Dando continuidade aos exercícios temáticos sobre text mining, hoje avaliamos o poder preditivo de um indicador de sentimentos construído quantitativamente com base nos textos das atas do COPOM. Usando a linguagem R, performamos o teste de causalidade de Granger e analisamos a correlação do indicador com as variáveis macroeconômicas do boletim Focus.
Na macroeconomia, frequentemente não faz sentido analisar uma variável de maneira isolada. Não é à toa que a taxa de juros, por exemplo, sofre alterações constantes no Brasil: há diversos fatores em jogo, sobre os quais a autoridade monetária, feitora das mudanças na taxa de juros básica, tenta monitorar e influenciar, visando chegar ao que se chama de "equilíbrio". Alguns desses fatores podem ser outras variáveis agregadas da economia, como a taxa de câmbio e a inflação, e outros fatores podem ser não observáveis, como o hiato do PIB e a taxa de juros neutra.
Nesse sentido, usamos previamente um pequeno fragmento do grande arcabouço da atuação da autoridade monetária brasileira (BCB), que são os comunicados de decisões sobre a taxa de juros Selic, para tentar sumarizar quantitativamente o que chamamos de "sentimento" implícito nestes comunicados. Como resultado, obtivemos um Indicador de Sentimentos (IS), sobre o qual já destacamos as principais vantagens e desvantagens (veja o 1º e 2º exercícios dessa sequência). Com esse progresso, no sentido de extrair informação de dados textuais brutos, agora é hora de abandonar a análise isolada e investigar a relação do IS com algumas variáveis macroeconômicas do nosso dia a dia.
Análise bivariada
Focaremos em análises simples e clássicas, que abrem caminho para estudos mais aprofundados. São elas:
- A correlação de Pearson, que é útil para verificar a relação entre pares de variáveis. O cálculo gera um valor entre -1 e 1, onde o sinal indica a direção da relação (positiva ou negativa) e o valor indica a força da relação (quanto mais próximo de |1| mais forte é a correlação; zero seria ausência de correlação).
- O teste de causalidade no sentido de Granger, que serve para verificar se uma série temporal é útil em termos de previsão de outra série temporal (interprete "causalidade" como "precedência temporal"). O procedimento é feito através de regressões lineares e usamos testes de hipóteses para decidir se uma série X precede outra série Y, considerando defasagens.
Aplicamos essas análises com o IS, exposto previamente, pareando com as 4 principais variáveis do boletim Focus:
- IPCA (variação % 12 meses)
- PIB (variação % ano anterior)
- Dólar (PTAX venda, média mensal, R$/US$)
- Selic (% a.a., meta fim de período)
Esperamos, conforme deve ser razoável para a maioria das pessoas, que o IS seja negativamente correlacionado com o IPCA, Dólar e Selic (essas variáveis subindo → sentimento caindo/negativo) e, pelo contrário, positivamente correlacionado com o PIB. Isso desconsiderando efeitos defasados, como é comum na macroeconomia.
Correlação
A figura a seguir mostra os resultados da análise de correlação, usando o método de Pearson (PIB omitido, por economia de espaço).
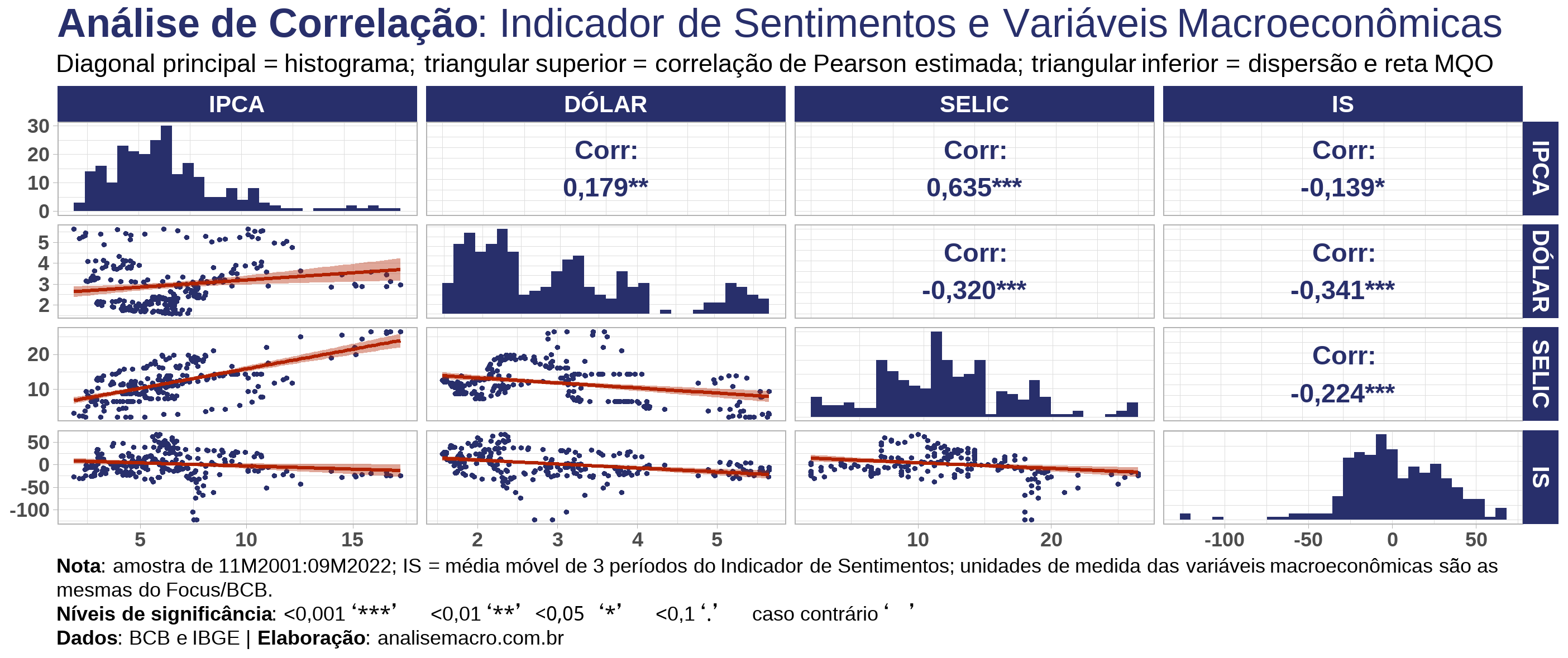
Você deve ler o gráfico assim: no canto superior direito (triangular superior) são apresentados os valores estimados da correlação de Pearson, assim como seu nível de significância; na diagonal do canto superior esquerdo até o canto inferior direito são apresentadas as distribuições de cada variável através de um histograma; por fim, no canto inferior direito (triangular inferior) são apresentadas as relações entre as variáveis através de um gráfico de pontos (dispersão) e uma reta de "ajuste ótimo", através de regressão linear simples, para visualizar a direção da relação.
Como resultado, verifica-se correlações conforme o esperado, em termos de sinal, entre os pares de variáveis em análise, apesar de não haver correlações fortes. O destaque mais expressivo fica para o dólar, com correlação negativa de 0,341, e a correlação mais fraca com o IS é a do PIB, omitida no gráfico, cujo valor foi de 0,138 (não significativo).
Isso adiciona pontos de vantagem para o IS, haja visto que ele parece estar captando bem o sentimento dos diretores do COPOM, implícito nas atas, quando estes estão olhando para os dados macroeconômicos. Um exercício interessante seria avaliar se essas relações se mantêm para outros momentos, ou seja, analisando correlações defasadas entre as variáveis.
Precedência temporal
Avançando para a segunda análise, a tabela a seguir apresenta os resultados do teste de causalidade de Granger.
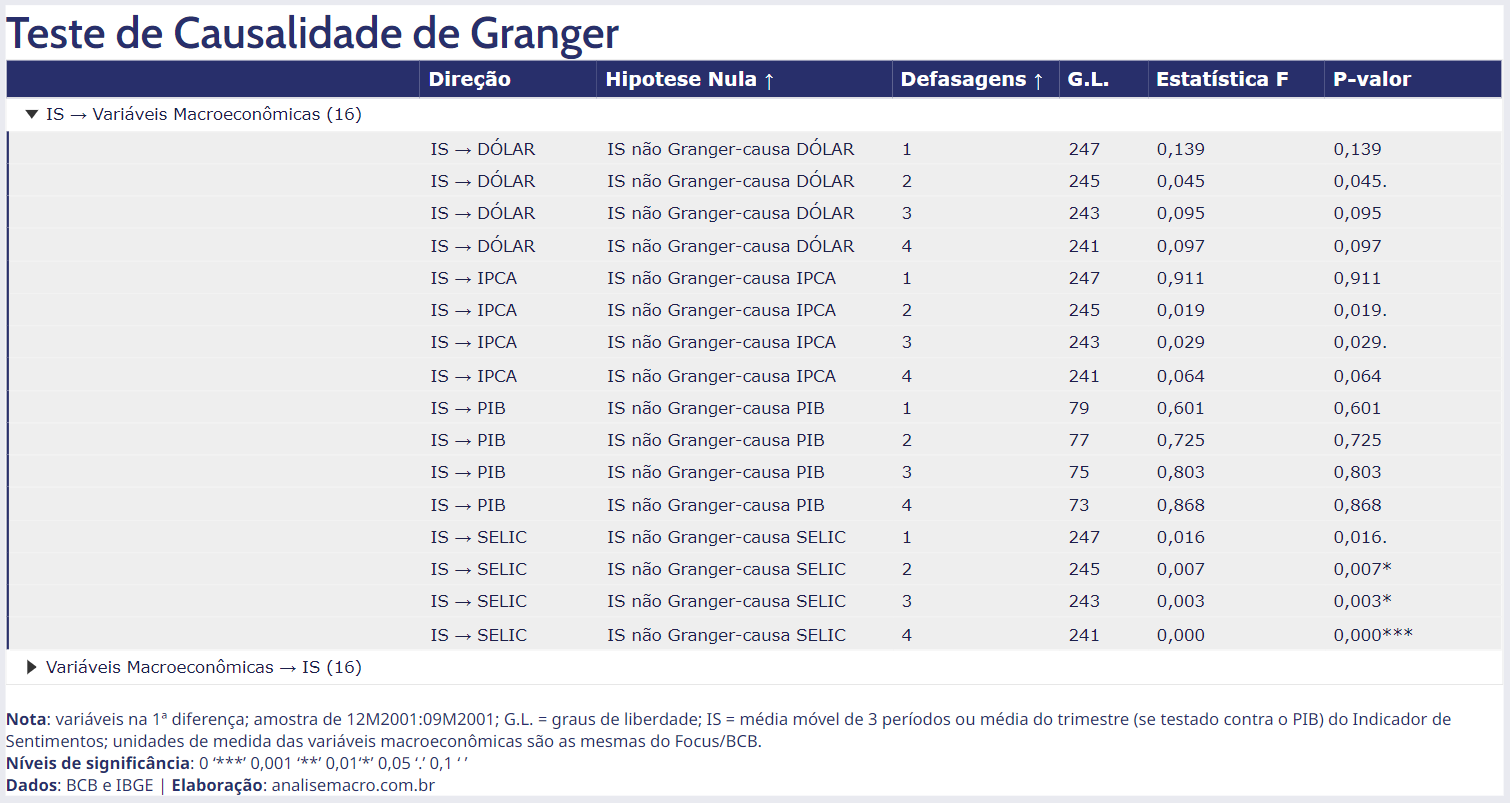
O teste é usualmente aplicado nas duas direções, para averiguar se a causalidade de Granger está presente tanto de X para Y quanto de Y para X, o que poderia ser um resultado inconclusivo. Além disso, aplicamos o teste com várias especificações (defasagens), visando a transparência dos procedimentos econométricos e verificar se os resultados são consistentes entre especificações. Precauções sobre estacionariedade das variáveis são tomadas previamente à aplicação do teste.
Os resultados do teste são promissores: verifica-se que o IS precede temporalmente a maioria das variáveis macroeconômicas consideradas na análise, ao menos a partir da segunda defasagem e considerando um nível de significância de 10%. Na direção contrária essa precedência temporal não se verifica, ou seja, o resultado parece ser consistente. A exceção é o PIB, que não precede e nem é precedido temporalmente pelo IS (esse resultado é coerente com a análise de correlação, que apontou um valor não significativo).
Saiba mais
Os resultados dessas análises formam a base para outros estudos sobre text mining e macroeconomia, que continuaremos no próximo exercício dessa série (próxima sexta). Se o tema despertou teu interesse, confira os cursos aplicados da Análise Macro.
Códigos de replicação, na linguagem R, estão disponíveis para membros do Clube AM.

