Como tenho comentado nas últimas semanas, estamos tendo acesso aos primeiros dados de março que trazem os efeitos da pandemia do coronavírus sobre a economia brasileira. Um dos indicadores que tenho acompanhado mais de perto é o consumo diário de energia elétrica. Como comentei também por aqui, publicamos na semana passada a Edição 73 do Clube do Código, que traz uma intensa investigação da relação dessa série com o PIB, tanto em nível quanto em termos de taxa de crescimento.
Nesse Comentário de Conjuntura trago mais alguns detalhes do exercício. O mesmo está disponível no repositório privado do Clube no github, acessível para alunos do plano premium dos nossos Cursos Aplicados de R e para os assinantes do Clube. Para assinar, clique aqui. A seguir, carregamos os pacotes utilizados na investigação.
library(tidyverse) library(scales) library(readxl) library(xts) library(forecast) library(sidrar) library(lubridate) library(zoo) library(gridExtra) library(tstools) library(vars) library(aod) library(dynlm) library(stargazer) ### Pacote Seasonal library(seasonal) Sys.setenv(X13_PATH = "C:/Séries Temporais/R/Pacotes/seas/x13ashtml")
A seguir, nós importamos as séries de energia e do PIB.
## Coleta de dados de energia
energia = read_csv2('energia.csv',
col_types = list(col_date(format='%d/%m/%Y'),
col_double()))
## Coletar dados do PIB
# PIB com ajuste sazonal
pib_sa = get_sidra(api='/t/1621/n1/all/v/all/p/all/c11255/90707/d/v584%202') %>%
mutate(date = as.yearqtr(`Trimestre (Código)`, format='%Y%q')) %>%
dplyr::select(date, Valor) %>%
as_tibble()
# PIB sem ajuste
names = c('date', 'pib_sa', 'pib', 'anual_pib')
pib = get_sidra(api='/t/1620/n1/all/v/all/p/all/c11255/90707/d/v583%202') %>%
mutate(date = as.yearqtr(`Trimestre (Código)`, format='%Y%q')) %>%
mutate(pib_sa = pib_sa$Valor) %>%
mutate(anual_pib = acum_i(Valor, 4)) %>%
dplyr::select(date, pib_sa, Valor, anual_pib) %>%
as_tibble() %>%
`colnames<-`(names)
Os dados de energia e do PIB estão com frequências diferentes, de modo que é preciso torná-las comparáveis. O código a seguir trata disso.
## Trimestralizar dados de Energia consumo_energia = xts(energia$carga, order.by = energia$date) consumo_energia_trimestral = apply.quarterly(consumo_energia, FUN=mean) consumo_energia_trimestral_ts = ts(consumo_energia_trimestral, start=c(2000,01), freq=4) consumo_energia_trimestral_sa = final(seas(consumo_energia_trimestral_ts)) energia_trimestral = tibble(date = as.yearqtr(index(consumo_energia_trimestral_sa), format='%Y%q'), carga=consumo_energia_trimestral_sa) %>% mutate(anual_carga = acum_i(carga,4)) ## Reunir dados data = inner_join(pib, energia_trimestral, by='date') %>% dplyr::select(date, pib_sa, carga, anual_pib, anual_carga) %>% drop_na()
Com os dados comparáveis, nós plotamos o gráfico abaixo.
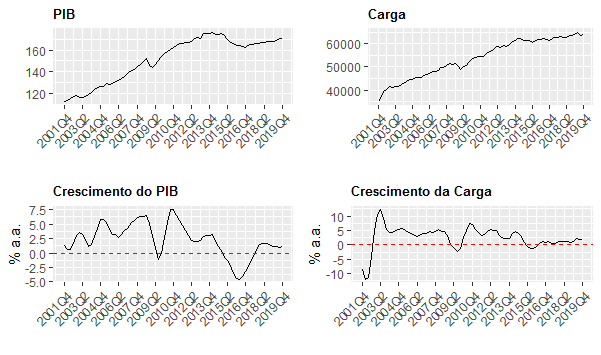
Uma das várias coisas que fazemos na Edição 73 do Clube do Código é estimar um modelo de correção de erros (ECM) entre as séries, uma vez que as mesmas guardam uma relação de longo prazo entre si. O modelo estimado é o seguinte:
(1) 
A tabela a seguir resume o modelo estimado.
| Dependent variable: | |
| d(anual_carga) | |
| stats::lag(resid, -1) | -0.189*** |
| (0.055) | |
| d(anual_pib) | 1.032*** |
| (0.183) | |
| Constant | 0.147 |
| (0.184) | |
| Observations | 72 |
| R2 | 0.403 |
| Adjusted R2 | 0.386 |
| Residual Std. Error | 1.558 (df = 69) |
| F Statistic | 23.273*** (df = 2; 69) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 |
(*) Aprenda a produzir exercícios como esse em nossos Cursos Aplicados de R.
(**) Os códigos estão disponíveis no Clube do Código.

