No próximo dia 15/12, darei uma aula ao vivo sobre como criar scripts de R que automatizam a coleta, o tratamento, a modelagem e a apresentação de dados. A aula faz parte do lançamento do Clube AM, um novo espaço aqui na Análise Macro para compartilhar os scripts de R que produzimos aqui no Blog e internamente na Análise Macro. Para se inscrever na aula, clique aqui. O projeto de compartilhamento de códigos da Análise Macro vai avançar para uma versão 2.0, que incluirá a existência de um grupo fechado no Whatsapp, de modo a reunir os membros do Novo Clube, compartilhando com eles todos os códigos dos nossos posts feitos aqui no Blog, exercícios de análise de dados de maior fôlego, bem como tirar dúvidas sobre todos os nossos projetos, exercícios e nossos Cursos e Formações.
Para ilustrar o que vamos compartilhar lá nesse novo ambiente, estou publicando nesse espaço alguns dos nossos exercícios de análise de dados. Esses exercícios fazem parte do repositório atual do Clube do Código, que deixará de existir. Além de todos os exercícios existentes no Clube do Código, vamos adicionar novos exercícios e códigos toda semana, mantendo os membros atualizados sobre o que há de mais avançado em análise de dados, econometria, machine learning, forecasting e R.
Hoje, vou mostrar os resultados de um modelo que fizemos no âmbito do Clube para explicar o spread bancário. Em termos gerais, chamamos de spread bancário a diferença entre as taxas de empréstimo para clientes e captação de recursos que os bancos fazem.
Como variáveis explicativas para o spread bancário, foram utilizadas as provisões dos bancos, compulsórios bancários, taxa de inadimplência, taxa básica de juros e taxa de desemprego. À exceção das provisões, todas as demais variáveis se mostraram estatisticamente significativas para explicar o spread.
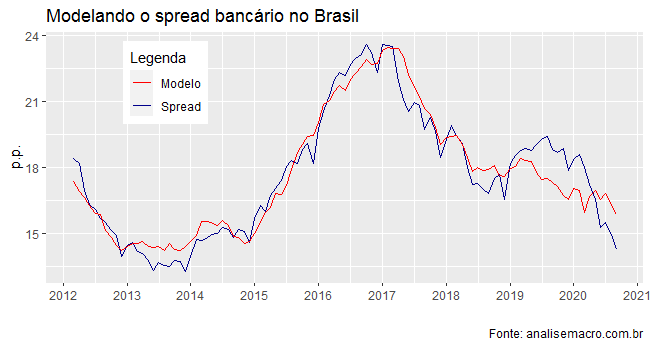
A tabela abaixo resume os resultados encontrados.
| Dependent variable: | |
| spread | |
| provisoes | 0.869 |
| (0.629) | |
| compulsorio | 0.015*** |
| (0.004) | |
| inadimplencia | 1.443*** |
| (0.472) | |
| selic | 0.500*** |
| (0.038) | |
| desemprego | 0.528*** |
| (0.141) | |
| Constant | -8.232*** |
| (1.670) | |
| Observations | 103 |
| R2 | 0.912 |
| Adjusted R2 | 0.907 |
| Residual Std. Error | 0.868 (df = 97) |
| F Statistic | 200.607*** (df = 5; 97) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 |
_______________________


