Tem sido noticiado pela imprensa, uma vez mais, o risco de desabastecimento de energia elétrica no país. A causa para isso seria o menor volume de chuvas, que estaria impactando o nível dos reservatórios, utilizados para a geração de energia pelas usinas hidrelétricas. A quantidade de água que chega em uma usina, utilizada para a geração de energia, é chamada de energia natural afluente, ou simplesmente ENA. Em modelos de previsão para o preço de curto prazo no mercado de energia, essa variável assume importância fundamental. O Operador Nacional do Sistema Elétrico (ONS), inclusive, disponibiliza uma série histórica bastante consistente para a ENA. Nesse Comentário de Conjuntura, analisamos o comportamento da ENA, tendo como foco comparativo o ano de 2021 com a série histórica.
O script começa importando os dados para o RStudio como abaixo.
library(tidyverse)
library(lubridate)
library(fpp3)
data = read_csv2('ena.csv') %>%
mutate(date = yearmonth(parse_date_time(date, orders = "%d/%m/%Y %H-%M"))) %>%
as_tsibble(index = date)
Um primeiro gráfico com as séries é disponibilizado abaixo.
data %>% gather(variavel, valor, -date) %>% ggplot(aes(x=date, y=valor, colour=variavel))+ geom_line()+ facet_wrap(~variavel, scales='free')+ theme(legend.position = 'none', plot.title=element_text(size=9, face='bold'))+ labs(x='', y='', title='Energia Natural Afluente (MWmed)', caption='Fonte: analisemacro.com.br')
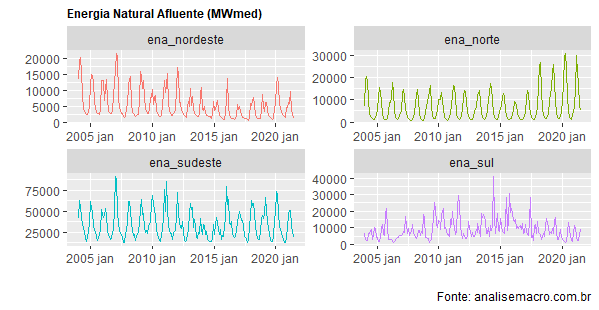
Observe, primeiro, que estamos vendo a ENA pelos quatro subsistemas: norte, nordeste, sul e sudeste/centro-oeste. Segundo, as séries apresentam uma sazonalidade bastante pronunciada. Por isso, é importante visualizar essa sazonalidade mais de perto. Isso é feito a seguir.
data %>% gather(variavel, valor, -date) %>% gg_season()+ facet_wrap(~variavel, scales='free')+ theme(legend.position = 'none', plot.title = element_text(size=9, face='bold'))+ labs(x='', y='', title='Sazonalidade da Energia Natural Afluente (MWmed)', caption='Fonte: analisemacro.com.br')
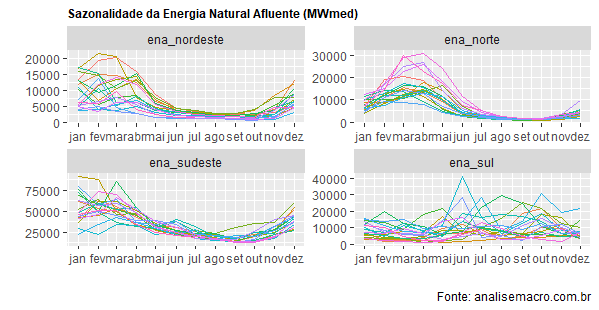
Os subsistemas nordeste, sudeste e norte apresentam uma sazonalidade bastante pronunciada, correlacionada ao início do período seco. Já o subsistema sul não tem uma tendência muito clara, a partir dessa visualização.
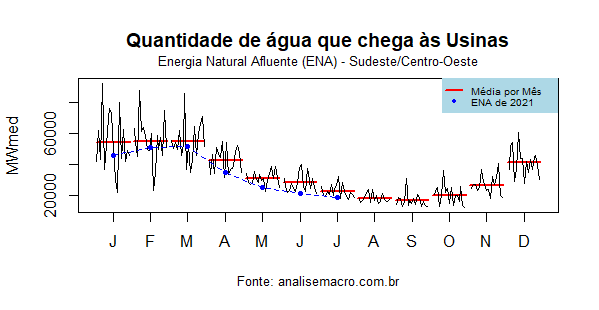
A seguir, nós comparamos a média histórica com o dado de 2021.
Para começar, nós olhamos para o subsistema sudeste/centro-oeste. As linhas vermelhas representam a média de ENA nos respectivos meses, enquanto a bolinha azul representa o ocorrido em 2021. Observa-se que 2021 está, de fato, abaixo da média histórica para o subsistema sudeste/centro-oeste.
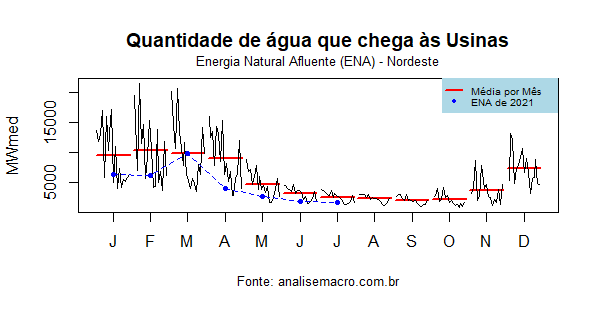
No subsistema nordeste, a situação é similar, à exceção do mês de março, onde a ENA ficou dentro da média histórica.
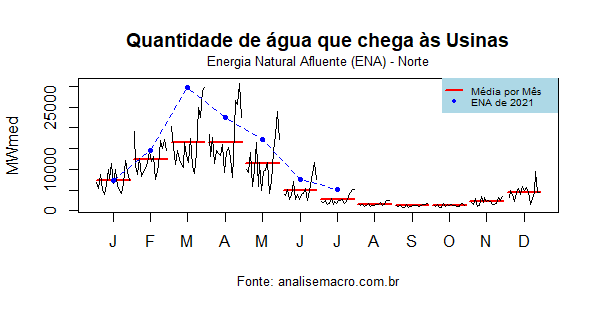
No susbsistema norte, a situação já é bastante confortável. As ocorrências de 2021 estão acima da média histórica.
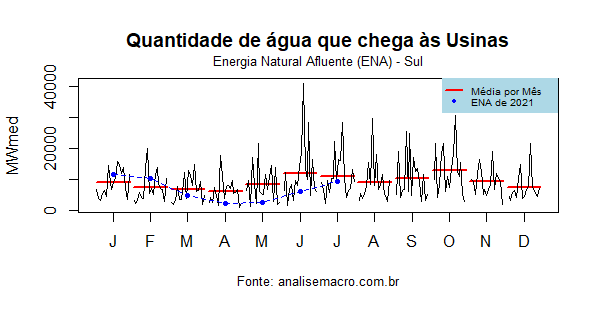
No subsistema sul, a vazão começou boa no início do ano, mas tem se mantido abaixo da média histórica a partir de março, o que também indica alguma preocupação.
A análise dos gráficos, de modo geral, gera preocupação. Em particular, o subsistema sudeste/centro-oeste, o principal do país, tem apresentado uma vazão abaixo da média histórica nos meses de 2021, o que gera o sinal de alerta para as autoridades responsáveis pela operação do sistema.
Menor vazão para as usinas hidrelétricas vai implicar, necessariamente, em maior acionamento das termelétricas, o que tem impacto direto no preço da energia elétrica para o consumidor, já que a água é, por definição, o insumo mais barato para a produção de energia.
________________
(*) O script completo desse exercício estará disponível no Clube AM essa semana.


