Como já mencionado no comentário de conjuntura desta semana, a crise hídrica tem levado a um aumento do risco de desabastecimento energético no país. Os efeitos econômicos disso podem ser bastante graves, dado que o aumento da tarifa pode fortalecer a alta da inflação. Já uma piora do cenário poderia levar a um racionamento, como em 2001, impactando diretamente na recuperação econômica atual.
Além disso, um impacto menos comentado do aumento do preço da energia é o efeito distributivo. O gasto com energia ocupa muito mais espaço no orçamento das pessoas com renda mais baixa. Assim, aumentos tendem a ser mais danosos a essa parte da população. Podemos ver isso utilizando os dados da Pesquisa de Orçamentos Familiares (POF-17/18) do IBGE.
Para extrair os dados, utilizaremos o pacote {sidrar}. Além do gasto com energia, também selecionamos alguns outros tipos de despesa, para comparação.
library(tidyverse)
library(sidrar)
pof = get_sidra(6715,
period = "all",
variable = 1204,
classific = c("C12190","C339"),
category = list(c(8018,103561,103574,
103585,103618, 103539),
c(47558, 47559,47560,
47561,47562,47563,
47564))) %>%
mutate(`Tipos de despesa` = gsub("[[:punct:]]|[[:digit:]]", "", `Tipos de despesa`)) %>%
rename("classes" = `Classes de rendimento total e variação patrimonial mensal familiar`)
Assim, podemos construir o gráfico com a porcentagem de gastos com eletricidade pelo total de despesas.
ggplot(subset(pof, pof$`Tipos de despesa` == "Energia elétrica"),
mapping = aes(x = factor(classes,
levels=c("Até 1.908 Reais",
"Mais de 1.908 a 2.862 Reais",
"Mais de 2.862 a 5.724 Reais",
"Mais de 5.724 a 9.540 Reais",
"Mais de 9.540 a 14.310 Reais",
"Mais de 14.310 a 23.850 Reais",
"Mais de 23.850 Reais")),
y = Valor,
fill = factor(classes,
levels=c("Até 1.908 Reais",
"Mais de 1.908 a 2.862 Reais",
"Mais de 2.862 a 5.724 Reais",
"Mais de 5.724 a 9.540 Reais",
"Mais de 9.540 a 14.310 Reais",
"Mais de 14.310 a 23.850 Reais",
"Mais de 23.850 Reais")))) +
geom_bar(stat='identity',
position="dodge") +
labs(fill="Faixa de renda") +
theme_minimal() +
scale_fill_brewer(palette = "RdBu") +
ylab("Porcentagem da despesa total") +
geom_text(aes(x = classes, label=Valor), vjust=-0.5, color="black", size=5) +
ggtitle("Despesa com eletricidade por faixa de renda") +
theme(axis.title.x=element_blank(),
axis.text.x=element_blank(),
axis.ticks.x=element_blank())
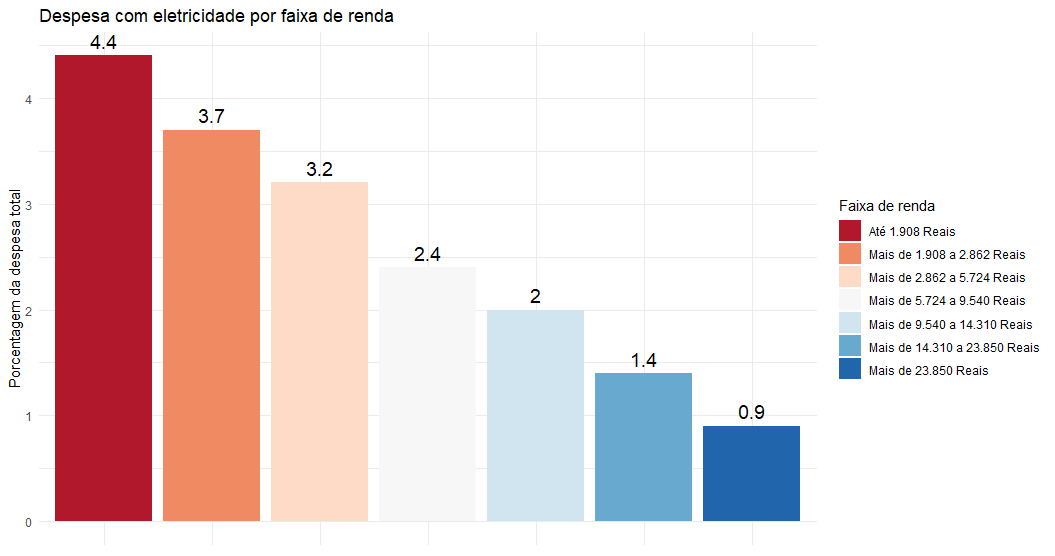
Portanto, para famílias com renda de até 1.908 reais, o gasto com energia elétrica corresponde a 4.4% da despesa total. Já para famílias com mais de 23.850 reais de renda, esse valor corresponde a apenas 0.9%.
Além disso, iremos plotar o mesmo gráfico com os seguintes tipos de despesa: Alimentação, Saúde, Aumento do ativo (investimentos), Educação e Transporte.
ggplot(subset(pof, pof$`Tipos de despesa` != "Energia elétrica"),
mapping = aes(x = `Tipos de despesa`,
y = Valor,
fill = factor(classes,
levels=c("Até 1.908 Reais",
"Mais de 1.908 a 2.862 Reais",
"Mais de 2.862 a 5.724 Reais",
"Mais de 5.724 a 9.540 Reais",
"Mais de 9.540 a 14.310 Reais",
"Mais de 14.310 a 23.850 Reais",
"Mais de 23.850 Reais")))) +
geom_bar(stat='identity',
position="dodge") +
labs(fill="Faixa de renda") +
theme_minimal() +
scale_fill_brewer(palette = "RdBu") +
ylab("Porcentagem da despesa total") +
ggtitle("Despesa com outras categorias por faixa de renda")
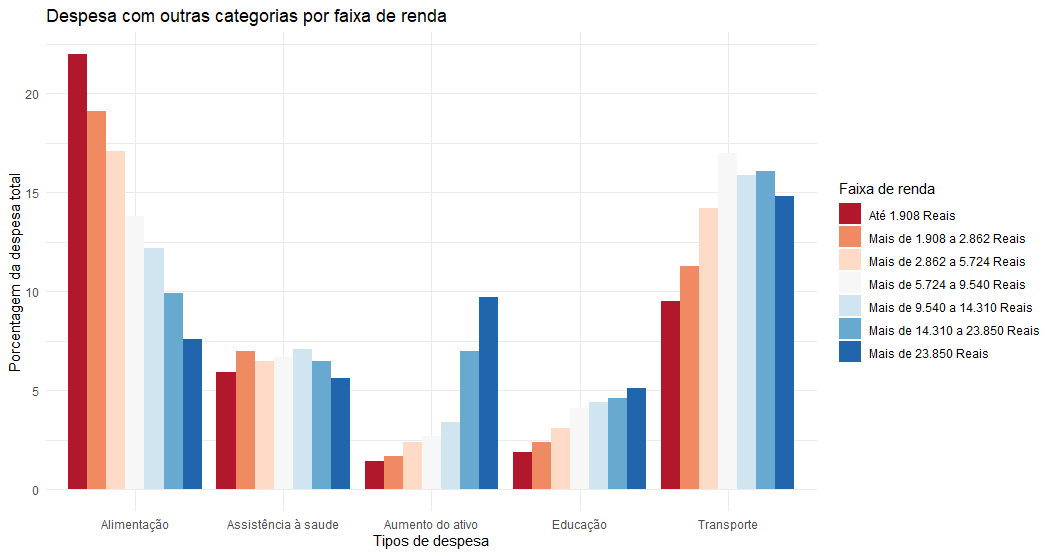
Este gráfico mostra que o mesmo padrão ocorre para os gastos com alimentação. Entretanto, como o esperado, investimentos, educação e transporte apresentam a relação inversa.

