Tem chamado atenção do mercado o aumento da diferença entre as taxas de juros da NTN-F de 10 anos, com vencimento em 2031 e o Treasury de 10 anos dos Estados Unidos. O aumento do spread entre as taxas têm sido associado ao risco fiscal, expresso na discussão do Orçamento no Congresso. Nesse Comentário de Conjuntura, mostramos como se coleta e se visualiza as taxas diretamente do Tesouro Direto e do FRED St. Louis com o R.
Membros do Clube AM, por suposto, têm acesso a todos os códigos desse exercício.
O início do script que coleta os dados é colocado abaixo. Os dados da NTN-F 10 anos são coletados a partir do pacote GetTDData, enquanto os dados do Treasury de 10 anos são coletados a partir do pacote quantmod. Também coletamos os dados das expectativas fiscais contidas no boletim Focus através do pacote rbcb.
#########################################################
########## NTN-F 10 anos vs. Treasury 10 anos ###########
library(GetTDData)
library(quantmod)
library(timetk)
library(tidyverse)
library(scales)
library(ggcorrplot)
library(vars)
library(aod)
library(rbcb)
### NTN-F 10 anos
download.TD.data("NTN-F")
ntnf31 = read.TD.files(dl.folder = 'TD Files',
maturity = '010131')
### Treasury 10 anos
getSymbols('DGS10', src='FRED')
treasury10 = tk_tbl(`DGS10`, preserve_index = TRUE, rename_index = 'date')
### Expectativas fiscais
fiscal = get_annual_market_expectations('Fiscal',
start_date = '2020-01-01')
fiscal$indic_detail = ifelse(fiscal$indic_detail == "Resultado Primário",
'Resultado Primário', fiscal$indic_detail)
fiscal = fiscal %>%
filter(reference_year == '2021' &
base == 0 & indic_detail %in% c('Resultado Primário', 'Resultado Nominal')) %>%
dplyr::select(date, indic_detail, mean) %>%
spread(indic_detail, mean)
### Data
data = ntnf31 %>%
dplyr::select(ref.date, yield.bid) %>%
rename(date = ref.date, ntnf31 = yield.bid) %>%
mutate(ntnf31 = ntnf31*100) %>%
inner_join(treasury10, by='date') %>%
rename(treasury10 = DGS10) %>%
inner_join(fiscal, by='date') %>%
as_tibble() %>%
drop_na()
Com os dados disponíveis, podemos visualizar a seguir o comportamento das taxas de juros associadas aos títulos do BR e do US, a partir do início do ano.
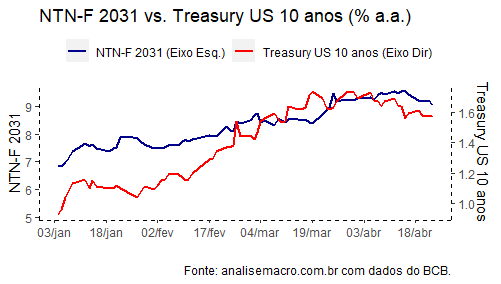
De fato, existe uma correlação positiva forte entre as séries ao longo desse ano, de 0,91. Essa correlação, entretanto, não implica em causalidade. O teste de Wald, seguindo o procedimento de Toda-Yamamoto, não indica causalidade em nenhuma direção, considerando o nível de significância de 5% para a amostra restrita a 2021. Para uma amostra maior, que contém dados desde fevereiro de 2020, o teste sugere que há causalidade em ambas as direções.
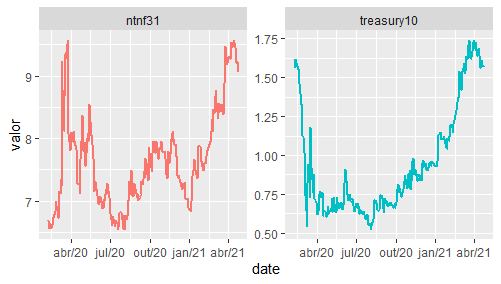
Como se pode observar pelos gráficos acima, tem ocorrido um aumento da taxa de juros associada ao Treasury de 10 anos desde julho do ano passado. A seguir, colocamos o spread entre as taxas de juros de ambos os títulos.
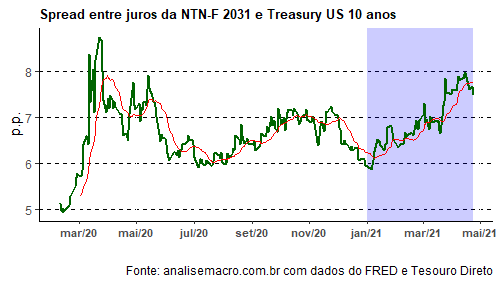
A área hachurada traz o aumento do spread entre as taxas a partir do início de 2021. Abaixo, por suposto, colocamos as expectativas coletadas pelo boletim Focus para as variáveis de fluxo do resultado fiscal esse ano.
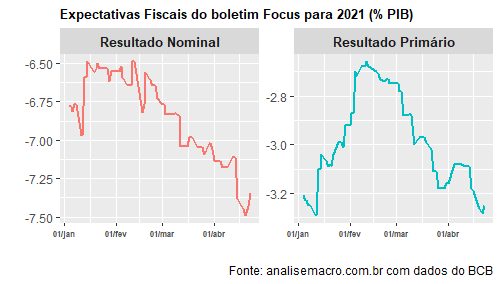
Como se vê, existe uma percepção de recrudescimento do resultado primário e do nominal ao longo de 2021. De fato, encontramos evidências de que existe uma precedência temporal entre o resultado nominal e o spread de taxas de juros BR/US.
_________________________
Membros do Clube AM, por suposto, têm acesso a todos os códigos desse exercício.

