O `EWZ` é um fundo de investimento que replica um índice de ações brasileiras negociadas em Nova York, chamado `iShares MSCI Brazil Capped`, e tenta acompanhar o Ibovespa no Brasil. O `EWZ` é um `Exchange Traded Funds` (ETF) ou simplesmente *fundo de índices*. Por ser o principal ETF brasileiro, o EWZ é utilizado como uma espécie de termômetro da demanda internacional pelas ações brasileiras. Nesse exercício do Clube AM, vamos verificar se existe uma relação estatística entre o `EWZ` e o `Ibovespa`.
Usaremos os seguintes pacotes de R nesse exercício.
library(tidyverse) library(quantmod) library(timetk) library(scales) library(tidyquant) library(BatchGetSymbols) library(ggcorrplot) library(vars) library(aod)
Para começar, coletamos os dados diretamente do *yahoo finance*:
symbols = c('EWZ', '^BVSP')
prices = BatchGetSymbols(symbols,
first.date = '2016-01-02',
last.date = '2021-02-22') %>%
reduce(inner_join) %>%
drop_na()
Na sequência, podemos dar uma olhada nas séries...
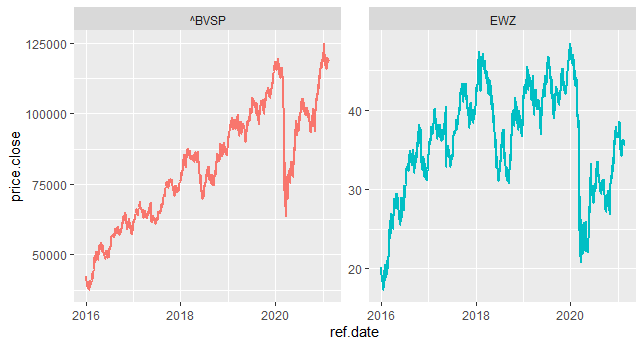
E verificar se existe correlação entre as mesmas...
prices %>%
dplyr::select(ref.date, ticker, price.close) %>%
spread(ticker, price.close) %>%
dplyr::select(-ref.date) %>%
cor(use='na.or.complete') %>%
ggcorrplot(method='square',
colors = c("#e3120b", "white", '#91b8bd'),
lab=TRUE, lab_size = 7)
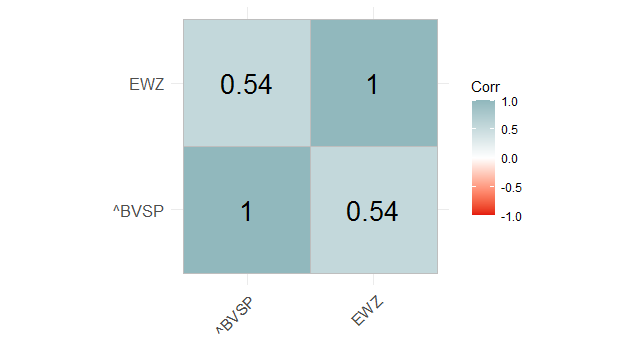
A seguir, colocamos um gráfico de correlação como abaixo.
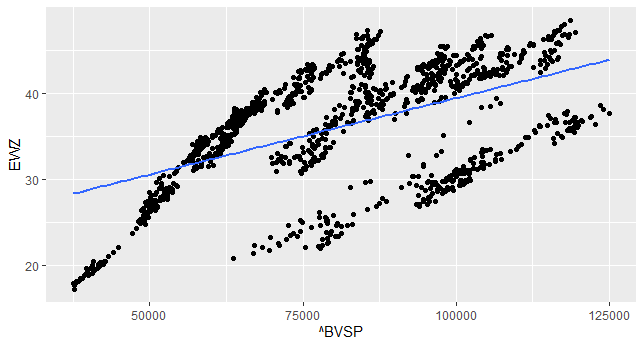
A análise acima parece indicar uma correlação positiva entre as séries, o que era esperado, dada a construção do EWZ. Mas será que essa correlação implica em causalidade? Para testar isso, aplicamos o procedimento de Toda e Yamamoto (1995). De fato, conseguimos rejeitar a hipótese nula de não granger causa quando o sentido é do IBOVESPA para o EWZ, o que indica uma causalidade no sentido de Granger nessa direção. Algo que, por óbvio, era esperado.
____________________
(*) Os códigos completos do exercício estão disponíveis no Clube AM.


