No mês de dezembro, iremos lançar uma nova versão do Clube do Código. O projeto de compartilhamento de códigos da Análise Macro vai avançar para uma versão 2.0, que incluirá a existência de uma comunidade no Telegram/Whatsapp, de modo a reunir os membros do Novo Clube, compartilhando com eles todos os códigos dos nossos posts feitos aqui no Blog, exercícios de análise de dados de maior fôlego, bem como tirar dúvidas sobre todos os nossos projetos e Cursos Aplicados de R.
Para ilustrar o que vamos compartilhar lá nesse novo ambiente, vou publicar aqui nos próximos dias alguns dos nossos exercícios completos de análise de dados. Esses exercícios fazem parte do repositório atual do Clube, que irá migrar para o novo projeto. Além de todos os exercícios existentes, vamos adicionar novos exercícios e códigos toda semana, mantendo os membros atualizados sobre o que há de mais avançado em análise de dados, econometria, machine learning, forecasting e R.
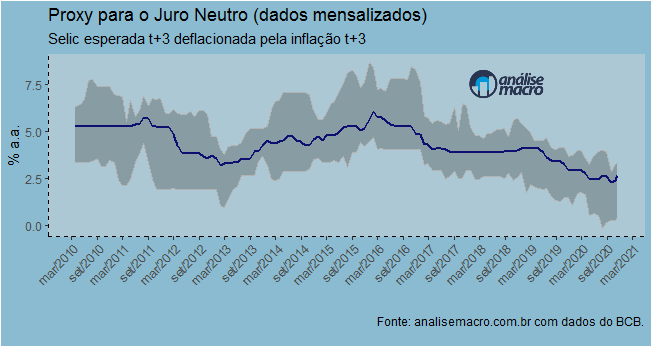
Para ilustrar o que vamos fazer lá no Clube AM, nesse Comentário de Conjuntura vou atualizar um exercício que fizemos para construir uma proxy para o juro neutro da economia brasileira. O exercício foi baseado no Relatório Trimestral de Inflação de dezembro de 2019, onde o pessoal do Banco Central apresentou uma proxy para a taxa neutra de juros considerando as taxas de inflação e de juros três anos à frente disponibilizadas na pesquisa Focus.
A despeito da simplicidade do exercício, existe um trabalho de coleta e tratamento dos dados da pesquisa Focus para se chegar ao juro real três anos à frente, considerado como proxy para o juro neutro da economia. Isso dito, para mostrar como as coisas ficam mais fáceis com o R, eu resolvi replicar o exercício do Banco Central nesse Comentário de Conjuntura.
O script começa carregando alguns pacotes:
library(lubridate) library(magrittr) library(dplyr) library(ggplot2) library(scales) library(ggrepel) library(rbcb) library(xts) library(png) library(grid) library(gridExtra)
Na sequência, nós coletamos a inflação esperada.
ipcae = get_annual_market_expectations('IPCA',
start_date = '2010-03-01')
ipca_esperado = ipcae$median[ipcae$reference_year==year(ipcae$date)+3
&ipcae$base==0]
ipca_esp_min = ipcae$min[ipcae$reference_year==year(ipcae$date)+3
&ipcae$base==0]
ipca_esp_max = ipcae$max[ipcae$reference_year==year(ipcae$date)+3
&ipcae$base==0]
dates = ipcae$date[ipcae$reference_year==year(ipcae$date)+3
&ipcae$base==0]
data = data.frame(dates=dates, min=ipca_esp_min,
ipca=ipca_esperado,
max=ipca_esp_max)
Também coletamos a taxa Selic esperada.
selice = get_annual_market_expectations('Meta para taxa over-selic',
start_date = '2010-03-01')
selic_esperado = selice$median[selice$indic_detail=='Fim do ano'&selice$reference_year==year(selice$date)+3]
selic_esp_min = selice$min[selice$indic_detail=='Fim do ano'&selice$reference_year==year(selice$date)+3]
selic_esp_max = selice$max[selice$indic_detail=='Fim do ano'&selice$reference_year==year(selice$date)+3]
dates = selice$date[selice$indic_detail=='Fim do ano'&selice$reference_year==year(selice$date)+3]
data2 = data.frame(dates=dates, min=selic_esp_min,
selic=selic_esperado,
max=selic_esp_max)
Com as duas séries disponíveis, nós podemos construir nossa proxy para o juro neutro.
ipca_min = xts(ipca_esp_min, order.by = dates) ipca_tmais3 = xts(ipca_esperado, order.by = dates) ipca_max = xts(ipca_esp_max, order.by = dates) selic_min = xts(selic_esp_min, order.by = dates) selic_tmais3 = xts(selic_esperado, order.by = dates) selic_max = xts(selic_esp_max, order.by = dates) neutro_min = (((1+(selic_min/100))/(1+(ipca_min/100)))-1)*100 neutro = (((1+(selic_tmais3/100))/(1+(ipca_tmais3/100)))-1)*100 neutro_max = (((1+(selic_max/100))/(1+(ipca_max/100)))-1)*100 df = data.frame(dates=as.Date(time(neutro)), neutro=neutro, min=neutro_min, max=neutro_max)
Por fim, visualizamos a nossa série.
__________________
(*) Cadastre-se aqui na nossa Lista VIP para receber um super desconto na abertura das Turmas 2021.


