Ao longo do tempo a economia apresenta o que se chama de ciclos econômicos, ou seja, períodos de expansão e recessão. Mas de que forma podemos saber em qual ponto do ciclo econômico a economia se encontra? Como sabemos se a economia está em recessão? Estas são perguntas de grande interesse para acadêmicos e profissionais da área, e neste breve exercício demonstramos como replicar a datação de ciclos econômicos que instituições como NBER (EUA) e CODACE (Brasil) tradicionalmente publicam.
De maneira prática, neste exercício replicamos o algoritmo de Harding & Pagan (2002) para datar o ciclos de negócios do Produto Interno Bruto (PIB) brasileiro. Em resumo, o método considera algumas regras impostas ao comportamento de uma série temporal para classificar picos e vales. Recessão é o período entro o pico da atividade econômica e seu subsequente vale, ou ponto mínimo. Entre o vale e o pico, diz-se que a economia está em expansão.
O método é bastante simples e poderoso, conseguindo praticamente replicar a cronologia de recessões desenvolvidas pelas instituições mencionadas acima.
Pacotes
Para aplicar o algoritmo utilizaremos o pacote BCDating na linguagem R, criado por Majid Einian (Central Bank of Islamic Republic of Iran) e Franck Arnaud (National Institute of Statistics and Economic Studies, France). Outros pacotes são utilizados para coleta, tratamento e visualização de dados:
# Instalar/carregar pacotes
if(!require("pacman")) install.packages("pacman")
pacman::p_load(
"magrittr",
"BCDating",
"sidrar",
"dplyr",
"lubridate",
"timetk",
"zoo",
"ggplot2",
"ggthemes"
)
Dados
Neste exercício utilizaremos a série do PIB a preços de mercado (série encadeada do índice de volume trimestral com ajuste sazonal, média de 1995 = 100), disponível no SIDRA/IBGE. Para coletar os dados via API pode-se usar o pacote sidrar, especificando o código de coleta. Além disso realizamos a preparação dos dados para utilização posterior:
# Coleta e tratamento de dados
pib <- sidrar::get_sidra(api = "/t/1621/n1/all/v/all/p/all/c11255/90707/d/v584%202") %>%
dplyr::select("date" = `Trimestre (Código)`, "value" = `Valor`) %>%
dplyr::mutate(value = value, date = lubridate::yq(date)) %>%
dplyr::as_tibble()
Algoritmo de Harding & Pagan (2002)
Para aplicar o algoritmo e obter as datações de ciclo de negócios, primeiro transformamos o objeto pro formato de série temporal e, em seguida, utilizamos a função BBQ() do pacote BCDating. Optamos por deixar com os valores predefinidos os demais argumentos da função, que servem para definir os valores mínimos de duração do ciclo (pico ao pico ou vale ao vale) e da fase do ciclo (pico ao vale ou vale ao pico).
# Obter datação de ciclo de negócios bc_dates <- pib %>% timetk::tk_ts(select = value, start = c(1996, 1), frequency = 4) %>% BCDating::BBQ(name = "Ciclo de Negócios do PIB do Brasil")
Resultados
Como pode ser visto abaixo, o objeto retornado traz como resultado as datas (trimestres) de picos e vales, assim como a duração do ciclo.
# Exibir resultados show(bc_dates) ## Peaks Troughs Duration ## 1 2001Q1 2001Q4 3 ## 2 2002Q4 2003Q2 2 ## 3 2008Q3 2009Q1 2 ## 4 2014Q1 2016Q4 11 ## 5 2019Q4 2020Q2 2
Outras informações podem ser obtidas com a função summary(), porém o mais interessante é avaliar o resultado visualmente através de um gráfico. Para tal, fazemos um tratamento dos dados retornados pela função BBQ() e utilizamos o ggplot2 para gerar o gráfico com as áreas sombreadas referente às datas de recessão que foram identificadas pelo algoritmo, acompanhadas do comportamento do PIB no período:
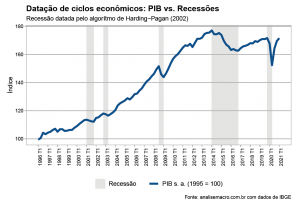
Comparação com cronologia do CODACE/FGV
Por fim, vamos comparar os resultados aqui encontrados com a Cronologia de Ciclos de Negócios Brasileiros elaborada pelo Comitê de Datação de Ciclos Econômicos (CODACE). A última reunião do comitê foi em 29 de junho de 2020, na qual reportou a seguinte situação do ciclo de negócios:
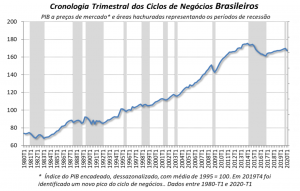
Percebe-se que a série utilizada pelo comitê inicia-se em 1980, mas se analisarmos a partir de 1996 (período de início da série utilizada em nosso exercício), verificamos que 5 de 6 recessões datadas pelo CODACE são identificadas pelo algoritmo de Harding & Pagan (2002). Apenas a recessão do 1º trimestre de 1998 ao 1º trimestre de 1999 não foi detectada. Apesar disso, o resultado é empolgante!
Por fim, vamos comparar os resultados de ambas as datações mais a fundo na tabela a seguir, na qual contabilizamos o período de recessão partindo do trimestre imediatamente posterior ao pico até o subsequente vale:
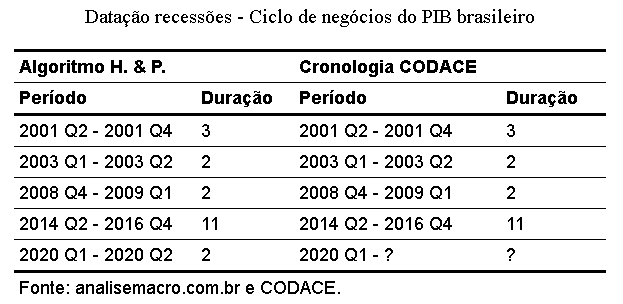
Perceba que ambas as datações são idênticas! A única diferença está na última datação, a qual o CODACE ainda não definiu o próximo vale. Dessa forma, fica demonstrado o poder e facilidade de uso do algoritmo de Harding & Pagan para datação de ciclos econômicos.
________________________
(*) Para entender mais sobre ciclos econômicos e modelos macroeconômicos, confira nossos Cursos de Macroeconomia Aplicada.

