E aí pessoal! Para o Dicas de R dessa semana, vamos mostrar como acessar dados macroeconômicos da Zona do Euro, e mostrar uma breve visualização deles conforme fazemos nos nossos cursos com dados brasileiros. Os dados estão disponíveis no Observatório Macroeconômico do CEPREMAP, e são distribuídos em 4 arquivos:
1. O arquivo sw03 contém dados atualizados para a Zona do Euro de uma tabela utilizada para um modelo DSGE em Smets e Wouters (2003)
2. O arquivo financial contém dados financeiros conforme Christiano et al.(2014)
3. O arquivo fiscal contém dados de impostos e do governo conforme Paredes et al. (2014)
4. O arquivo open contém dados sobre o setor externo da Zona do Euro, como demanda externa, taxa de juros externa, preço de petróleo, importações e exportações, etc.
Os arquivos são atualizados com frequência, e o método de coleta deles é explicado no site do CEPREMAP para quem quiser saber mais. O código abaixo baixa os arquivos e os transforma em um único tibble:
library(tidyverse)
sw03 <- read_csv("https://shiny.cepremap.fr/data/EA_SW_rawdata.csv") %>%
filter(period >="1980-01-01")
fiscal <- read_csv("https://shiny.cepremap.fr/data/EA_Fipu_rawdata.csv")
financial <- read_csv("https://shiny.cepremap.fr/data/EA_Finance_rawdata.csv")
open <- read_csv("https://shiny.cepremap.fr/data/EA_Open_rawdata.csv")
agregado <- sw03 %>%
inner_join(fiscal,by="period") %>%
inner_join(financial,by="period") %>%
inner_join(open,by="period") %>%
mutate(employrt = employ/pop)
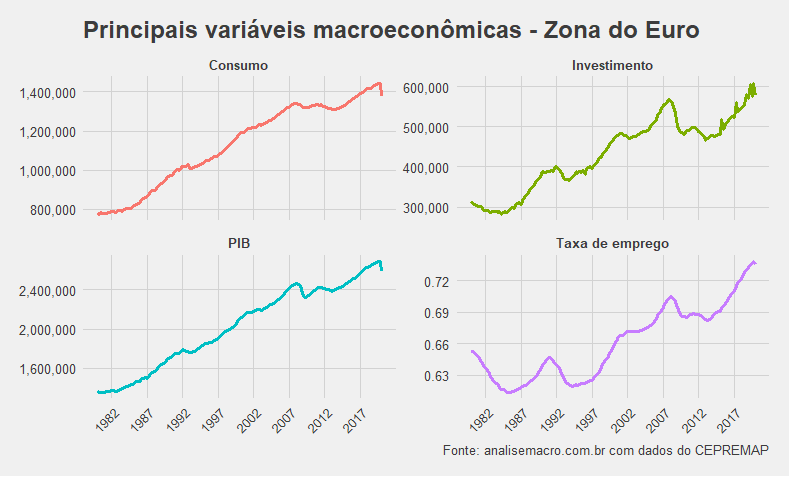
A tabela é extensa, possuindo desde dados mais comuns, como taxas de juros de curto e longo prazo, PIB e consumo, a dados mais interessantes, como impostos e subsídios, contribuição dos trabalhadores, empréstimos para domicílios e instituições não-financeiras, etc.
Vamos utilizar agora o ggplot para visualizar algumas dessas séries. É importante notar que a taxa de emprego utilizada não é sobre a população economicante ativa, e sim sobre a população total, logo não pode ser comparada com dados de outras áreas. Para encontrar a taxa usual, seria preciso acessar os dados desagregados de cada país.
library(ggplot2)
library(ggthemes)
library(scales)
library(ggrepel)
breaks_fun <- function(x) {
if (max(x) > 2000000) {
c(1600000, 2000000, 2400000)
} else if (max(x) > 1400000) {
seq(800000,1500000,200000)
} else if (max(x) > 500000) {
seq(300000, 600000, 100000)
} else {
seq(0.6, 0.75, 0.03)
}
}
agregado %>% rename("Consumo"=conso, "PIB"=gdp, "Investimento"=inves,
"Taxa de emprego" = employrt) %>%
pivot_longer(!period, names_to = "dados", values_to = "value") %>%
filter(dados %in% c("Consumo", "PIB", "Investimento", "Taxa de emprego")) %>%
ggplot(aes(x=period, y = value, colour=dados))+
geom_line(size = 1.1)+
facet_wrap(~dados, scales = 'free_y')+
scale_x_date(breaks = date_breaks("5 years"),
labels = date_format("%Y"))+
scale_y_continuous(breaks = breaks_fun,
labels = function(x) format(x, big.mark = ",", scientific = FALSE),
limits=c(NA, NA))+
theme_fivethirtyeight()+
theme(axis.text.x=element_text(angle=45, hjust=1),
legend.position = 'none',
axis.title.x=element_blank(),
strip.text = element_text(size=10, face='bold'))+
labs(y='',
title='Principais variáveis macroeconômicas - Zona do Euro',
caption='Fonte: analisemacro.com.br com dados do CEPREMAP')
_____________________


