desta execução, escrita pelo redator e aprovada pelo checador, foi esta:
*Março de 2026*
O IPCA de março de 2026 ficou em 0,88%, superando a mediana Focus de 0,60%
em +0,28 p.p. — a maior surpresa altista dos 12 meses da série, que registra
outras três surpresas positivas antes de março: junho/2025 (+0,01 p.p.),
agosto/2025 (+0,04 p.p.) e fevereiro/2026 (+0,20 p.p.), com os oito meses
restantes apresentando desvios negativos ou nulos. Fevereiro e março formam
as duas únicas surpresas altistas consecutivas e crescentes do período, o
que configura aceleração da surpresa. O vetor central foi o combustível: a
alta do diesel em 13,90% — associada aos desdobramentos do conflito no
Oriente Médio, conforme o Portal CNA Brasil (16/abr/2026) — encareceu o
frete e pressionou tanto o grupo Transportes quanto os alimentos no
domicílio, criando um canal de transmissão que o mercado não havia
precificado na mediana de 0,60%.Cada número desse texto tem endereço: o 0,88% e o 0,60% estão em dados/surpresa.csv; a sequência fevereiro→março sai das 12 linhas do mesmo arquivo; o diesel de 13,90% vem de evidencias/. O parecer do checador registra a conferência, valor a valor. Um trecho de logs/checagem.md:
ok
## Regra 1 — Números nos CSVs
- IPCA 0,88% e mediana Focus 0,60% → surpresa.csv (linha 2026-03): ok
- Sequência jun/25 +0,01, ago/25 +0,04, fev/26 +0,20 → surpresa.csv: ok
- Transportes 0,3354 p.p. e Alimentação 0,3324 p.p. → ipca_grupos.csv: ok
## Regra 3 — Coerência de sinal
- Surpresa +0,28 p.p.: realizado (0,88) > mediana (0,60) → surpresa para
cima; texto afirma "superando a mediana Focus". ok.
- Cheio: MM3M SAAR (6,08%) > acumulado 12m (4,14%) → "acelera na margem". ok.O ciclo de correção trabalhou nesta execução, e foi por isso que o relatório saiu confiável: a primeira rodada do redator contou errado as surpresas altistas anteriores e citou um valor de SAAR que não batia com o CSV. O checador pegou as duas falhas, devolveu “não ok” com a lista, e o redator corrigiu na segunda rodada — que então saiu “ok”. É o teto de dois ciclos fazendo exatamente o que promete: barrar número errado antes de virar relatório publicado.
Essa rastreabilidade é o que separa um relatório gerado por IA de um relatório defensável gerado por IA. Se um leitor duvidar de qualquer afirmação, o caminho da evidência está escrito: texto → investigação → evidência → CSV → API oficial. O modelo escreveu, mas não inventou — porque o pipeline não deixou.
No mês que vem, quando o IBGE divulgar o próximo IPCA, o relatório inteiro se refaz com /gerar-relatorio, gerando novos dados, novos gráficos, nova investigação e novos textos. O que não muda é a estrutura: o script continua calculando os números, enquanto o time de subagentes continua investigando as causas por trás deles.
O que levar desta aula
- Script ou agente: decida pelas três perguntas. Determinístico, verificável por igualdade, fonte estruturada → script. Julgamento sobre evidência dispersa → agente. Número de LLM exige conferência; número de script, não — delegue cálculo a agente e você paga a geração e a auditoria.
- Subagente é um arquivo de quatro campos + limites.
name,description(o gatilho),tools(o cinto de segurança) emodel; o corpo termina dizendo o que o agente não faz. - Um especialista, N instâncias. Tarefas paralelas da mesma natureza não pedem N arquivos — pedem um subagente genérico e a variação no prompt de cada invocação.
- Paralelo seguro = tarefas independentes + um arquivo de saída para cada. E quem junta os resultados é sempre o agente principal: subagentes não conversam entre si.
- Todo ciclo entre agentes precisa de teto. Redator e checador podem divergir para sempre; o comando corta em dois ciclos e devolve a decisão ao humano. Quem escreve não confere, quem confere não escreve — e ninguém publica sem o “ok”.

