A despeito da forte queda na taxa básica de juros, a Selic, o juro para a pessoa física ainda permanece em níveis elevados. Para ilustrar, vamos pegar os dados diretamente do Banco Central com o código de R a seguir.
library(BETS)
library(ggplot2)
library(scales)
selic = BETSget(4189, from='2011-03-01', to='2019-12-01')
jurospf = BETSget(20740)
time = seq(as.Date('2011-03-01'), as.Date('2019-12-01'), by='1 month')
data = data.frame(time=time, selic=selic, jurospf=jurospf)
De posse dos dados, podemos construir o gráfico abaixo.
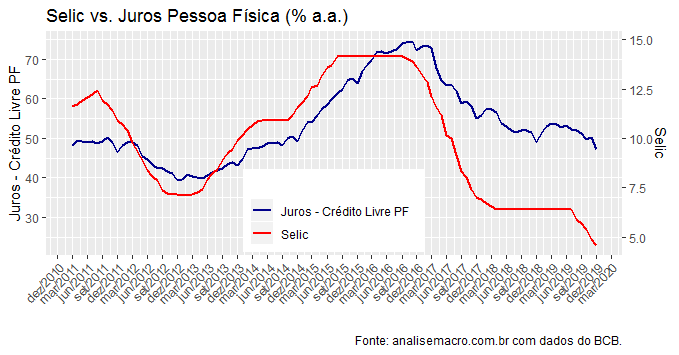
Como se vê, a despeito de estarem correlacionados ao longo do tempo, a diferença de nível é gritante. Enquanto a taxa básica de juros está em 4,25%, o juro médio para pessoa física permanece próximo a 50% a.a. Essa diferença leva em conta uma série de fatores, resumidos no que chamamos de spread bancário - a diferença entre o custo de captação e o de empréstimo. Existem vários fatores que explicam o spread, como, por exemplo, a inadimplência - ver a edição 60 do Clube do Código.
Nesse contexto, como já discuti nesse e em outros espaços, o juro para o tomador final tem tanto um componente macro quanto microeconômico. No primeiro, ele depende fortemente da taxa básica de juros, que é afetada por condições macroeconômicas de equilíbrio, como a situação fiscal do setor público.
A parte macro do problema avançou bastante nos últimos anos. Em particular, a aprovação do teto de gastos e a reforma da previdência tiveram impacto expressivo sobre o chamado juro de equilíbrio da economia brasileira.
O grosso do problema, contudo, ainda reside sobre o lado microeconômico. Em particular, o risco de crédito é um fator preponderante para explicar o nível ainda elevado do juro a pessoa física no Brasil. Ainda é muito difícil recuperar crédito no país, uma vez que ocorre inadimplência.
Para ilustrar, fizemos um exercício no Clube do Código que busca justamente dar luz a esses problemas - é a edição 50 do Clube. O modelo estimado é dado pela equação
(1) 
Em que:
 : Taxa média de juros - recursos livres - pessoa física - total (SGS/BCB: 20740)
: Taxa média de juros - recursos livres - pessoa física - total (SGS/BCB: 20740)
 : Foram testadas as taxas Selic e Swap pré-DI 30, 60, 90, 120, 180 e 360. Por fim, utilizou-se a taxa Swap pré-DI 90 (SGS/BCB: 7818)
: Foram testadas as taxas Selic e Swap pré-DI 30, 60, 90, 120, 180 e 360. Por fim, utilizou-se a taxa Swap pré-DI 90 (SGS/BCB: 7818)
 : Inadimplência - pessoa física - total (SGS/BCB: 21112)
: Inadimplência - pessoa física - total (SGS/BCB: 21112)
 : Foram testados a medida de risco-país (Embi) e o índice de incerteza da economia da FGV. O modelo final considerou este último.
: Foram testados a medida de risco-país (Embi) e o índice de incerteza da economia da FGV. O modelo final considerou este último.
 : dummies trimestrais.
: dummies trimestrais.
 : indicam defasagens utilizadas.
: indicam defasagens utilizadas.
Em conjunto, os resultados parecem corroborar a ideia de que a inadimplência é um fator relevante para explicar a taxa de juros ao tomador. Por outro lado, a incerteza apresenta significância estatística e, portanto, contribui para aumentar os juros ao tomador. Isto parece estar em linha com a ideia de uma postura mais conservadora dos bancos.
Mudar essa realidade, por fim, exige um ataque microeconômico de difícil operação. Passa não só por redução da assimetria entre oferta e demanda por crédito, como também maior celeridade no julgamento de processos de resgate de crédito. Esse último é a ponta mais difícil do processo.
(**) Aprenda a analisar dados em nossos Cursos Aplicados de R.
___________________

