No Dicas de R dessa semana, iremos visualizar o vocabulário de Shakespeare através das palavras mais frequentes entre todas as suas obras. A base de dados utilizada é a bardr, pacote que contém um dataframe com todas as obras, separadas por versos. Inicialmente, vamos limpar os dados e transformá-los em um dataframe que contém cada palavra como uma linha. Esse processo faz repetidas cópias de um dataframe, e, para agilizar o código, utilizaremos a função rbindlist, do pacote data.table, que é consideravelmente mais rápida do que a rbind() do R base ou a bind_rows() do dplyr. Após gerar o dataframe, basta agrupar por palavras, eliminar alguns dados desnecessários, e realizar a contagem.
library(bardr)
library(tidyverse)
library(data.table)
dados <- all_works_df
dados_limpos <- dados %>%
mutate(content = gsub("\032", "'", content))
df_final <- tibble(name = character(), word = character(), genre = character())
teste <- tibble(name = character(), word = character(), genre = character())
substringDF <- function(df){
words <- strsplit(df$content, " ")
aux <- tibble(name = rep(df$name, length(strsplit(df$content, " ")[[1]])),
word = strsplit(df$content, " ")[[1]],
genre = rep(df$genre, length(strsplit(df$content, " ")[[1]])))
df_final <<- rbindlist(list(df_final, aux))
}
for (i in 1:nrow(dados_limpos)) {
substringDF(dados_limpos[i,])
}
palavras <- df_final %>% filter(word!="" & (!str_detect(word, "^[[:upper:][:space:]]+$") |
word=="I")) %>%
mutate(word = tolower(gsub("[[:punct:]]", "", word)))
contagem <- palavras %>% group_by(word) %>% count() %>%
filter(!str_detect(word, "^(0|[1-9][0-9]*)$")) %>% arrange(desc(n))
Temos agora todas as palavras e seu número de aparições. Apesar disso, muitas delas não são relevantes, como "the" e "and", logo precisamos filtrar conectivos e afins. Para isso, iremos utilizar um categorizador de machine learning, treinado para a língua inglesa, com o objetivo de separar as palavras pela sua classe gramatical. O modelo utilizado é fornecido pelo pacote udpipe, e, após baixá-lo e carregá-lo, basta aplicar a função sobre os dados e realizar algumas formatações.
library(udpipe) udmodel <- udpipe_download_model(language = "english") udmodel_eng <- udpipe_load_model( file = "english-ewt-ud-2.5-191206.udpipe") classificador <- as.data.frame(udpipe_annotate(udmodel_eng, contagem$word)) %>% select(token, upos) %>% data.table() contagem <- contagem %>% data.table() setkey(contagem, word) setkey(classificador, token) contagem_classificada <- contagem[classificador] %>% as_tibble() %>% arrange(desc(n))
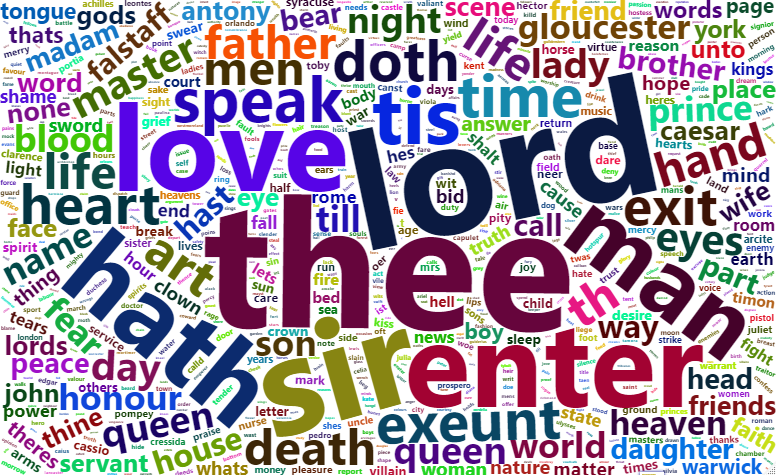
Feito isso, resta pegar os dados de interesse - aqui sendo definidos como adjetivos e substantivos - e visualizá-los com o gráfico gerado pelo pacote wordcloud2. Um gráfico desse tipo apresenta as palavras mais usadas, com tamanho proporcional à frequência delas.
library(wordcloud2)</pre> adjetivos <- contagem_classificada %>% filter(upos == "ADJ") substantivos <- contagem_classificada %>% filter(upos == "NOUN") %>% slice(1:1000) wordcloud2(adjetivos)
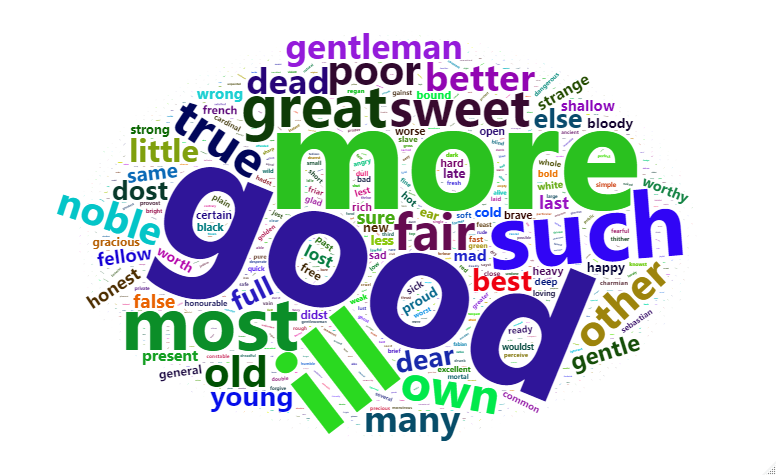
wordcloud2(substantivos)