A biblioteca pandas pode ser considerada a mais importante dentro do mundo da análise de dados para o Python. É a ferramenta principal para construção de estrutura, manipulação e limpeza de dados, sendo também utilizada com bibliotecas de processamento numérico e construção de gráficos. No post de hoje, iremos realizar uma breve introdução a esta biblioteca.
O ponto chave do pandas está na estrutura de dados no qual a biblioteca permite criar e manipular, são elas: Series e DataFrame.
Series é um objeto array unidimensional (tal qual o array criado com o Numpy) possuindo um índice (rótulos das observações). O DataFrame é considerado como um conjunto de dados retangulares ou dados tabulares, no qual cada coluna tem um tipo de dado, representados por um índice de colunas e um índice para cada observação (linha).
Para importar a biblioteca, iremos utilizar a seguinte convenção:
import pandas as pd
Series
Como dito, o objeto Series é um array unidimensional associado a um rótulo de dados chamado índice (ou index). Podemos criar uma Series a partir do seguinte código.
series_obj = pd.Series([4, 5, 6, 3]) series_obj

Veja que para cada valor há um número representando a ordem das observações. É possível criar os valores dos índice.
series_obj2= pd.Series([4, 7, 8, -2], index = ['a', 'b', 'c', 'd']) series_obj2

Assim como um array do Numpy, é possível realizar cálculos com o objeto séries, seja através de funções, multiplicação escalar ou mesmo filtragens. A ordem do índice não se altera. Veja também que pela filtragem é possível escolher através do rótulo da observação.
# Calcula a média da Series series_obj2.mean() # Multiplica a array por 2 series_obj2 * 2 # Seleciona o valor no qual o índice é representado por 'a' series_obj2['a']
DataFrame
Como dissemos, o DataFrame representa uma tabela de dados retangulares contendo uma coleção de colunas, preenchidas de uma série de observações, sejam elas numéricas, strings, booleans, etc. Possui também dois índices, sendo uma para as observações e outra para as colunas. Podemos dizer que é uma coleção de lista, dicionários ou arrays unidimensionais.
Vamos construir um DataFrame a partir de um conjunto de dicionários.
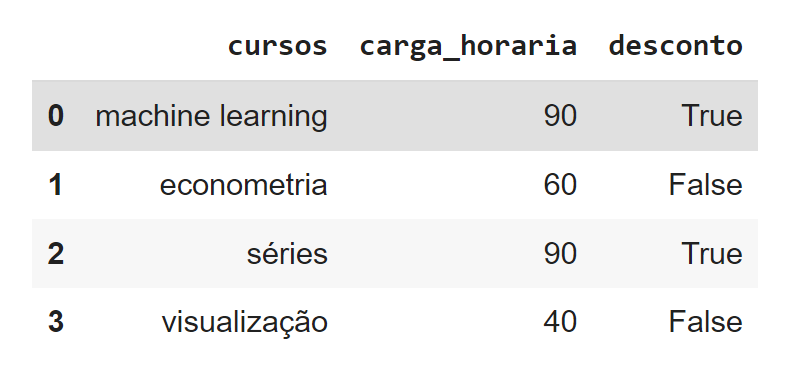
data_raw = {'cursos' : ['machine learning', 'econometria', 'séries', 'visualização'],
'carga_horaria' : [90, 60, 90, 40],
'desconto' : [True, False, True, False]}
data = pd.DataFrame(data_raw)
data
É possível também, a partir do pandas, importar dados de outros lugares. O mais comum é importar arquivos .csv. Vemos um exemplo abaixo, importando um dataset de treino de um conjunto de dados sobre preços de casas na Califórnia contidos no Google Colab.
california_houses = pd.read_csv('/content/sample_data/california_housing_train.csv')
Quando recebemos esse conjunto de dados, o interessante é explorá-lo para obter uma noção de seu conteúdo. Podemos utilizar diversos métodos para isso.
# Retorna as primeiras linhas do DataFrame california_houses.head()

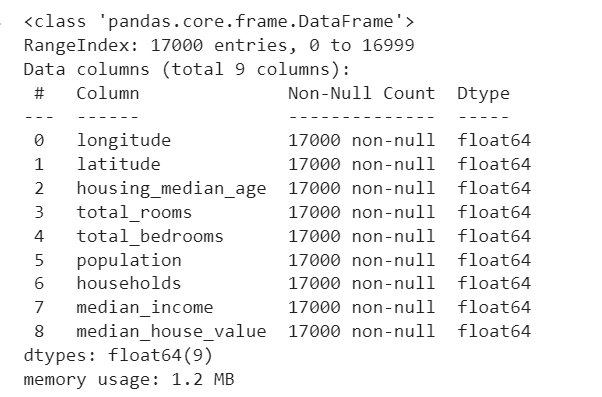
# Exibe as informações sobre o DataFrame california_houses.info()

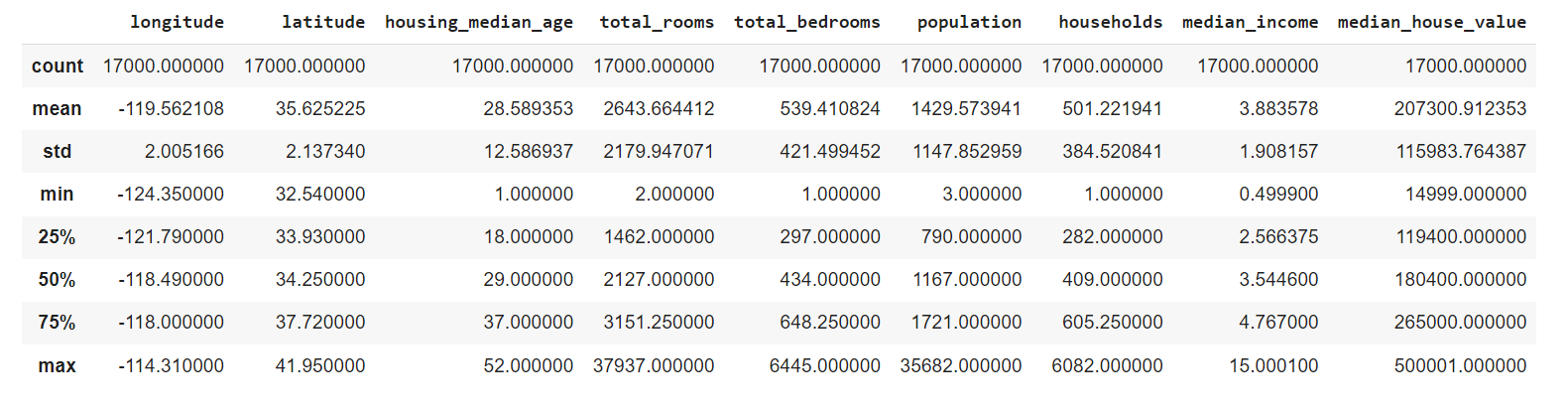
# Sumariza as estatísticas california_houses.describe()

# Retira as colunas california_houses.columns

# Números dos índices california_houses.index

Nesse post realizamos uma breve introdução aos pandas, há ainda uma série de outras possibilidades de manipulação e cálculos que podemos realizar, tais como filtragens mais avançadas dos DataFrames, agregação e junção com condições, além de aprender métodos para preparar um Dataframe para visualização e modelagem.
Como analogia, podemos dizer que a biblioteca pandas pode ser considerada como um canivete suíço, com uma variedade de ferramentas, ficando a cargo do usuário qual utilizar, podendo em muitas vezes ser vasto o tempo necessário de aprendizagem. Apesar disso, os cursos da Análise Macro facilitam este problema, com uma série de aulas teóricas e práticas com o Python, facilitando a vida de quem quer aprender mais sobre Análise de Dados.

