O comando CASE do SQL permite substituir observações com base em uma condição, por exemplo, a categorização de valores numéricos, ou seja, transformar os intervalos de números em valores categóricos. Vamos entender melhor sobre essa instrução no post de hoje.
Vamos utilizar o dataset weather_stations. Na coluna wind_speed, temos a velocidade do vento reportada em valores numéricos e queremos transformar estes valores em categorias. Mas como?
No comando acima, selecionamos as colunas e utilizamos CASE para criar uma série de linhas com as condições. As condições são criadas com os comandos WHEN, THEN e ELSE.
Podemos ler a segunda linha como: caso sos valores da coluna wind_speed sejam maiores ou iguais a 40, então serão substituídos pela palavra ‘HIGH’.
E assim continuamos na terceira linha: caso os valores da coluna wind_speed sejam maiores ou iguais que 30 E (AND) menores que 40, então serão substituídos por ‘MODERATE’.
Se nenhuma das condições forem satisfeitas, então (ELSE) substituiremos pela palavra ‘LOW’.
E para fechar a instrução CASE utilizamos END renomeando a coluna com AS.
Toda a condição é feita de baixo para cima, ou seja, primeiro todos os valores maiores ou iguais a 40 serão substituídos, e então a próxima condição é iniciada.
É importante saber dessa questão, pois dessa forma podemos alterar os código retirando o comando AND da quarta linha.
Agrupando a instrução CASE
A partir dos valores criados pelas condições, é possível realizar cálculos agrupando-as
Truque do “Zero/Null”
Com o CASE, podemos agregar os dados com diferentes filtros em uma só consulta. Se utilizarmos apenas WHERE, teríamos que realizar duas consultas diferentes. Vejamos:
Precipitação com tornado
Precipitação sem tornado
Agora com CASE:
Podemos utilizar outras funções como MAX ou MIN e utilizar a condição com NULL ao invés de 0 para certificar que nenhum valor será garantido
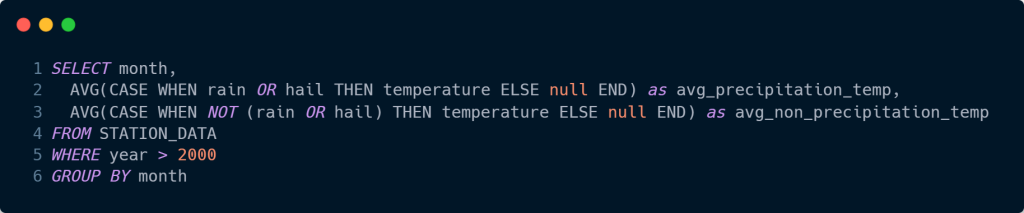
Da mesma forma que o comando WHERE, é possível utilizar uma expressão Boolean em uma instrução CASE, incluindo funções e AND, OR e NOT.
Vamos analisar abaixo a temperatura média por mês quando rain/hail (chuva e granizo) estiveram presentes após os ano de 2000.
____________________________________________________
Quer aprender mais?
Veja nosso curso de SQL para Economia e Finanças, onde ensinamos todo o processo para aqueles que desejam entrar na área. O curso faz parte da trilha Ciência de Dados para Economia e Finanças.
_________________________________________
Referências
Nield, Thomas. Getting Started with SQL: A Hands-On Approach for Beginners. O'Reilly Media, Inc., 2016.

