Os microdados da Pesquisa Nacional por Amostra de Domicílios Contínua (PNADC), produzida pelo IBGE, possuem uma riqueza enorme de informação de um conjunto de indicadores relacionados à força de trabalho no país, constituindo um verdadeiro tesouro para economistas e cientistas sociais. Esse grande volume de dados exige, por consequência, o uso de ferramentas adequadas para o tratamento, análise, visualização e sua utilização em geral. Em suma, é necessário utilizar linguagens de programação para "colocar a mão" nesses dados e, neste exercício, mostraremos como fazer isso usando o R.
Para reproduzir o exercício a seguir você precisará dos seguintes pacotes:
library(PNADcIBGE) # CRAN v0.7.0 library(survey) # CRAN v4.0 library(convey) # CRAN v0.2.3 library(magrittr) # CRAN v2.0.1
1) Importar microdados trimestrais
Para começar o exercício, vamos importar os microdados para o environment do R usando o pacote PNADcIBGE - que foi desenvolvido pela própria equipe do IBGE. Os microdados trimestrais serão o alvo do nosso exemplo: apontamos na função get_pnadc o último período (ano/trimestre) disponível da pesquisa e, opcionalmente, as variáveis de interesse1.
# Importar online microdados do 3º trimestre de 2021
dados_pnadc <- get_pnadc(year = 2021, quarter = 3, vars = c("VD4020", "V2007"))
# Classe do objeto
class(dados_pnadc) # útil para análises de dados amostrais complexos
[1] "svyrep.design"
2) Análise de dados
Após este simples comando de importação executado, os microdados da PNADC já estão disponíveis para fazermos uma análise. A função, inclusive, já configura o plano amostral internamente através do argumento design = TRUE - mas o usuário pode desabilitar para obter os dados brutos -, sendo assim podemos usar o pacote survey para obter, por exemplo, o total de homens e mulheres:
# Obter nº total de homens e mulheres svytotal(x = ~V2007, design = dados_pnadc, na.rm = TRUE) # total SE # V2007Homem 104020393 0.1207 # V2007Mulher 108787836 0.0998
Da mesma forma, e com comandos simples, o usuário pode estimar o índice de Gini a nível nacional:
# Estimar o índice de Gini dados_pnadc %>% convey_prep() %>% svygini(formula = ~VD4020, na.rm = TRUE) # gini SE # VD4020 0.51625 0.0034
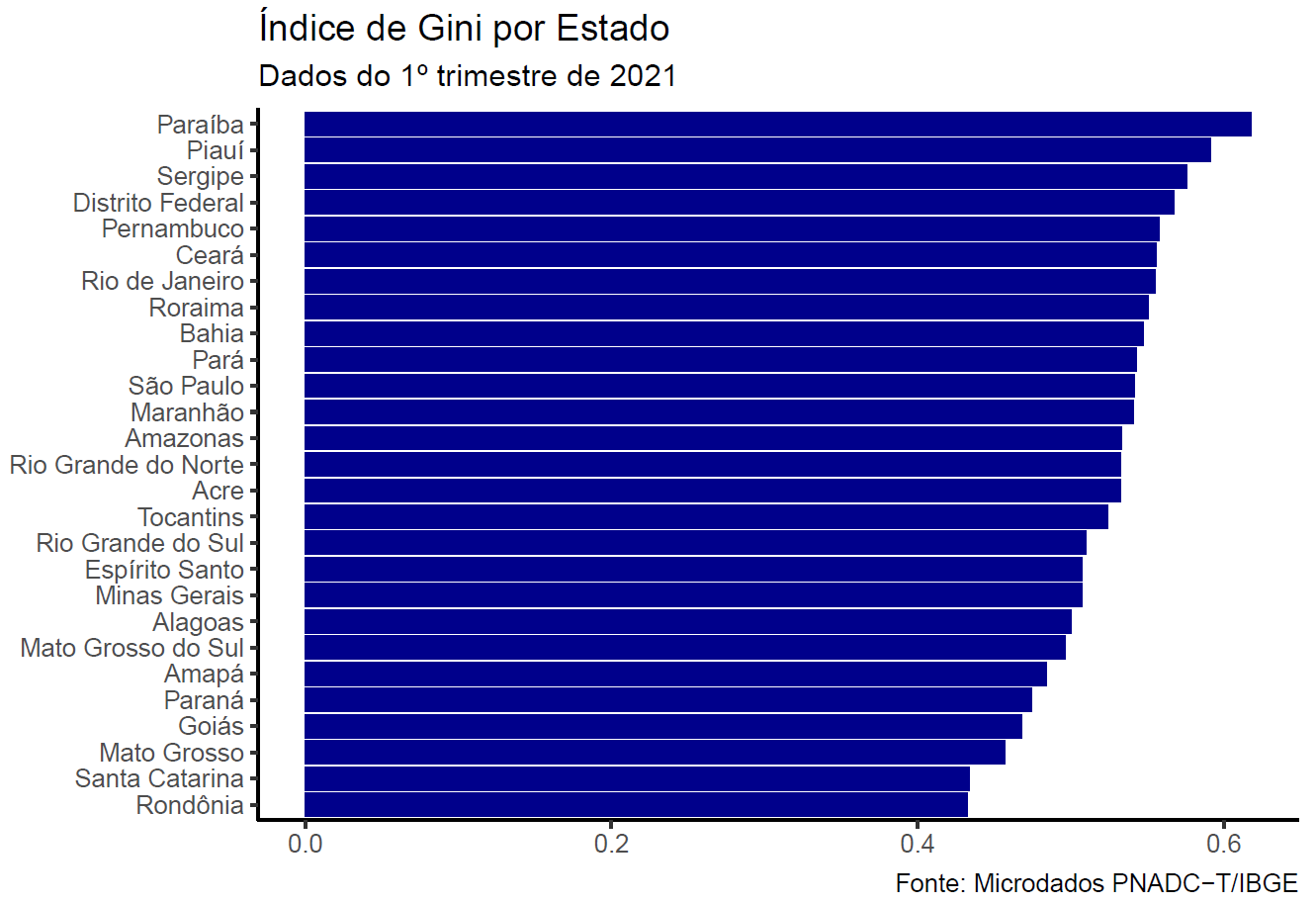
Diversas outras análise podem ser feitas, como esta publicada no blog da Análise Macro:
Saiba mais
Para saber mais confira os cursos aplicados de R e Python.

[1] Note que os microdados consomem espaço excepcionalmente grande na memória do computador, portanto, evite a importação sem nenhum tipo de filtro de variáveis.

