A inflação cheia medida pelo IPCA em um período  qualquer nada mais é do que a soma da contribuição da inflação em cada um dos seus nove grupos, de acordo com os pesos dos mesmos no índice. Em outros termos,
qualquer nada mais é do que a soma da contribuição da inflação em cada um dos seus nove grupos, de acordo com os pesos dos mesmos no índice. Em outros termos,
(1) 
onde  é a inflação cheia,
é a inflação cheia,  é a inflação em no grupo
é a inflação em no grupo  e
e  é o peso em do grupo no índice cheio. De modo a ilustrar, podemos baixar com o pacote sidrar, as variações e os pesos desses nove grupos do IPCA, conforme o código abaixo.
é o peso em do grupo no índice cheio. De modo a ilustrar, podemos baixar com o pacote sidrar, as variações e os pesos desses nove grupos do IPCA, conforme o código abaixo.
## Pacotes
library(sidrar)
library(ggplot2)
library(forecast)
library(timetk)
library(zoo)
library(scales)
library(tidyverse)
## Baixar e tratar os dados
tab1 = get_sidra(api='/t/2938/n1/all/v/63,66/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202,v66%204')
tab2 = get_sidra(api='/t/1419/n1/all/v/63,66/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202,v66%204')
tab3 = get_sidra(api='/t/7060/n1/all/v/63,66/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202,v66%204')
series = c(7170, 7445, 7486, 7558, 7625, 7660,
7712, 7766, 7786)
names = c('Alimentos', 'Habitação', 'Art de Resid',
'Vestuário', 'Transporte', 'Saúde e cuid pessoais',
'Despesas Pessoas', 'Educação', 'Comunicação')
var1 <- matrix(NA, ncol=length(series),
nrow=nrow(tab1)/length(series)/2)
peso1 <- matrix(NA, ncol=length(series),
nrow=nrow(tab1)/length(series)/2)
var2 <- matrix(NA, ncol=length(series),
nrow=nrow(tab2)/length(series)/2)
peso2 <- matrix(NA, ncol=length(series),
nrow=nrow(tab2)/length(series)/2)
var3 <- matrix(NA, ncol=length(series),
nrow=nrow(tab3)/length(series)/2)
peso3 <- matrix(NA, ncol=length(series),
nrow=nrow(tab3)/length(series)/2)
for(i in 1:length(series)){
var1[,i] <- tab1 `Variável (Código)`==63&
tab1
`Variável (Código)`==63&
tab1![`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]] var2[,i] <- tab2](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%20467%2041'%3E%3C/svg%3E "Rendered by QuickLaTeX.com") Valor[tab2
Valor[tab2 `Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
var3[,i] <- tab3
`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
var3[,i] <- tab3 `Variável (Código)`==63&
tab3Valor[tab1`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
peso2[,i] <- tab2`Variável (Código)`==66&
tab2Valor[tab3
`Variável (Código)`==63&
tab3Valor[tab1`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
peso2[,i] <- tab2`Variável (Código)`==66&
tab2Valor[tab3 `Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
}
variacao = ts(rbind(var1, var2, var3), start=c(2006,07), freq=12)
peso = ts(rbind(peso1, peso2, peso3), start=c(2006,07), freq=12)
`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
}
variacao = ts(rbind(var1, var2, var3), start=c(2006,07), freq=12)
peso = ts(rbind(peso1, peso2, peso3), start=c(2006,07), freq=12)
 `Variável (Código)`==63&
tab1
`Variável (Código)`==63&
tab1![`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]] var2[,i] <- tab2](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-937b2a026d18a085b6c0dffcc635662c_l3.png "Rendered by QuickLaTeX.com") Valor[tab2
Valor[tab2 `Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
var3[,i] <- tab3
`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
var3[,i] <- tab3 `Variável (Código)`==63&
tab3
`Variável (Código)`==63&
tab3![`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]] peso1[,i] <- tab1](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-5919cd4ca051a1103d31f192b8b4e713_l3.png "Rendered by QuickLaTeX.com") Valor[tab1
Valor[tab1 `Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
peso2[,i] <- tab2
`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
peso2[,i] <- tab2 `Variável (Código)`==66&
tab2
`Variável (Código)`==66&
tab2![`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]] peso3[,i] <- tab3](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-3d53744b7531451d06f3f086b53d4162_l3.png "Rendered by QuickLaTeX.com") Valor[tab3
Valor[tab3 `Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
}
variacao = ts(rbind(var1, var2, var3), start=c(2006,07), freq=12)
peso = ts(rbind(peso1, peso2, peso3), start=c(2006,07), freq=12)
`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
}
variacao = ts(rbind(var1, var2, var3), start=c(2006,07), freq=12)
peso = ts(rbind(peso1, peso2, peso3), start=c(2006,07), freq=12)
Assim, a inflação medida pelo IPCA nada mais será do que a variação vezes o respectivo peso do grupo. Com isso em mente, nós podemos gerar a previsão para cada grupo e depois recuperar a previsão da inflação cheia a partir dessas previsões individuais. O resultado é exposto no gráfico abaixo.
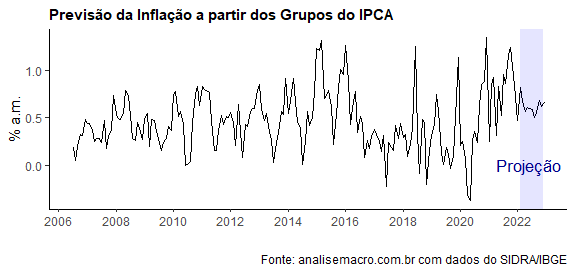
A previsão para a inflação em janeiro, por essa metodologia, é de 0,47%.
________________
(*) Para aprender a fazer esse tipo de projeção, veja nossos cursos de Previsão Macroeconométrica e Modelos Preditivos aplicados à Macroeconomia.
(**) Os códigos completos do exercício estão disponíveis no Clube AM.

